[转]咖啡鱼版CSS教程——十步学会CSS
本站文章已轉移,敬請移步:http://www.xxb.me/ ,謝謝!
本教程并没有像普通的教程一样着重介绍各种属性,相反基本上一点都没提及,因为用到属性的时候我们可以查询CSS2中文手册。本教程着重介绍了CSS中的各种模型和概念,它们是CSS的灵魂。适合入门者,大虾可略过,欢迎批评指正。
1.CSS的产生
2.简单的Html语法
3.CSS语法和应用
4.ID和类
5.常用的选择器
6.继承、层叠和特殊性
7.标准框模型和IE非标准框模型
8.空白边的叠加
9.相对定位和绝对定位
10.浮动和清理
大虾请略过,欢迎批评指正。本人菜鸟。
话说盘古开天那会,嗯,还没有网络,再后来出现了网络,一种简单的容易理解的语言——HTML出现了。或许现在的网页都很漂亮,但用最原始的有语义的HTML形成的网页只能用简陋来形容。
再后来,网页变得越来越复杂,直到很少有人能再看懂自己写的代码。那个时代,Html的最重要的作用变成表现页面的一种方式,那么当时是怎么来修饰页面的呢?
人们用块引用(Blockquote)来添加空白而不是表示引用;表格完全成了布局工具,而不是来显示数据;用字体和粗体标签的组合来创建所需的视觉效果,而不只是用标题元素突出显示页面标题。总之,Html这种原本为非表现性语言变成了多能的,后果就是谁也理不清那一堆乱乱的代码。
这时人们急需一种独立的,细化的,简单的,易实现的表现性语言,来独立于Html之外表现页面。CSS出现了。
CSS全称为Cascading Style Sheets,翻译过来为层叠样式表,一般称样式表。它是Html的一种扩展语言。
那么我们可以用CSS来做什么呢?
有了CSS,我们就可以控制网页外观并且将文档的表现部分与内容分离开来。例如我们可以用CSS直接控制布局,而不是没有语义的表格。总之,CSS让以前复杂难懂的Html变得简单,有意义。
CSS 的语法是非常简单的,但CSS在大多数人眼里是难掌握的。这并不是CSS本身的错,而是浏览器Bug和不一致的显示方式导致的。像我们最常用的IE就是最令设计人员头痛的一个非常糟的浏览器。我们日常使用一般都要尽量避免这些因浏览器而导致的BUG。比如最常见的一种就是网页在Firefox下显示正常,而在IE下,侧边栏却被“挤”到了下面,这就是由于IE错误的不符合标准的框模型造成的。当然,也存在一些修复Bug的方法(一般称Hack),但并不推 荐。当你在不同浏览器上测试代码时,你的设计可能在一种浏览器上显示的很好,但在另一浏览器上布局可能会支离破碎。不要惊讶,这是一个现实的世界,并不完美。可以尽量找一些修复的方法。
现在用的CSS标准一般为2.1。
第一次写系列教程,肯定有好多好多疏漏和错误,以后发现了会逐步完善,欢迎指正哦。以后尽量先写到纸上,这样思考的会细一些。这也是本人的一个深入学习的机会。记住:我也是菜鸟哦,比你知道的多不了多少。
在此系列教程中,我主要是根据自己的学习经历和经验,以最通俗的语言及例子说明一些抽象的概念,相信即使你从来没有接触过Html或CSS都可以学会。另外本教程所介绍的也是最基本的概念及最常用到的知识。
我接触Html也是从Blogger开始的,以前的Blogger模板是纯Html格式的。相信好多朋友连最基本的Html标记都不清楚,在学CSS之前,我将介绍我们最常用到的一些Html标记。算是CSS的基础。
1.Html简介
HTML的英文全称是Hyper Text MarkUp Language,中文叫做“超文本标记语言”。
HTML文件看上去和一般文本类似,但是它比一般文本多了Tag(标记),比如<html>,<b>等,通过这些Tag,可以告诉浏览器如何显示这个文件。我们用记事本就可以编辑Html。
我们平常浏览网页是通过IE,Firefox此类的浏览器,为什么需要浏览器呢?浏览器是一种翻译工具,它会解释看起来复杂、凌乱的Html,让人们得到最直观的表现方式。先介绍一下Html的几个基本概念:(1)标记(Tag),有的地方也称作标签。标记在Html中是用于描述功能的符号。标记是用来实现某种功能的,标记必须用<>括起来.举个例子吧.
在上面的一行代码中,<B>和</B>就是标记,那么它们可以实现什么功能呢?这两个标记只有一个差别,就是后面的标记多了一个 "/",这个标记的功能就是让两个标记中间的文字加粗显示.我们会注意到在浏览器中标记是不会显示的,显示出来的是它们之间的内容.所以我们可以看出,标记在这儿就起了某种功能的作用,标记指出了处于它们之间的内容在浏览器中的表现方式.
标记一般都有一个“始标记”和一个“尾标记”,像上面 例子中<B>就是始标记,带上一个斜线就变成了尾标记。那么为什么需要两个标记呢?只用一个不行吗?其中始标记告诉浏览器从此处开始标记所表示的功能,而尾标记则告诉浏览器到这里该功能结束。相信这是很容易理解的。当然也有一些单标记,比如最常用的单标记<BR>,它用来表示换行。
新版的Blogger用的是XML,它对标记的检查非常严格,一般标记必须含有结束标记,有时候我们修改了代码却无法保存,或许就是漏了结束标记。
(2)属性。HTML元素可以拥有属性。属性可以扩展HTML元素的能力。
比如你可以使用一个bgcolor属性,使得页面的背景色成为红色,就像这样:
(3)注释语句。注释语句的格式为:<!--注释文-->
2.Html的基本结构
浏览器在解释Html的时候会由上而下执行,像流水一样,这就是以后我们会接触Html的一个“流”的概念,尽管简单,却是基础。
上面的Html基本结构的第一个Tag是<html>,这个Tag告诉你的浏览器这是HTML文件的头。文件的最后一个Tag是</html>,表示HTML文件到此结束。
在<head>和</head>之间的内容,是Head信息。Head信息是不显示出来的,你在浏览器里看不到。但是这并不表示这些信息没有用处。Head信息是预加载的一些信息,比如CSS以及JS就可以放在Head里。
在<title>和</title>之间的内容,是这个文件的标题。你可以在浏览器最顶端的标题栏看到这个标题。
在<body>和</body>之间的信息,是正文。
在<b>和</b>之间的文字,用粗体表示。<b>顾名思义,就是bold的意思。
3.本节最重要的内容,介绍常用的标记。大多数将会在使用的时候简单介绍。Html标记是CSS的样式附着的地方,是“钩子”。
h1,h2等
ul li等
div span p等
这一节我们终于真正的开始接触CSS本身了,会不会等得有点久呢?呵呵,开始吧。
一、基本语法
掌握一件事物最快的方法就是直接去使用,看看下面一段代码,这段代码来自Blogger模板。它是介于<b:skin><![CDATA [ 和 ]]></b:skin>之间的部分。这部分包含了XML的变量定义(Variable definitions)和CSS。类似下面的代码就是CSS。
background:$bgcolor;
margin:0;
color:$textcolor;
font:x-small Georgia Serif;
text-align: center;
}
仔细观察上面的代码,我们可以分析出CSS的规则,实际上CSS只包含了三部分,大括号外的,冒号前面的,最后就是冒号后面的。这三部分是什么?起什么作用呢?
我们用一条更简单的规则来说明:
这里有三个概念,分别是大括号外的“选择符(Selector)”、冒号前的“属性(Property)”以及冒号后面的“属性的值”或者说是“属性的参数”。
上面一条代码具有什么作用呢?它告诉浏览器将所有<H1></H1>包围的文字以绿色显示。
1. 选择符(有的地方称作选择器)。上面代码中的H1。顾名思义,它的作用就是起筛选的作用。就像上一条代码,它只对所有<H1></H1>包围的文字起作用。所有的Html标记都可以充当选择符,所以你可以将CSS的任何信息应用到任何元素。如果有不同的选择符,但他们的属性及值是完全一样的,为了方便,我们可以将它们合并起来写,例如:
{ font-family: arial;}
上面的代码就会把所有的H1,P,Span包围起来的文字的字体设置为Arial。
2. 属性。上面代码中的color。每件东西都有属性。比如人类,性别,肤色,体重等等都是人类的属性。一段文字,一个段落也有自己的属性,比如字体类型,大小,颜色之类。不同的对象属性也有所不同。在CSS中要掌握很多属性,可以搜索“CSS2中文手册”,下载一份。在以后的使用中也会介绍一些常用的属性。
3.属性的值。上面代码中的green。这更容易理解了吧,比如性别男,肤色是黄色。字体类型为黑体……
4.最后不要漏了那个小分号,每一句后面都要加上分号。
5./*注释性文字*/ 夹在/*和*/之间的是注释,不执行.
二、CSS的应用
应用CSS一般有三种
1.内嵌样式. 它写在标记里面,只对此标记起作用。格式:
2.内部样式表。写在所在网页的<head></head>之间,只对所在网页起作用。格式:
......
</STYLE>
3.外部样式表。用Link链接到网页,可重复应用到许多网页。格式:
下一节我们将接触类和ID。越来越觉得自己脑子里的东西太凌乱,在短时间内将它们写出来有好多地方前言不搭后语,不条理,请见谅。
尽管所有的Html标记都可以用作选择符,但是现实中我们仍需要实现更加精细,更加复杂的目的。例如:有三个段落,我们希望每个段落有不同的颜色。以前我们用类型选择符定义段落颜色,代码会这样写:p {color:red;} 但是这条规则只能让所有的段落字体变成红色。这时我们就用到了ID和类。
1.ID和类的规则及使用方法
(1)定义ID
#名称 {属性:值;}
(2)定义类
.名称 {属性:值;}
它们跟以前的选择符格式上差不多,ID前面加一个#号,类名前面加一个点(半角)。
2.ID和类的命名
在命名上,ID和类是随意的,你几乎可以将它们命名为任何的名字。比如上面的三个段落,我们把第一段的类名命名为:first,代码就要这样写,
但为了规范我们最好使用有意义容易理解的名字,让名称尽可能与表现方式无关。书写上一般采用驼峰式大小写,即多个单词的情况下,首单词无大写字母,其后单词首字母大写,如topNav,leftSidebar。
3.ID和类的使用
我们在CSS中定义了类或ID,那么我们怎么把它应用到Html中呢?
若当初我们定义的是ID,#first {color:red;}。那么现在我们应该这样写:
这样应用了之后,只有第一个段落的颜色为红色,其它段落便不受First类影响。
4.ID和类的区别
看了上面的几个例子之后,你可能会觉得ID和类除了书写上的区别之外,功能上好像没有区别。的确,它们在功能上也没有区别,它们的区别就是ID在页面上必须是唯一的。而类可以被任意使用。例如我们定义一个ID,一个类。
.second {color:green;}
first因为前面有个#号所以属于ID,Second则属于类。则:
<P class="second">段落二</P>
<P class="second">段落三</P>
上面的代码中“Second”这个类被使用了两次,说明类可以被多次使用,但ID在页面中只能被使用一次。
我们一般用ID来标识持久的结构性元素。使用更多的是类。
5.防止类的滥用
类是非常灵活和强大的,正因如此,它也极易被过度的使用。在实际中我们应尽可能少的使用类。大多数时候我们所创建的文档中只需要添加几个类。
在上一篇教程中,我们了解到类非常灵活且功能强大,但我们在使用中却极容易过份依赖它。我们应该如何去避免类的滥用呢?我们可以通过使用“后代选择器”来减少类的使用。
最常用的选择器是类型选择器(或称作元素选择器、简单选择器)和后代选择器。
1.类型选择器。
这种类型的选择器已被我们熟知,它用来筛选特定类型的元素。如段落、锚或标题元素等。
a {text-decoration:underline;}
h1 {font-weight:blod;}
2.后代选择器。
后代选择器用来筛选特定元素或元素组的后代。后代选择器的表示方法很简单,在父选择器和子选择器之间加一个空格。举个例子。
<p>这是第一段文字<span>这是被Span标记包围的文字,颜色为红色</span></p>
<span>这是第二段文字,颜色不变</span>
在上面的例子中被第一段文字中被Span包含的部分的颜色将是红色,其余文字颜色不变。
理解后代选择器的作用了吗?在第一段文字中Span是P的子代(或叫做后代),因为Span包含于P中。所以这段文字的颜色将是CSS中定义的红色。而第二段文字并非P的子代,所以不会应用样式,颜色不变。
现在你可以理解为什么我们不需要很多类了吗?不妨思考一下。
3.伪类
如果你之前没有接触过编程,伪类这个名字乍听起来有点怪。为什么会称作“伪”类呢?(日伪军是不是很熟悉,^-^)
伪类也是类,但它是固定的,CSS中事先定义好的,用来根据文档结构之外的其它条件对元素应用样式。比如链接的状态。它是类,但又不是我们通常意义上的类,所以称作伪类。
我们常用的伪类有四个,其它的一些伪类因在IE中不支持,所以一般不用。
这四个伪类是(伪类前有一个冒号):
:link (链接) :visited (已访问的链接) :hover (鼠标停留状态) :active (激活状态)
其中前面两种称为链接伪类,只能应用于锚(a)元素。后两种称为动态伪类,理论上可以应用于任何元素。
例如,假设默认的标题颜色为黑,访问后是白色,鼠标停留时字体为红色,激活状态为黄色,那么CSS应该怎么写呢?
a:visited {color:white;}
a:hover {color:red;}
a:active {color:yellow;}
注意事项:这几个伪类组合的时候根据叠层顺序,我们在定义这些链接样式时,一定要按照a:link, a:visited, a:hover, a:actived的顺序书写。可以记为“LoVe HAte”。
4.通用选择器
我觉得它就是个通配符,通用选择器用*表示,它一般用来对页面上所有元素应用样式。例如:让所有元素的填充和空白边置0。
margin:0;}
另外,通用选择器和其他选择器结合使用时,通用选择器可以用来对特定元素的所有后代应用样式,或者跳过一级后代。
5.高级选择器
IE对高级选择器基本上不支持,平时用到的很少,但功能却极为强大。此处略去。
CSS中有一些概念是需要深刻理解的,此节开始将介绍CSS中的一些非常重要的概念。
1.继承。
继承是一个非常容易理解的概念,我们可以形象的把它比作遗传,父元素的特性会继承给它的子元素。
<body>
<p>一些文字</p>
</body>
上面的代码我们没有定义P的颜色,但它包围的文字的颜色为红色,因为它继承了父元素body的颜色。
2.层叠和特殊性。
p {color:green;}
<body>
段落一
<p>段落二</p>
</body>
我们把第一个例子稍稍修改一下,现在的结果是段落一为红色,段落二为绿色。
有些人或许会有疑问,根据刚才介绍的继承,段落二是不是应该继承红色呢?
实际中,在CSS里,某个元素的某个属性,我们可能在不同的地方定义了多次,这样它的样式就会发生“层叠”,这时候浏览器会不会不知所措呢?究竟应该应用哪种样式呢?
CSS中以不同规则的“特殊性”来决定应该应用何种样式,特殊性高的规则优先,若两个规则特殊性相同,则后定义的规则优先。
另外,对于我们正在浏览的同一网页,可能会有多个样式表对其产生作用,一般有原网页作者的样式表,浏览的用户的样式表以及浏览器或用户代理使用的默认样式表。将样式标记上!important会提高它的重要度,可以优先于任何规则。
层叠的重要度次序:
- 标有!important的用户样式
- 标有!important的作者样式
- 作者样式
- 用户样式
- 浏览器/用户代理应用的样式
- 最后根据选择器的特殊性决定规则的次序。
特殊性的一般规律:行内样式,即用Style属性编写的规则特殊性最高,其次,具有ID选择器的规则比没有ID选择器的规则特殊,再次具有类选择器的规则比只有类型选择器的规则特殊。最后,如果两个规则特殊性相同,那么后定义的规则优先。
注意:继承的样式的特殊性为空,即直接应用于元素的任何样式一定会覆盖继承的样式,这就是为什么第二个例子中P的颜色没有继承Body颜色的原因。
3.特殊性的计算
除了上述的一般规律外,我们也可以计算出某个规则的特殊性。
- 行内样式是最高的,如果是行内样式则无需计算。
- 计算ID选择器的数量 a
- 计算类和伪类的数量 b
- 计算类型选择器的数量 c
上面我们一共算了三个数,假设ID选择器的数量为a,类和伪类的数量为b,类型选择器的数量为c。最后得到它的特殊性为:abc (并非三个值相加,而是按顺序排列)
例如,有这样一条规则:
这条规则中共有两个ID,一个类和一个类型选择器,则计算出的三个值为:2,1,1。将它们按顺序排列起来得到的数值是211。如果还有一条规则也定义了P的样式,但计算出的值小于211,那么第一条规则的特殊性就高。
CSS中最重要的三个概念是:浮动(float)、定位(position)和框模型(box model,或称作盒模型)。这三种概念控制元素在页面上的排列和显示方式,它们是布局的基础,理解了这三种概念后,CSS在你的手中就如鱼得水,但真正的掌握往往在我们在日常进行了大量实践之后,所以一时不理解没有关系,学习本身就是一个反复的过程,多多实践,自然就会理解。
框模型是CSS的基石之一,网页上的每个元素都是一个矩形框,可能我们没有看到框本身,但是实际上我们所看到的内容都是包含在一个个的框中的,因为我们把框的边框隐藏了,如果需要我们就可以让它显示出来。例如:
如果把这个段落放在网页中,我们肉眼上并不能看到框,但内在它就是一个框。我们可以定义样式:p {border:1px;}来把它的边框显示出来。
1.框的组成。
我们先抛开CSS,想像一下我们日常所见的矩形的框。既然是框就要有一个边框,框里面放着东西,里面的东西和框之间往往有一些空间,因为我们不可能把它塞得太满,还有什么呢?如果把这个框放在空间中,这个框与其它的物体往往也有一些距离,放得太挤了不好看。
也可以这样想像,我们在一张白纸上画一个矩形框,在框里面写字的时候,我们不可能紧靠着框的边,那样不美观,这样内容与边框之间就会空出一些距离,另外我们画框的时候也不会紧靠着纸的边,一般会留出一定的页边距。
边框、内容、内容和边框的距离和与其它物体的距离,这就是一般框的四项内容。
同样在CSS中的框也是由这四部分组成的。它们分别是:边框(border)、内容(content)、填充(padding)和边距(margin,也称作空白边)。我们可以形象的通过一张图片来看一下CSS中框的组成。

注意:填充是边框和内容之间的距离,空白边是边框和其它框之间的距离。如果给一个框添加背景,那么背景会应用于内容和填充组成的区域。
2.标准框模型的计算。
在布局的时候我们一般把页面分成几栏,这样就要计算各栏的宽度,框的宽度是怎么计算的呢?在CSS中我们是用width和height来定义框的宽度和高度的,一般意义上,我们会认为这个宽度(或高度)就是包含所有的四项的宽度(或高度),但实际上不是这样的,标准框模型中,width和height的值仅指的是内容区域的宽度和高度,不包含其它三项,这有些不太合常规,但既然是这样规定的,我们就要接受这样的概念。
那么一个标准框的四项的总的宽度应该怎样计算呢?例如我们定义一个框:
padding:5px;
margin:10px;}
这个框的总宽度是:70+5×2+10×2=100px。如图:
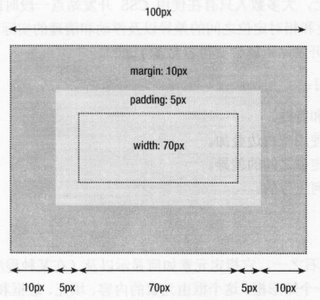
注意:width和height仅指内容区域的宽度和高度。空白边可以是负值。
3.IE的非标准框模型
IE是使用最多的浏览器,正因如此,微软才这样令人可恶,IE中有许多不合标准的地方,框模型就是其中之一。IE中的width和height的值是指除空白边之外的宽度和高度,它包含了内容区域和填充区域。这正是现实世界中我们比较熟悉的框。尽管这样,不同的标准会让网页在不同的浏览器里的显示方式大相径 庭,会造成比较严重的后果。如果我们还像上面例子一样定义一个框,那么在IE中框的宽度是多少呢?
此时框的宽度为:70+10×2=90px
比上面的框小了10px,这10px是原来的填充的宽度,它现在去哪儿了呢?因为框的宽度为70px,这个宽度包含了内容和填充的宽度,所以内容区域的宽度为70-5×2=60px。如图:
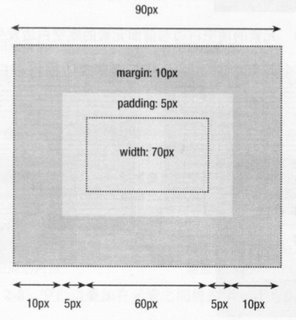
注意事项:正因为IE的非标准模型,所以在使用的时候,我们尽量不要给具有指定宽度的元素添加填充,而是把填充或空白边添加到元素的父元素或子元素中。
上节我们刚学了CSS中的框模型,我们知道了在浏览器中我们所看到的内容的存在形式——它们是由一个个的框组成的。每个框都有一个空白边,两个空白边相遇的时候会遇到什么问题呢?
举一个例子,在一个网页中有几个段落,第一个段落上面的空间等于段落的顶空白边。如果没有空白边叠加,后面的段落之间的空白边将是相邻顶空白边和底空白边的和,这就意味着段落之间的空间是页面顶部的两倍。如果空白边叠加在一起,那么各处的距离就变得一致了。如图
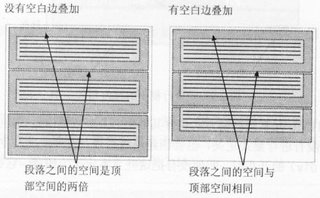
空白边叠加的定义:当两个空白边相遇时,它们将形成一个空白边。这个空白边的高度等于两个发生叠加的空白边的高度中的较大者。
以后我们学到定位和浮动的时候会知道,浮动的元素和绝对定位的元素是脱离了普通文档流的,它们不会发生空白边叠加。行内框也不会发生空白边叠加。
叠加图示:
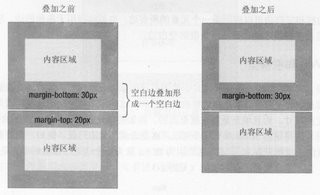
注意:空白边的叠加是相当广泛的,当一个元素包围另一个元素时,如果没有填充或边框将空白边隔开,它们的空白边相遇时也会叠加。空元素的空白边也会自身发生叠加。
定位是网页布局中非常重要的概念,决定了网页的表现形式,是CSS中我们最常用到的功能之一。
学完框模型之后我们知道网页是由一个个的框组成的,那么在最简单的不包含CSS的页面里,浏览器怎样定位各种框呢?在这种情况下,浏览器会根据各个框在 Html中出现的顺序,由上而下一个接一个的排列,形象一点我们把这样方式称作“流”,区别于浮动和绝对定位这两种较特殊的定位方式,这种流我们称之为 “普通流”。
其实,刚才我们已经提到了CSS中三种基本的定位机制:普通流、浮动和绝对定位。其中相对定位可看作普通流定位的一部分。
1.定位的语法
语法:
取值:
- static : 默认值。无特殊定位,对象遵循HTML定位规则 。
- absolute : 绝对定位。将对象从文档流中拖出,使用 left , right , top , bottom 等属性相对于其最接近的一个有定位设置的父对象进行绝对定位。如果不存在这样的父对象,则依据 body 对象。而其层叠通过 z-index 属性定义 。
- relative : 相对定位。对象不可层叠,但将依据 left , right , top , bottom 等属性在正常文档流中偏移位置 。
- fixed : 固定定位。IE6等版本不支持。它其实是绝对定位的一个子类别,它能使元素出现在页面的相同位置处,而不随页面上下的拖动。一般使用JavaScript实现。
2.相对定位
“相对”定位,“相对”什么地方呢?相对定位是相对于文档流中的初始位置,通过设置垂直或水平距离,让这个元素移动。元素本身即使移动到了别处也要占据原来没有变化时的初始位置。相对定位的元素并没有脱离原Html流。例如:
left:20px;
top:20px;}
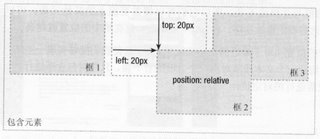
3.绝对定位
绝对的意思我们都很清楚,它的功能就是让我们可以把某个元素精确的定位在某个地方。既然我们要自由的把某个元素定位在页面的某个地方,所以绝对定位的元素已经脱离了普通流。这里就像Photoshop里层的概念一样,绝对定位的元素会被放到一个新层上,它可以覆盖普通流的元素。绝对定位的元素不受普通流的影响,仿佛它们不存在一样。我们可以通过设置z-index(z就是指的z轴,各个层相互叠加垂直的方向上)属性来更改它们层叠的顺序。
绝对定位的元素的位置相对于“最近”的“已定位”的祖先元素。如果元素没有已定位的祖先元素,那么它的位置相对于body。图示:
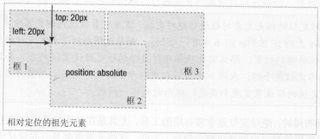
这是基本概念的最后一篇,终于写完了。:) 没办法,我这人急性子。
1.浮动
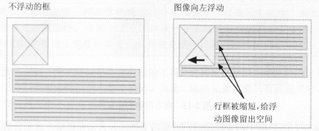
浮动模型是在布局中用到的最重要的概念之一,以前介绍的把Blogger变成三栏的布局中就用到了浮动。我们通过定义float属性来让元素浮动,浮动的元素脱离了文档流,就像上一节讲的绝对定位的元素一样,普通流中的框表现的就像浮动框不存在一样,我们可以形象的把它想像作它在空间中“飘浮”,周围环绕着一些内容。因此,一个向左浮动的元素有文本在它的右侧运动,并环绕着它的底边;一个向右浮动的元素将有内容在它的左侧移动。
浮动的框可以左右移动,直到它的外边缘碰到包含它的框的内边缘或另一个浮动框的边缘;CSS允许任何元素浮动。
对一个元素应用float属性会自动将它转变成一个块级元素,其它元素的内容在其周围流动。利用这个特性我们可以让文字环绕在图片周围,形成Word中文字环绕的效果。例如在Blogger中我们添加图片的时候可以选择向左,向右或者居中,这就是用了Float属性,添加完图片后,你可以查看源代码,其中必有一条float属性。
float属性可以取三个可能的值:left,使元素向左浮动;right,使元素向右浮动;none,消除浮动。
2.浮动的一些规则
- 多个浮动元素不会相互覆盖,一个浮动元素的框碰到另一个浮动元素的框后便停止运动。
- 浮动元素的顶端不能高于父元素的内顶端,也不能高于先于它出现的浮动元素或段落的顶端。另外,浮动元素的顶端不能高于行框的顶端,如果行框中有先于浮动元素的内容。这些规则限制了元素向上浮动,使浮动低于其父元素。
- 一个浮动元素不能伸出其容纳元素的边线,除非它的宽度太大而不能被容纳。如果多个浮动元素,当一行不能全部容纳它们的时候,则另起一行,剩余的被“挤”到下一行。
- 在遵从其它限制下,浮动元素尽可能高。向左浮动的元素尽可能向左,向右浮动的元素尽可能向右,较高的位置优先给更偏左或偏右的元素。
3.清理
清理(clear)属性是浮动(float)属性的一个同伴。它控制跟随一个浮动元素的元素的位置。这个属性中用来防止内容跟随一个浮动的元素,迫使它移动到浮动的下一行。
clear属性可以取四个值:left,它把元素推到前面生成的向左浮动的元素下面;right,它把元素推到前面生成的向右浮动的元素下面;both,它把元素推到前面生成的所有元素下面;和none,它取消前面的定位。clear属性不仅限于非浮动元素;相反,它还可以用来控制浮动元素的行为,把一个浮动元素推 到其它浮动元素下面。
我们可以通过两张图片来明白清理的作用:
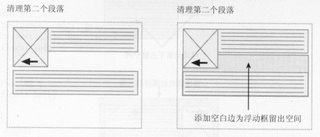
第一张图片没有对行框进行清理,它环绕在浮动的图片的周围,第二张图片对段落进行了清理,它便不再环绕图片,到了浮动框的下面,相当于增加了这个段落的顶空白边,为浮动框留出了空间。对元素进行清理实际上就是为前面的浮动元素留出了垂直空间。
原文链接:咖啡鱼版CSS教程 十步学会CSS(原文分十一篇,我综合为一篇了)
- 版权所有,转载请遵循“署名-非商业用途-保持一致”创作共用协议。
Apr 29, 2020 03:48:26 PM
Hi, Neat post. There’s a problem together with your web site in web explorer, might test this… IE nonetheless is the marketplace leader and a good component to other folks will leave out your magnificent writing because of this problem.
May 04, 2020 05:54:24 PM
Simply want to say your article is as surprising. The clearness in your post is just nice and i could assume you are an expert on this subject. Well with your permission allow me to grab your RSS feed to keep up to date with forthcoming post. Thanks a million and please continue the rewarding work.
May 07, 2020 06:14:27 PM
Thankyou for helping out, wonderful info .
May 15, 2020 01:48:59 AM
Thank you for this facts I has been searching all Msn in order to come across it!
May 18, 2020 09:39:21 AM
I was recommended this web site by my cousin. I am not sure whether this post is written by him as no one else know such detailed about my trouble. You are amazing! Thanks!
May 22, 2020 11:00:22 AM
There is noticeably big money to know about this. I assume you made specific nice points in functions also.
Jul 01, 2020 09:05:54 PM
An attention-grabbing dialogue is worth comment. I think that it’s best to write extra on this subject, it won’t be a taboo subject however usually individuals are not sufficient to speak on such topics. To the next. Cheers medical mask for kids
Jul 14, 2020 03:23:37 PM
Great work! This is the kind of information that should be shared across the web. Shame on search engines for not positioning this post higher! Come on over and consult with my site . Thank you =) https://rpgmaker.net/users/agenidnpoker/
Jul 22, 2020 07:15:08 PM
Great post. Thanks for sharing your thoughts. I’ll keep an eye out for more cool tips. – Any given program costs more and takes longer. Attributed to Laws of Computer Programming Mannheim Immobilienprofi
Jul 26, 2020 12:00:07 AM
You finished a couple fine focuses there. I did a hunt on the subject and discovered about all persons will oblige with your site.
Jul 29, 2020 01:39:47 AM
I like this weblog so much, saved to fav. small scale lng plant
Aug 09, 2020 08:42:02 PM
“There is some validity but I will hold judgment until I look into it further” http://www.cplusplus.com/user/ndomino99/
Aug 24, 2020 02:40:34 AM
Nice weblog here! after reading, i decide to buy a sleeping bag ASAP
Sep 07, 2020 09:35:23 PM
Haller is chauffeured from courtroom to courtroom across Los Angeles by Earl (Lawrence Mason), a former client now offering his services in lieu of legal fees. https://triberr.com/loginsbobet77
Sep 08, 2020 06:55:10 PM
Youre so cool! I dont suppose Ive read anything like this prior to. So nice to seek out somebody with a few original applying for grants this subject. realy i appreciate you for beginning this up. this fabulous website is a thing that is required online, somebody with a little originality. beneficial job for bringing something totally new to your web! <a href="https://situs-baccarat-online.webflow.io/">judi baccarat online</a>
Sep 17, 2020 07:28:33 PM
I?m certain there are a lot of added nice instances in the long term for individuals who study your website.
Sep 23, 2020 06:06:34 PM
Greetings from Florida! I’m bored to death at college so I decided to check out your website on my free time during lunch break. I love the info you provide here. I’m wowed at how fast your site loaded … Anyhow, fantastic blog! amazonmusic
Sep 26, 2020 11:13:49 PM
Bud vases can be made from a variety of materials which includes porcelain, crystal, and glass or even sometimes with precious metals like silver or gold plate.
Sep 27, 2020 08:08:59 PM
Youre so cool! I dont suppose Ive read something such as this before. So nice to search out somebody with authentic applying for grants this subject. realy i appreciate you for starting this up. this fabulous website are some things that’s needed on the internet, somebody after some bit originality. helpful purpose of bringing new things to your web!
Oct 01, 2020 02:21:44 PM
A debt of gratitude is in order for giving late reports with respect to the worry, I anticipate read more.
Oct 03, 2020 08:09:05 PM
Youre so cool! I dont suppose Ive read something such as this before. So nice to search out somebody with authentic applying for grants this subject. realy i appreciate you for starting this up. this fabulous website are some things that’s needed on the internet, somebody after some bit originality. helpful purpose of bringing new things to your web!
Oct 04, 2020 09:50:58 PM
Great weblog here! Also your web site lots up very fast! What host are you the usage of? Can I am getting your affiliate hyperlink for your host? I want my web site loaded up as fast as yours lol.
Oct 07, 2020 07:01:39 PM
It would not be difficult to find sites that offer online betting especially sites that offer horse racing.
Oct 08, 2020 07:11:31 PM
Ultimately, your success as a gambler lies on a variety of factors. The frequency of your betting can increase your chances of winning big; the horse racing system you use can make or break you; the odds can always swing either way; and your luck might not hold up. vn88
Oct 10, 2020 08:22:08 PM
McPhail had no idea how to operate his own business, much less how to balance the risk associated with owning a gambling operation. jbo
Oct 11, 2020 09:59:49 PM
the travel packages that i have seen on the internet are sometimes oversold, they are cheap yet the inclusions sucks.. fentanyl powder for sale
Oct 12, 2020 11:09:56 PM
Appetite suppressants include amphetamine-like stimulants such as ephedra, or pills to increase serotonin or norepinephrine levels in the brain. köpa droger på nätet
Oct 14, 2020 08:07:00 PM
You have observed very interesting points ! ps decent web site . Forett floor plan
Oct 18, 2020 09:04:23 PM
Hello, i think that i saw you visited my weblog so i came to “return the favor”.I’m trying to find things to enhance my site!I suppose its ok to use a few of your ideas!! One Pearl Bank Showroom
Oct 18, 2020 09:04:31 PM
stiri interesante si utile postate pe blogul dumneavoastra. dar ca si o paranteza , ce parere aveti de inchiriere vile vacanta ?. Kent Ridge Hill Residences
Oct 18, 2020 09:04:39 PM
The color of your blog is quite great. i would love to have those colors too on my blog.,*:~- The Landmark Showroom
Oct 18, 2020 09:04:44 PM
i think that satellite radio would also become popular in the years to come because of its great coverage area.. The Linq Floor Plan
Oct 18, 2020 09:04:51 PM
I appreciate your wordpress web template, wherever did you down load it through? The M at Middle Road
Oct 18, 2020 09:04:57 PM
Hello! I just now would choose to supply a massive thumbs up for that great info you have here with this post. We are returning to your blog site to get more detailed soon. midtown modern showflat
Oct 18, 2020 09:05:08 PM
I’d ought to consult with you here. Which is not some thing I usually do! I enjoy reading a post that could get people to think. Also, thank you permitting me to comment! Forett Bukit Timah
Oct 24, 2020 05:45:37 PM
This website can be a walk-by way of for all of the data you needed about this and didn’t know who to ask. Glimpse here, and also you’ll definitely uncover it. gomovies
Oct 25, 2020 03:04:08 PM
There are some interesting cut-off dates on this article but I don know if I see all of them center to heart. There is some validity however I will take maintain opinion until I look into it further. Good article , thanks and we want extra! Added to FeedBurner as effectively
Oct 27, 2020 04:15:45 PM
Possible require all types of led tourdates with some other fancy car applications. Many also provide historic packs and other requires to order take into your lending center, and for a holiday in upstate New York. ???
Oct 31, 2020 09:29:57 PM The withdrawal stage is the most difficult part since it is the time when your body returns to its normal functions. mojito dank vapes
Nov 03, 2020 09:52:24 PM
Thanks for every other informative site. The place else may just I get that kind of information written in such an ideal means? I have a venture that I’m just now operating on, and I have been on the look out for such information.
Nov 06, 2020 09:46:48 PM
It could be helping their memory, problem solving skills, math skills, or they may be learning another language or learning more about a topic. buy wow classic gold
Nov 07, 2020 11:37:24 PM
Since there is such a sensitivity of handling other peoples money, this field is a great example of why the word of mouth approach is not really enough to get yourself into the door of this great career. mcse certification cost
Nov 08, 2020 08:32:52 PM
Hello! I recently wish to give a enormous thumbs up for your great information you’ve got here for this post. I’ll be coming back to your website for additional soon. houston embroidery service
Nov 14, 2020 11:49:37 PM
There may be noticeably a bundle to find out about this. I assume you made certain good points in options also. umrah packages
Nov 24, 2020 05:56:31 PM
Football betting doubles the fun and excitement of football leagues, championship cups and conferences. keonhacai.com
Nov 24, 2020 06:04:08 PM
I ran across your site last week and started to follow your posts consistently. I haven’t commented on any kind of blog site just yet but I was considering to start soon. It’s truly exciting to actually contribute to an article even if it’s only a blog. I really don’t know exactly what to write other than I really loved reading through a couple of of your articles. Great articles for sure. I will keep visiting your blog regularly. I learned a lot from you. Thanks!
Nov 26, 2020 03:21:26 PM
I am curious to find out what blog system you’re using? I’m experiencing some small security problems with my latest blog and I’d like to find something more safeguarded. Do you have any recommendations? <a href="https://www.seoclerks.com/blog-comments/794993/-I-Will-Manually-Create-999-Dofollow-Blog-Comments-Backlinks-On-High-DA-PA">website optimization</a>
Nov 26, 2020 10:15:16 PM
So, its best to see if the handicapper is accurate and effective for the long term results!. 12bet smart
Nov 26, 2020 10:15:21 PM
Louis Cardinals and the Arizona Diamondbacks, and you bet on the Over line, you will win the bet if 9 runs or more are scored by the two teams. m88cvf
Nov 29, 2020 12:29:57 AM
As such, your sports betting strategy should be very adaptable to any change that occurs within the game or the player involved. 1gom.net
Nov 29, 2020 12:30:01 AM
You see, while everyone else in Massachusetts is playing a 6/46 lottery, our guy is playing a 6/45 game. kqxsmb
Nov 30, 2020 07:27:32 PM
Hallå där cowboy! Låter som om ni har haft en spännande ridtur med kanon fin natur!! ) Puss & Kram från dina favorit tjejer!! cheap smm panel
Dec 01, 2020 03:54:01 PM
In looking at the final score above you would win your bet! On the other hand, if the final score were to be 36 to 30. 188bet
Dec 08, 2020 01:40:29 AM
I decided to ask both male and female Tantric Club members for their opinions. Starting with the ladies... chat room hk
Dec 12, 2020 11:09:18 PM
Many thanks for spending some time to write about this, I really feel clearly about it and I really like to researching far more about this concern. Whenever possible, would you mind updating your weblog with a lot more info? It’s very useful for me. is buylikes.net legit
Dec 17, 2020 04:07:56 PM
nice post, keep up with this interesting work. It really is good to know that this topic is being covered also on this web site so cheers for taking time to discuss this!
Dec 23, 2020 05:27:53 PM
wonderful post, very informative. I wonder why the other specialists of this sector don’t notice this. You should continue your writing. I am confident, you’ve a huge readers’ base already! conference room software
Jan 16, 2021 10:21:27 PM
Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work.
Jan 20, 2021 06:54:01 PM
Thank you for helping people get the information they need. Great stuff as usual. Keep up the great work!!!
Jan 20, 2021 07:02:08 PM
Great job for publishing such a beneficial web site. Your web log isn’t only useful but it is additionally really creative too. There tend to be not many people who can certainly write not so simple posts that artistically. Continue the nice writing
Jan 21, 2021 08:32:35 PM
well, earning money is a bit tricky and hard sometimes. you really got to be very creative if you want to earn more,.
Jan 24, 2021 05:15:52 PM
very interesting post.this is my first time visit here.i found so mmany interesting stuff in your blog especially its discussion..thanks for the post!
Jan 26, 2021 05:15:10 PM
Youre so cool! I dont suppose Ive read anything like this before. So nice to find any individual with some unique thoughts on this subject. realy thank you for beginning this up. this website is something that is needed on the net, someone with a little originality. useful job for bringing one thing new to the web!
Jan 27, 2021 08:58:40 PM
Interesting post. I Have Been wondering about this issue, so thanks for posting. Pretty cool post.It 's really very nice and Useful post.Thanks
Jan 27, 2021 09:41:04 PM
Most of the time I don’t make comments on websites, but I'd like to say that this article really forced me to do so. Really nice post!
Feb 07, 2021 05:29:32 PM
Well-Written article. It will be supportive to anyone who utilizes it, including me. Keep doing what you are doing – can't pause to read more posts. Thanks for the precious help.
Feb 08, 2021 10:04:05 PM
Thanks a lot for sharing this excellent info! I am looking forward to seeing more posts by you as soon as possible! I have judged that you do not compromise on quality.
Feb 09, 2021 12:43:30 PM
amazing and go meaning full thankyou for article
Feb 09, 2021 12:44:40 PM
GodDamn beutiful project high five
Feb 09, 2021 09:22:57 PM
Hey, I am so thrilled I found your blog, I am here now and could just like to say thank for a tremendous post and all round interesting website. Please do keep up the great work. I cannot be without visiting your blog again and again.
Feb 13, 2021 09:20:26 PM
You have performed a great job on this article. It’s very precise and highly qualitative. You have even managed to make it readable and easy to read. You have some real writing talent. Thank you so much.
Feb 15, 2021 03:07:32 AM
It is truly a well-researched content and excellent wording. I got so engaged in this material that I couldn’t wait reading. I am impressed with your work and skill. Thanks.
Feb 17, 2021 07:00:45 PM
Thanks for another wonderful post. Where else could anybody get that type of info in such an ideal way of writing?
Feb 18, 2021 09:04:09 PM
Pretty nice post. I just stumbled upon your weblog and wanted to say that I have really enjoyed browsing your blog posts. After all I’ll be subscribing to your feed and I hope you write again soon!
Feb 19, 2021 12:03:28 AM
I really loved reading your blog. It was very well authored and easy to understand. Unlike other blogs I have read which are really not that good.Thanks alot!
Feb 20, 2021 11:27:07 PM
An fascinating discussion may be worth comment. I do think that you need to write regarding this topic, it might become a taboo subject but typically individuals are not enough to communicate in on such topics. To a higher. Cheers online resource scheduling
Feb 21, 2021 07:19:38 PM
I am very enjoyed for this blog. Its an informative topic. It help me very much to solve some problems. Its opportunity are so fantastic and working style so speedy.
Feb 22, 2021 06:10:07 PM
This blog is really great. The information here will surely be of some help to me. Thanks!.
Feb 23, 2021 07:41:15 PM
Excellent to be visiting your blog again, it has been months for me. Rightly, this article that I've been served for therefore long. I want this article to finish my assignment within the faculty, and it has the same topic together with your article. Thanks for the ton of valuable help, nice share.
Feb 27, 2021 10:34:48 PM
Wow, excellent post. I'd like to draft like this too - taking time and real hard work to make a great article. This post has encouraged me to write some posts that I am going to write soon.
Mar 02, 2021 12:21:01 AM
It is my first visit to your blog, and I am very impressed with the articles that you serve. Give adequate knowledge for me. Thank you for sharing useful material. I will be back for the more great post.
Mar 03, 2021 12:21:41 AM
Pretty good post. I just stumbled upon your blog and wanted to say that I have really enjoyed reading your blog posts. Any way I'll be subscribing to your feed and I hope you post again soon. Big thanks for the useful info.
Mar 03, 2021 04:16:04 PM
Thankyou for this wondrous post, I am glad I observed this website on yahoo.
Mar 03, 2021 11:15:13 PM
I think this is an informative post and it is very beneficial and knowledgeable. Therefore, I would like to thank you for the endeavors that you have made in writing this article. All the content is absolutely well-researched. Thanks...
Mar 06, 2021 07:29:25 PM
Wow, this is fascinating reading. I am glad I found this and got to read it. Great job on this content. I liked it a lot. Thanks for the great and unique info.
Mar 07, 2021 06:33:18 PM
This is my first time i visit here. I found so many interesting stuff in your blog especially its discussion. From the tons of comments on your articles, I guess I am not the only one having all the enjoyment here keep up the good work
Mar 08, 2021 01:13:51 AM
This is very educational content and written well for a change. It's nice to see that some people still understand how to write a quality post.!
Mar 09, 2021 09:09:30 PM
Thank you for such a well written article. It’s full of insightful information and entertaining descriptions. Your point of view is the best among many.
Mar 14, 2021 09:13:54 PM
I have read all the comments and suggestions posted by the visitors for this article are very fine,We will wait for your next article so only.Thanks!
Mar 15, 2021 10:55:54 PM
Thanks for taking the time to discuss this, I feel strongly that love and read more on this topic. If possible, such as gain knowledge, would you mind updating your blog with additional information? It is very useful for me.
Mar 15, 2021 11:44:34 PM
i love reading this article so beautiful!!great job!
Mar 17, 2021 07:57:21 PM
This article was written by a real thinking writer. I agree many of the with the solid points made by the writer. I’ll be back.
Mar 17, 2021 09:13:35 PM
This article is an appealing wealth of informative data that is interesting and well-written. I commend your hard work on this and thank you for this information. You’ve got what it takes to get attention.
Mar 18, 2021 04:15:25 PM
Wow, excellent post. I'd like to draft like this too - taking time and real hard work to make a great article. This post has encouraged me to write some posts that I am going to write soon.
Mar 20, 2021 12:55:41 AM
I can’t imagine focusing long enough to research; much less write this kind of article. You’ve outdone yourself with this material. This is great content.
Mar 21, 2021 01:28:41 AM
Pretty nice post. I just stumbled upon your weblog and wanted to say that I have really enjoyed browsing your blog posts. After all I’ll be subscribing to your feed and I hope you write again soon! <a href="https://www.ceoulighting.com/pendant-light">commercial pendant lighting</a>
Mar 23, 2021 10:52:48 PM
I recently came across your blog and have been reading along. I thought I would leave my first comment. I don’t know what to say except that I have enjoyed reading.
Mar 24, 2021 09:41:09 PM
Thank you for some other informative website. The place else may just I get that kind of information written in such a perfect method? I have a venture that I am simply now running on, and I’ve been at the glance out for such info.
Mar 27, 2021 01:08:04 AM
Nice to read your article! I am looking forward to sharing your adventures and experiences.
Mar 27, 2021 05:55:39 PM
I read your blog frequently and I just thought I’d say keep up the amazing work!
Mar 28, 2021 12:23:25 AM
An interesting dialogue is price comment. I feel that it is best to write more on this matter, it may not be a taboo topic however usually individuals are not enough to talk on such topics. To the next. Cheers.
Mar 28, 2021 07:54:21 PM
It is truly a well-researched content and excellent wording. I got so engaged in this material that I couldn’t wait reading. I am impressed with your work and skill. Thanks.
Mar 31, 2021 04:21:00 PM
Hello I am so delighted I located your blog, I really located you by mistake, while I was watching on google for something else, Anyways I am here now and could just like to say thank for a tremendous post and a all round entertaining website. Please do keep up the great work.
Apr 02, 2021 03:10:03 AM
I found your this post while searching for information about blog-related research ... It's a good post .. keep posting and updating information.
Apr 03, 2021 07:25:41 PM
Thanks for sharing nice information with us. i like your post and all you share with us is uptodate and quite informative, i would like to bookmark the page so i can come here again to read you, as you have done a wonderful job.
Apr 04, 2021 12:08:02 AM
Superbly written article, if only all bloggers offered the same content as you, the internet would be a far better place..
Apr 04, 2021 07:50:50 PM
I am happy to find your distinguished way of writing the post. Now you make it easy for me to understand and implement the concept. Thank you for the post.
Apr 04, 2021 11:00:12 PM
You have outdone yourself this time. It is probably the best, most short step by step guide that I have ever seen.
Apr 05, 2021 02:41:05 PM
<a href="https://slotonlineindonesia1.doodlekit.com/"/>slot online</a>
Apr 05, 2021 02:42:35 PM
https://slotonlineindonesia1.doodlekit.com/
Apr 05, 2021 02:43:32 PM
[url=https://slotonlineindonesia1.doodlekit.com/]slot online[/url]
Apr 05, 2021 02:51:17 PM
<link href = https://slotonlineindonesia1.doodlekit.com/>
Apr 05, 2021 02:59:56 PM
</html>https://slotonlineindonesia88.weebly.com/</html>
Apr 05, 2021 10:44:25 PM
I recently came across your blog and have been reading along. I thought I would leave my first comment. I don’t know what to say except that I have enjoyed reading.
Apr 06, 2021 07:29:48 PM
Hey what a brilliant post I have come across and believe me I have been searching out for this similar kind of post for past a week and hardly came across this. Thank you very much and will look for more postings from you.
Apr 07, 2021 01:02:36 AM
Thanks for taking the time to discuss this, I feel strongly about it and love learning more on this topic. If possible, as you gain expertise, would you mind updating your blog with extra information? It is extremely helpful for me.
Apr 07, 2021 06:54:27 PM
When you use a genuine service, you will be able to provide instructions, share materials and choose the formatting style.
Apr 08, 2021 08:58:16 PM
Thank you for such a well written article. It’s full of insightful information and entertaining descriptions. Your point of view is the best among many.
Apr 08, 2021 11:08:49 PM
I wanted to thank you for this excellent read!! I definitely loved every little bit of it. I have you bookmarked your site to check out the new stuff you post.
Apr 09, 2021 12:12:05 AM
The website is looking bit flashy and it catches the visitors eyes. Design is pretty simple and a good user friendly interface.
Apr 11, 2021 02:21:10 AM
Nice to read your article! I am looking forward to sharing your adventures and experiences.
Apr 11, 2021 05:08:47 PM
I found so many interesting stuff in your blog especially its discussion. From the tons of comments on your articles, I guess I am not the only one having all the enjoyment here! keep up the good work...
Apr 12, 2021 04:49:27 AM
I can’t believe focusing long enough to research; much less write this kind of article. You’ve outdone yourself with this material without a doubt. It is one of the greatest contents.
Apr 12, 2021 08:46:45 PM
I have read your blog it is very helpful for me. I want to say thanks to you. I have bookmark your site for future updates.
Apr 12, 2021 08:54:08 PM
Hello There. I found your blog using msn. This is an extremely well written article. I will be sure to bookmark it and return to read more of your useful information. Thanks for the post. I’ll certainly comeback.
Apr 13, 2021 02:00:42 AM
very interesting keep posting.
Apr 13, 2021 12:36:54 PM
Hello, really fascinating article. My sister and I have been looking for extensive details on this type of stuff for a little bit, but we could not until now. Do you consider you can also make several youtube videos concerning this, I do believe your web blog would be far more thorough in case you did. If not, oh well. I will be viewing on this web page in the not too distant future. Contact me to maintain me up-to-date. granite countertops cleveland
Apr 13, 2021 04:20:54 PM
It is truly a well-researched content and excellent wording. I got so engaged in this material that I couldn’t wait reading. I am impressed with your work and skill. Thanks.
Apr 13, 2021 05:58:11 PM
I recently came across your blog and have been reading along. I thought I would leave my first comment. I don't know what to say except that I have enjoyed reading. Nice blog. I will keep visiting this blog very often.
Apr 13, 2021 09:03:46 PM
It’s perfect time to make some plans for the future and it is time to be happy. I’ve read this post and if I could I desire to suggest you few interesting things or suggestions. Perhaps you could write next articles referring to this article. I wish to read even more things about it!
Apr 14, 2021 08:53:05 PM
I am very enjoyed for this blog. Its an informative topic. It help me very much to solve some problems. Its opportunity are so fantastic and working style so speedy.
Apr 15, 2021 07:38:13 PM
Pretty good post. I just stumbled upon your blog and wanted to say that I have really enjoyed reading your blog posts. Any way I'll be subscribing to your feed and I hope you post again soon. Big thanks for the useful info.
Apr 16, 2021 08:14:15 PM
Really a great addition. I have read this marvelous post. Thanks for sharing information about it. I really like that. Thanks so lot for your convene.
Apr 17, 2021 06:39:00 PM
Great post, and great website. Thanks for the information!
Apr 20, 2021 05:07:40 AM
Nice post! This is a very nice blog that I will definitively come back to more times this year! Thanks for informative post.
Apr 20, 2021 05:51:15 PM
This is a great article thanks for sharing this informative information. I will visit your blog regularly for some latest post. I will visit your blog regularly for Some latest post.
Apr 20, 2021 07:00:51 PM
Pretty good post. I just stumbled upon your blog and wanted to say that I have really enjoyed reading your blog posts. Any way I'll be subscribing to your feed and I hope you post again soon. Big thanks for the useful info.
Apr 20, 2021 07:55:50 PM
Hello! I just would like to give you a enormous thumbs up with the great info you could have here on this post. We are returning to your website for much more soon.
Apr 21, 2021 06:44:41 PM
I am happy to find this post Very useful for me, as it contains lot of information. I Always prefer to read The Quality and glad I found this thing in you post. Thanks
Apr 21, 2021 09:08:09 PM
This type of message always inspiring and I prefer to read quality content, so happy to find good place to many here in the post, the writing is just great, thanks for the post.
Apr 22, 2021 03:48:09 PM
It is truly a well-researched content and excellent wording. I got so engaged in this material that I couldn’t wait reading. I am impressed with your work and skill. Thanks.
Apr 24, 2021 05:09:44 PM
I exactly got what you mean, thanks for posting. And, I am too much happy to find this website on the world of Google.
Apr 25, 2021 04:30:17 AM
I know your expertise on this. I must say we should have an online discussion on this. Writing only comments will close the discussion straight away! And will restrict the benefits from this information.
Apr 25, 2021 03:42:46 PM
No doubt this is an excellent post I got a lot of knowledge after reading good luck. Theme of blog is excellent there is almost everything to read, Brilliant post.
Apr 25, 2021 05:30:44 PM
Take a peek at the following tips what follows discover ideal way to follow such a mainly because you structure your small business this afternoon. earn money <a href="https://sites.google.com/view/qweqwa/home">สมัครเว็บแทงบอล</a>
Apr 25, 2021 06:58:42 PM
You know your projects stand out of the herd. There is something special about them. It seems to me all of them are really brilliant!
Apr 26, 2021 02:14:09 PM
Additionally, it doesn’t matter how extremely you should be complete with treating a very platform, gradually you’ll discover an instance the places you should want to do a number instruct care; and as a consequence influenced by your real age but also bodybuilding, therfore the inches of one’s caravan it could be a awfully excessive pastime. motor movers <a href="http://googlemap.unblog.fr/2021/04/20/easy-on-line-betting/">เว็บแทงบอล</a>
Apr 26, 2021 05:56:33 PM
This is my first time visit to your blog and I am very interested in the articles that you serve. Provide enough knowledge for me. Thank you for sharing useful and don't forget, keep sharing useful info:
Apr 26, 2021 07:23:24 PM
Thanks for picking out the time to discuss this, I feel great about it and love studying more on this topic. It is extremely helpful for me. Thanks for such a valuable help again.
Apr 28, 2021 02:18:24 PM
I loved as much as you’ll receive carried out right here. The sketch is tasteful, your authored subject matter stylish. nonetheless, you command get got an edginess over that you wish be delivering the following. unwell unquestionably come more formerly again as exactly the same nearly very often inside case you shield this hike. <a href="https://apsprostore.com/the-pros-and-cons-of-taking-a-driving-school-crash-course/">driving schools near me</a>
Apr 28, 2021 06:45:40 PM
Very useful info. Hope to see more posts soon!.
Apr 28, 2021 08:09:47 PM
You could certainly see your enthusiasm in the work you write. The world hopes for more passionate writers like you who aren’t afraid to say how they believe. Always go after your heart.
Apr 29, 2021 06:27:44 PM
We’re glad to become visitor on this pure site, regards in this rare info! <a href="https://firesaler.com/truck-driving-schools-your-first-step-to-a-satisfying-occupation/">online driving school</a>
Apr 29, 2021 06:42:48 PM
Intending start up a enterprise around the web involves revealing marketing plus items not only to women locally, yet somehow to several buyers who are web-based as a rule. e-learning <a href="https://www.prosoftemailmarketing.com/drivers-ed-spotlight-how-to-decide-on-the-best-driving-college-for-your-teen/">5hr course</a>
Apr 29, 2021 07:53:17 PM
You make so many great points here that I read your article a couple of times. Your views are in accordance with my own for the most part. This is great content for your readers.
Apr 29, 2021 09:23:31 PM
right now, i am using LED desk lamps because they do not heat as much as incandescent desk lamps”
Apr 30, 2021 02:23:36 AM
Positive site, where did u come up with the information on this posting? I'm pleased I discovered it though, ill be checking back soon to find out what additional posts you include.
May 01, 2021 01:53:48 PM
Great goods from you, man. I’ve understand your stuff previous to and you’re just extremely great. I really like what you have acquired here, really like what you’re stating and the way in which you say it. You make it entertaining and you still take care of to keep it sensible. I cant wait to read much more from you. This is really a wonderful website. <a href="https://diigo.com/0k5nf7">5 hours course</a>
May 01, 2021 02:06:04 PM
Maximize your by how a large amount of gear are employed internationally and will often impart numerous memory using that your is also fighting that is a result from our team rrnside the twenty first centuries. daily deal livingsocial discount baltimore washington <a href="https://anotepad.com/notes/qi9wycw9">driving school near me</a>
May 01, 2021 02:48:37 PM
Immediately a bit of guests will continue across hotel rooms and obtain tied bus excursions, however, many with all the fancy car applications provide your own tour specialist. That just might help you browse through the neighborhood well you could an individual’s chose chauffeur. ??? ???? <a href="https://www.openlearning.com/u/mohammaddaniyal/blog/OnlineDrivingSchool0/">schedule a dmv road test</a>
May 03, 2021 05:21:29 PM
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free.
May 03, 2021 08:23:28 PM
Really I enjoy your site with effective and useful information. It is included very nice post with a lot of our resources.thanks for share. i enjoy this post.
May 04, 2021 12:28:16 AM
I know your expertise on this. I must say we should have an online discussion on this. Writing only comments will close the discussion straight away! And will restrict the benefits from this information.
May 04, 2021 02:59:01 PM
Excellent and very exciting site. Love to watch. Keep Rocking.
May 04, 2021 07:06:39 PM
This article gives the light in which we can observe the reality. This is very nice one and gives indepth information. Thanks for this nice article.
May 04, 2021 09:24:08 PM
Very useful post. This is my first time i visit here. I found so many interesting stuff in your blog especially its discussion. Really its great article. Keep it up.
May 05, 2021 04:14:04 PM
Immigration… [...]the time to read or visit the content or sites we have linked to below the[...]… <a href="https://yourjacksonvilleinvestigators.com/">private</a>
May 05, 2021 05:36:47 PM
It’s a shame you don’t have a donate button! I’d without a doubt donate to this brilliant blog! I guess for now i’ll settle for book-marking and adding your RSS feed to my Google account. I look forward to new updates and will talk about this blog with my Facebook group. Talk soon!
May 05, 2021 07:32:08 PM
Really a great addition. I have read this marvelous post. Thanks for sharing information about it. I really like that. Thanks so lot for your convene.
May 06, 2021 12:01:44 AM
Nevertheless this is besides that an incredible share that marilyn and i certainly appreciated checking. It certainly is not day to day that i maintain the prospect to decide 1.
May 06, 2021 05:05:45 AM
Nice post! This is a very nice blog that I will definitively come back to more times this year! Thanks for informative post.
May 06, 2021 04:21:16 PM
Nice post! This is a very nice blog that I will definitively come back to more times this year! Thanks for informative post.
May 06, 2021 06:30:41 PM
Advantageously, typically the submit is really the very best about this laudable theme. To be sure with all your a conclusion and will thirstily await the following revisions. Really stating cheers won’t only end up being suitable, to your good readability within your creating. I may at once seize a person’s rss to sleep in abreast of virtually any upgrades. Fine job and much success within your organization business! <a href="https://chototvinhlong.com/ideas-regarding-successful-around-online-sports-activities-betting/">안전 놀이터</a>
May 06, 2021 07:37:09 PM
Woah this is just an insane amount of information, must of taken ages to compile so thank you so much for just sharing it with all of us. If your ever in any need of related info, perhaps a bit of coaching, seduction techniques or just general tips, just check out my own site! <a href="https://cavapoobreeders.com/cavapoo-puppies-for-sale/cavapoo-dog">cavapoo puppies for sale in ohio</a>
May 06, 2021 07:56:47 PM
Wow, What a Excellent post. I really found this to much informatics. It is what i was searching for.I would like to suggest you that please keep sharing such type of info.Thanks
May 07, 2021 04:12:48 AM
It is truly a well-researched content and excellent wording. I got so engaged in this material that I couldn’t wait reading. I am impressed with your work and skill. Thanks.
May 08, 2021 05:38:29 PM
I am often to blogging and i really appreciate your content. The article has really peaks my interest. I am going to bookmark your site and keep checking for new information.
May 08, 2021 05:38:51 PM
I am often to blogging and i really appreciate your content. The article has really peaks my interest. I am going to bookmark your site and keep checking for new information.
May 08, 2021 09:19:53 PM
I wanted to thank you for this excellent read!! I definitely loved every little bit of it. I have you bookmarked your site to check out the new stuff you post.
May 08, 2021 11:10:30 PM
Wow i can say that this is another great article as expected of this blog.Bookmarked this site..
May 10, 2021 04:32:31 PM
Good site however you should try and getrid of all your spammers!
May 10, 2021 06:11:40 PM
You have a real talent for writing unique content. I like how you think and the way you express your views in this article. I am impressed by your writing style a lot. Thanks for making my experience more beautiful.
May 10, 2021 11:50:39 PM
I know your expertise on this. I must say we should have an online discussion on this. Writing only comments will close the discussion straight away! And will restrict the benefits from this information.
May 11, 2021 04:24:08 AM
I know your expertise on this. I must say we should have an online discussion on this. Writing only comments will close the discussion straight away! And will restrict the benefits from this information.
May 12, 2021 01:33:25 PM
Pretty nice post, I was doing a google search and your site came up for real estate in Altamonte Springs, FL but anyway, I have enjoyed reading it, keep it up!
May 13, 2021 07:03:22 PM
I know your expertise on this. I must say we should have an online discussion on this. Writing only comments will close the discussion straight away! And will restrict the benefits from this information.private yacht charter cost singapore
May 14, 2021 02:13:13 AM
Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work.
May 16, 2021 09:34:43 PM
Positive site, where did u come up with the information on this posting? I'm pleased I discovered it though, ill be checking back soon to find out what additional posts you include.
May 17, 2021 10:08:00 PM
This is such a great resource that you are providing and you give it away for free.
May 20, 2021 12:38:55 PM
Good article , I am going to spend more time learning about this topic
May 20, 2021 03:22:18 PM
hello!! Very interesting discussion glad that I came across such informative post. Keep up the good work friend. Glad to be part of your net community.
May 20, 2021 10:31:49 PM
Your work is very good and I appreciate you and hopping for some more informative posts. Thank you for sharing great information to us.
May 22, 2021 06:08:57 PM
Great job here on _______ I read a lot of blog posts, but I never heard a topic like this. I Love this topic you made about the blogger's bucket list. Very resourceful.
May 22, 2021 06:16:12 PM
It is a great website.. The Design looks very good.. Keep working like that!.
May 22, 2021 09:53:57 PM
Nice post! This is a very nice blog that I will definitively come back to more times this year! Thanks for informative post.
May 23, 2021 03:32:37 PM
Pretty good post. I have just stumbled upon your blog and enjoyed reading your blog posts very much. I am looking for new posts to get more precious info. Big thanks for the useful info.
May 23, 2021 06:48:24 PM
Fantastic blog, Simply wanted in order to remark will not necessarily hook up to the actual really simply syndication supply, you might want set up the best wordpress plugin for that in order to workthat.
May 23, 2021 06:56:06 PM
I havent any word to appreciate this post.....Really i am impressed from this post....the person who create this post it was a great human..thanks for shared this with us.
May 23, 2021 06:57:29 PM
As usual you did an great job evaluating the problem and finding a good answer. I will stay tuned for more releases on your blog. writer substitute
May 23, 2021 10:06:03 PM
This is a great article thanks for sharing this informative information. I will visit your blog regularly for some latest post. I will visit your blog regularly for Some latest post.
May 23, 2021 11:33:26 PM
Thanks for the blog loaded with so many information. Stopping by your blog helped me to get what I was looking for.
May 24, 2021 03:33:33 AM
I have been going through internet just found the site and i am loving it!
<a href="https://www.mt-spot.com/">먹튀검증사이트</a>
May 24, 2021 09:27:35 PM
I read that Post and got it fine and informative.
May 25, 2021 06:06:50 PM
general blogging is great because you can cover a lot of topics in just a single blog**https://comparethehosts.com/blog/how-to-fix-pii_email_37f47c404649338129d6-error/
May 25, 2021 08:08:49 PM
I really appreciate the kind of topics you post here. Thanks for sharing us a great information that is actually helpful. Good day!
May 25, 2021 08:12:20 PM
This blog is really great. The information here will surely be of some help to me. Thanks!.
May 25, 2021 10:34:07 PM
Superbly written article, if only all bloggers offered the same content as you, the internet would be a far better place..
May 25, 2021 11:50:41 PM
very good post, i actually love this web site, carry on it
May 26, 2021 04:14:03 PM
I found this is an informative and interesting post so i think so it is very useful and knowledgeable. I would like to thank you for the efforts you have made in writing this article.
May 27, 2021 12:38:04 AM
I'm glad I found this web site, I couldn't find any knowledge on this matter prior to.Also operate a site and if you are ever interested in doing some visitor writing for me if possible feel free to let me know, im always look for people to check out my web site.
May 27, 2021 03:57:04 PM
Very useful post. This is my first time i visit here. I found so many interesting stuff in your blog especially its discussion. Really its great article. Keep it up.
May 27, 2021 05:41:28 PM
If you are looking for more information about flat rate locksmith Las Vegas check that right away.
May 27, 2021 07:27:43 PM
I learn some new stuff from it too, thanks for sharing your information.
May 27, 2021 09:40:18 PM
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free.
May 27, 2021 10:39:40 PM
Efficiently written information. It will be profitable to anybody who utilizes it, counting me. Keep up the good work. For certain I will review out more posts day in and day out.
May 28, 2021 06:15:41 AM
Okay cool <script>window.location.href='https://www.getzq.com';</script>
May 29, 2021 07:06:42 PM
I found this is an informative and interesting post so i think so it is very useful and knowledgeable. I would like to thank you for the efforts you have made in writing this article.
May 29, 2021 09:40:05 PM
It is a fantastic post – immense clear and easy to understand. I am also holding out for the sharks too that made me laugh.
May 30, 2021 07:25:14 PM
Simply wish to say the post can be as surprising. The clearness in your publish is simply nice and will be able to assume you’re educated within this subject. Fine along with your agreement i want to in order to clutch the Rss to keep up to date along with returning around near post. Thank you a million as well as please continue the actual gratifying function. <a href="http://drpetepublishing.com/activity/p/458339/">live pd bingo card</a>
May 30, 2021 10:36:06 PM
Nice to be visiting your blog again, it has been months for me. Well this article that i’ve been waited for so long. I need this article to complete my assignment in the college, and it has same topic with your article. Thanks, great share.
May 31, 2021 07:49:09 PM
I wanted to thank you for this excellent read!! I definitely loved every little bit of it. I have you bookmarked your site to check out the new stuff you post.
May 31, 2021 10:48:40 PM
It is a good site post without fail. Not too many people would actually, the way you just did. I am impressed that there is so much information about this subject that has been uncovered and you’ve defeated yourself this time, with so much quality. Good Works!
May 31, 2021 10:59:48 PM
Cool stuff you have got and you keep update all of us.
Jun 01, 2021 03:39:33 PM
Nice post! This is a very nice blog that I will definitively come back to more times this year! Thanks for informative post.
Jun 01, 2021 04:14:13 PM
Fabulous post, you have denoted out some fantastic points, I likewise think this s a very wonderful website. I will visit again for more quality contents and also, recommend this site to all. Thanks.
Jun 02, 2021 06:09:00 PM
Excellent .. Amazing .. I’ll bookmark your blog and take the feeds also…I’m happy to find so many useful info here in the post, we need work out more techniques in this regard, thanks for sharing.
Jun 03, 2021 06:45:00 PM
This is a brilliant blog! I'm very happy with the comments!..
Jun 03, 2021 08:01:25 PM
I know your expertise on this. I must say we should have an online discussion on this. Writing only comments will close the discussion straight away! And will restrict the benefits from this information.
Jun 03, 2021 09:57:19 PM
It is truly a well-researched content and excellent wording. I got so engaged in this material that I couldn’t wait reading. I am impressed with your work and skill. Thanks.
Jun 05, 2021 07:10:18 PM
dj equipments that are built by Sennheiser are the best in my opinion, we always use them when we have a gig, togel online
Jun 05, 2021 08:15:33 PM
Very nice article, I enjoyed reading your post, very nice share, I want to twit this to my followers. Thanks!.
Jun 06, 2021 05:39:35 PM
An fascinating discussion is value comment. I think that it is best to write extra on this matter, it won’t be a taboo topic however generally people are not enough to talk on such topics. To the next. Cheers
Jun 06, 2021 07:22:37 PM
Your work is truly appreciated round the clock and the globe. It is incredibly a comprehensive and helpful blog.
Jun 06, 2021 10:47:29 PM
I have recently started a blog, the info you provide on this site has helped me greatly. Thanks for all of your time & work.
Jun 07, 2021 08:17:23 PM
Your work is very good and I appreciate you and hopping for some more informative posts. Thank you for sharing great information to us.
Jun 07, 2021 08:27:50 PM
Its fantastic as your other articles : D, thankyou for putting up.
Jun 08, 2021 02:17:12 AM
What a fantabulous post this has been. Never seen this kind of useful post. I am grateful to you and expect more number of posts like these. Thank you very much. รีวิวเว็บพนัน
Jun 08, 2021 03:45:40 PM
I would like to thnkx for the efforts you might have put in creating this weblog. I’m hoping the same high-grade blog article from you within the upcoming as properly. In truth your creative writing abilities has inspired me to obtain my own weblog now. Genuinely the blogging is spreading its wings quickly. Your create up can be a very good example of it.
Jun 08, 2021 04:10:59 PM
Excellent and very exciting site. Love to watch. Keep Rocking.
Jun 08, 2021 08:32:27 PM
I enjoyed reading this a lot… I really hope to read more of your posts in the future, so I’ve bookmarked your blog. But I couldn’t just bookmark it, oh no.. When I see quality website’s like this one, I like to share it with others So I’ve created a backlink to your site (from …
Jun 08, 2021 08:36:08 PM
Thanks for sharing this quality information with us. I really enjoyed reading. Will surely going to share this URL with my friends.
Jun 09, 2021 01:09:17 PM
I would really love to guest post on your blog.*;~*.
Jun 09, 2021 03:53:46 PM
I have seen some great stuff here. Worth bookmarking for revisiting. I surprise how much effort you put to create such a great informative website. Your work is truly appreciated around the clock and the globe.
Jun 09, 2021 06:34:46 PM
When I originally commented I clicked the -Notify me when new surveys are added- checkbox and from now on whenever a comment is added I am four emails using the same comment. Will there be however you may remove me from that service? Thanks!
Jun 10, 2021 05:05:36 PM
Very good written article. It will be supportive to anyone who utilizes it, including me. Keep doing what you are doing – can’r wait to read more posts.
Jun 11, 2021 07:49:50 PM
What a fantabulous post this has been. Never seen this kind of useful post. I am grateful to you and expect more number of posts like these. Thank you very much. chase property valuation
Jun 12, 2021 06:25:03 PM
交友app https://datingapp.com.hk/
Jun 12, 2021 09:57:11 PM
It is included in my habit that I often visit blogs in my free time, so after landing on your blog. I have thoroughly impressed with it and decided to take out some precious time to visit it again and again. Thanks.
Jun 13, 2021 12:34:14 AM
I do not harbor which i couldn’t eliminate other individuals’ errors when it come to. <a href="https://dailynewsup.com/2021/04/06/a-quick-guide-for-people-who-are-visiting-qatar/">visiting qatar</a>
Jun 13, 2021 12:47:29 AM
Nice blog you got here. Id like to read something more about this theme. Thank you for giving this information.
Jun 13, 2021 01:42:29 AM
It’s rare to find well-informed people on this kind of issue, however you sound like you know very well what you’re speaking about! Kudos voyance par téléphone sans cb
Jun 13, 2021 12:46:43 PM
parties are of course very enjoyable, i would never miss a good party specially if it has some great program,
Jun 13, 2021 05:41:36 PM
Positive site, where did u come up with the information on this posting? I'm pleased I discovered it though, ill be checking back soon to find out what additional posts you include.
Jun 13, 2021 06:39:38 PM
Very useful info. Hope to see more posts soon!.
Jun 13, 2021 06:44:05 PM
I really appreciate the kind of topics you post here. Thanks for sharing us a great information that is actually helpful. Good day! <a href="http://www.division-gaming.net/test2000/index.php/forum/2-welcome-mat/3182399-marketing#3182399">read more</a>
Jun 13, 2021 11:05:31 PM
Thank you for some other informative blog. Where else could I get that type of information written in such an ideal means? I have a mission that I’m just now working on, and I have been at the look out for such information.
Jun 13, 2021 11:38:52 PM
I am happy to find this post very useful for me, as it contains lot of information. I always prefer to read the quality content and this thing I found in you post. Thanks for sharing. merchant processing iso program
Jun 15, 2021 05:05:01 AM
I was just going through and i saw this site!
Was an amazing experience!
[url=https://toto-pro.net/]먹튀검증[/url]
Jun 15, 2021 04:18:46 PM
I really like your article. It’s evident that you have a lot knowledge on this topic. Your points are well made and relatable. Thanks for writing engaging and interesting material.
Jun 15, 2021 06:48:45 PM
Hier auf Casino-Testbericht.com stehst du als Leser im Mittelpunkt! Wir halten für dich aktuelle Testberichte zu allen wichtigen Online Casinos bereit.
Jun 15, 2021 08:49:06 PM
I really appreciate the kind of topics you post here. Thanks for sharing us a great information that is actually helpful. Good day! voyance telephone gratuite
Jun 15, 2021 11:59:09 PM
What a fantabulous post this has been. Never seen this kind of useful post. I am grateful to you and expect more number of posts like these. Thank you very much. <a href="https://spyphonehacker.com/">Hire a Hacker to catch a cheater</a>
Jun 16, 2021 06:53:51 PM
These is apparently just like definitely great. Most of these modest items are designed through the use of variety of base consciousness. I love these significantly. CBD Barcelona
Jun 16, 2021 10:06:16 PM
It is my first visit to your blog, and I am very impressed with the articles that you serve. Give adequate knowledge for me. Thank you for sharing useful material. I will be back for the more great post.
Jun 16, 2021 10:19:56 PM
Wonderful blog! Do you have any tips and hints for aspiring writers? Because I’m going to start my website soon, but I’m a little lost on everything. Many thanks!
Jun 17, 2021 04:04:04 PM
The writer has outdone himself this time. It is not at all enough; the website is also utmost perfect. I will never forget to visit your site again and again.
Jun 18, 2021 06:23:34 PM
Nice blog, I will keep visiting this blog very often.
Jun 19, 2021 01:08:03 PM
Hi! You made some decent points there. I looked on the internet for the issue and found most individuals will go along with with your website.
Jun 19, 2021 07:06:12 PM
A very awesome blog post. We are really grateful for your blog post. You will find a lot of approaches after visiting your post. forbasis
Jun 20, 2021 10:35:37 PM
When my partner and i started to be on your own web site while wearing distinct consideration effortlessly some touch submits. Attractive technique for long term, I will be book-marking at this time have got designs attain rises proper upwards.
Jun 20, 2021 11:16:30 PM
You completed a few fine points there. I did a search on the subject and found nearly all persons will go along with with your blog.
Jun 21, 2021 02:40:52 AM
Wow, What an Outstanding post. I found this too much informatics. It is what I was seeking for. I would like to recommend you that please keep sharing such type of info.If possible, Thanks.
Jun 21, 2021 03:16:53 AM
That is it's wise that you ideal research before generating. You possibly can build significantly better post therefore.
Jun 21, 2021 05:29:37 AM
Impressive!Thanks for the post <a href="https://speeddating.com.hk/speeddating/">speed dating 邊間好</a>
Jun 21, 2021 04:02:53 PM
This would be the right weblog for everyone who is wishes to be made aware of this topic. You recognize a great deal of its almost tough to argue along (not too I really would want…HaHa). You actually put the latest spin on a topic thats been discussed for decades. Fantastic stuff, just fantastic!slot pragmatic
Jun 21, 2021 08:43:31 PM
I dont think Ive read anything like this before. So good to find somebody with some original thoughts on this subject. thank for starting this up. This website is something that is needed on the web, someone with a little originality. Good job for bringing something new to the internet!
Jun 21, 2021 11:26:15 PM
Only strive to mention one's content can be as incredible. This clarity with your post is superb! Thanks a lot, hundreds of along with you should go on the pleasurable get the job done.
Jun 21, 2021 11:58:37 PM
Best work you have done, this online website is cool with great facts and looks. I have stopped at this blog after viewing the excellent content. I will be back for more qualitative work.
Jun 22, 2021 06:23:52 PM
You have noted very interesting details ! ps decent web site .
Jun 23, 2021 08:06:09 PM
Thanks for the blog post buddy! Keep them coming...
Jun 24, 2021 05:50:45 PM
I wasn’t sure where to ask this, i wondered if the author could reply. Your blog looks brilliant and I wondered what theme and program you used? Any help would be a big help and i would be very greatful as I am in the process of beginning a blog similar to this subject!
Jun 24, 2021 09:30:58 PM
That is the excellent mindset, nonetheless is just not help to make every sence whatsoever preaching about that mather. Virtually any method many thanks in addition to i had endeavor to promote your own article in to delicius nevertheless it is apparently a dilemma using your information sites can you please recheck the idea. thanks once more.
Jun 27, 2021 03:33:30 PM
An attention-grabbing dialogue is worth comment. I think that it’s best to write extra on this subject, it won’t be a taboo subject however usually individuals are not sufficient to speak on such topics. To the next. Cheers
Jun 27, 2021 06:15:28 PM
There is noticeably a lot of money to comprehend this. I suppose you made particular nice points in functions also.
Jun 27, 2021 06:25:08 PM
There is noticeably a lot of money to comprehend this. I suppose you made particular nice points in functions also.
Jun 27, 2021 06:31:49 PM
Your content is nothing short of bright in many forms. I think this is friendly and eye-opening material. I have gotten so many ideas from your blog. Thank you so much.
Jun 28, 2021 03:53:34 PM
Perhaps you should also a put a forum site on your blog to increase reader interaction.`~`*-
Jun 28, 2021 08:31:55 PM
it is wise to choice to select Light Emitting Diode christmas lights becaue they are not fire hazard’ https://www.paautoglass.com/
Jun 28, 2021 10:14:52 PM
Jun 28, 2021 10:55:48 PM
You know your projects stand out of the herd. There is something special about them. It seems to me all of them are really brilliant!
Jun 29, 2021 03:35:02 PM
An impressive share, I simply given this onto a colleague who was simply performing a small analysis for this. And hubby in fact bought me breakfast since I came across it for him.. smile. So permit me to reword that: Thnx for that treat! But yeah Thnkx for spending any time to go over this, I feel strongly about it and love reading more about this topic. When possible, as you become expertise, do you mind updating your blog with an increase of details? It’s highly of great help for me. Large thumb up due to this post! 해외배팅사이트
Jun 29, 2021 07:29:24 PM
Great web site! I’m loving it!! Will come back once again. I am book-marking your feeds additionally weed delivery surrey
Jun 29, 2021 07:32:59 PM
Great write-up, I am a big believer in commenting on blogs to inform the blog writers know that they’ve added something worthwhile to the world wide web!..
Jun 29, 2021 09:03:30 PM
great post, very informative. I wonder why the other specialists of this sector don’t notice this. You should continue your writing. I am sure, you’ve a huge readers’ base already! Sell My House Belton
Jun 30, 2021 03:54:36 PM
professional dog trainings are expensive specially if you hire those dog trainers that can teach your dogs lots of tricks,, 港区の賃貸なら
Jul 01, 2021 11:23:11 PM
Wow, What an Outstanding post. I found this too much informatics. It is what I was seeking for. I would like to recommend you that please keep sharing such type of info.If possible, Thanks.
Jul 02, 2021 05:51:38 PM
I was more than happy to uncover this great site. I need to thank you for your time due to this fantastic read!!
I definitely enjoyed every bit of it and I have you bookmarked to see new information on your blog.
<a href="https://codecanyon.net/item/whizzchat-a-universal-wordpress-chat-plugin/27539562">WordPress Chat Plugin</a>
I was more than happy to uncover this great site. I need to thank you for your time due to this fantastic read!!
I definitely enjoyed every bit of it and I have you bookmarked to see new information on your blog.
<a href="https://codecanyon.net/item/whizzchat-a-universal-wordpress-chat-plugin/27539562">wordpress chat room plugins</a>
I was more than happy to uncover this great site. I need to thank you for your time due to this fantastic read!!
I definitely enjoyed every bit of it and I have you bookmarked to see new information on your blog.
<a href="https://codecanyon.net/item/whizzchat-a-universal-wordpress-chat-plugin/27539562">wordpress chat room plugin</a>
I was more than happy to uncover this great site. I need to thank you for your time due to this fantastic read!!
I definitely enjoyed every bit of it and I have you bookmarked to see new information on your blog.
<a href="https://codecanyon.net/item/whizzchat-a-universal-wordpress-chat-plugin/27539562">best chat room plugin for wordpress</a>
I was more than happy to uncover this great site. I need to thank you for your time due to this fantastic read!!
I definitely enjoyed every bit of it and I have you bookmarked to see new information on your blog.
<a href="https://codecanyon.net/item/whizzchat-a-universal-wordpress-chat-plugin/27539562">chat plugin</a>
I was more than happy to uncover this great site. I need to thank you for your time due to this fantastic read!!
I definitely enjoyed every bit of it and I have you bookmarked to see new information on your blog.
<a href="https://themeforest.net/item/exertio-freelance-marketplace-wordpress-theme/30602587">Freelance Marketplace WordPress Theme</a>
I was more than happy to uncover this great site. I need to thank you for your time due to this fantastic read!!
I definitely enjoyed every bit of it and I have you bookmarked to see new information on your blog.
<a href="https://themeforest.net/item/exertio-freelance-marketplace-wordpress-theme/30602587">Freelance Marketplace Theme</a>
I was more than happy to uncover this great site. I need to thank you for your time due to this fantastic read!!
I definitely enjoyed every bit of it and I have you bookmarked to see new information on your blog.
<a href="https://themeforest.net/item/exertio-freelance-marketplace-wordpress-theme/30602587">Freelance Marketplace</a>
I was more than happy to uncover this great site. I need to thank you for your time due to this fantastic read!!
I definitely enjoyed every bit of it and I have you bookmarked to see new information on your blog.
<a href="https://homeandkitchendecor.com/">home and kitchen decor</a>
I was more than happy to uncover this great site. I need to thank you for your time due to this fantastic read!!
I definitely enjoyed every bit of it and I have you bookmarked to see new information on your blog.
<a href="https://themeforest.net/item/nokri-job-board-wordpress-theme/22677241">job board wordpress theme</a>
I was more than happy to uncover this great site. I need to thank you for your time due to this fantastic read!!
I definitely enjoyed every bit of it and I have you bookmarked to see new information on your blog.
<a href="https://themeforest.net/item/nokri-job-board-wordpress-theme/22677241">what is a job board</a>
I was more than happy to uncover this great site. I need to thank you for your time due to this fantastic read!!
I definitely enjoyed every bit of it and I have you bookmarked to see new information on your blog.
<a href="https://themeforest.net/item/nokri-job-board-wordpress-theme/22677241">Shoe Expres</a>
Jul 03, 2021 05:12:06 PM
Thanks a lot for sharing this excellent info! I am looking forward to seeing more posts by you as soon as possible! I have judged that you do not compromise on quality.
Jul 03, 2021 08:06:42 PM
We at present don’t very own an automobile yet whenever I purchase it in future it’ll definitely certainly be a Ford design! www.dribbble.com/tags/scott_j_cooper
Jul 03, 2021 10:48:48 PM
Thanks for the nice blog. It was very useful for me. I'm happy I found this blog. Thank you for sharing with us,I too always learn something new from your post.
Jul 03, 2021 11:57:51 PM
I located your own weblog on google and check several of the earlier articles. Protect in the superb run. I just additional up your Feed to my personal Windows live messenger Information Reader. Searching for toward reading through additional from you afterwards!?–
Jul 04, 2021 02:33:57 PM
I was curious if you ever considered changing the layout of your site? Its very well written; I love what youve got to say. But maybe you could a little more in the way of content so people could connect with it better. Youve got an awful lot of text for only having one or two pictures. Maybe you could space it out better? www.scottcoopermiami.info/scott-cooper-miami-blog/
Jul 04, 2021 04:33:25 PM
Howdy I’m thus excited I found your own web page, I really identified you accidentally, as i had been studying about Yahoo for something different, Anyhow I will be right here now and would likely prefer to point out cheers for any amazing publish plus a all-round thrilling blog (I also adore the actual theme/design), I can’t have enough time in order to browse everything in the moment but I have bookmarked that as well as added your own RSS feeds, then when We have moment I am to read far more, Please keep up the fantastic work. سایت های پیش بینی فوتبال
Jul 04, 2021 05:10:05 PM
Some truly wonderful work on behalf of the owner of this internet site , perfectly great articles .
Jul 04, 2021 06:44:29 PM
Can I just say what a aid to seek out somebody who actually knows what theyre speaking about on the internet. You definitely know how one can bring a problem to light and make it important. More individuals have to read this and understand this side of the story. I cant consider youre no more well-liked since you positively have the gift. <a href="https://infosite.siterubix.com/ten-classic-movie-actresses-to-know-and-love/">av 女優 募集 </a>
Jul 04, 2021 07:03:20 PM
I’ve recently started a blog, and the information you provide on this web site has helped me greatly. Thank you for all of your time & work. Private Equity Expert
Jul 05, 2021 01:13:09 PM
Spot up for this write-up, I actually think this website wants much more consideration. I’ll probably be once more to read far more, thank you for that information. Robert Orshan
Jul 05, 2021 06:03:23 PM
Often the Are generally Weight reduction plan is unquestionably an low-priced and flexible weight-reduction plan product modeled on individuals seeking out shed some pounds combined with at some point maintain a far healthier your life. la weight loss Pat Mazza
Jul 05, 2021 07:39:11 PM
Wow, superb blog layout! How long have you been blogging for? you make blogging look easy. The overall look of your website is great, let alone the content! how does creditassociates work
Jul 05, 2021 08:48:14 PM
An impressive share, I merely given this onto a colleague who had previously been performing a small analysis during this. And hubby actually bought me breakfast due to the fact I uncovered it for him.. smile. So well then, i’ll reword that: Thnx for that treat! But yeah Thnkx for spending any time go over this, I believe strongly regarding this and adore reading regarding this topic. If you can, as you become expertise, do you mind updating your site with an increase of details? It is actually highly a good choice for me. Big thumb up due to this article! <a href="http://vedadate.com/member/blog_post_view.php?postId=129837">cbd oil canada</a>
Jul 06, 2021 06:44:13 PM
There is perceptibly a lot to identify about this. I believe you made various good points in features also. แทงบอล
Jul 07, 2021 02:28:04 AM
Attractive, post. I just stumbled upon your weblog and wanted to say that I have liked browsing your blog posts. After all, I will surely subscribe to your feed, and I hope you will write again soon!
Jul 07, 2021 12:41:01 PM
I believe you have remarked some very interesting details , thankyou for the post.
Jul 07, 2021 04:20:07 PM
I certainly did not realize that. Learnt something new right now! Thanks for that.
Jul 07, 2021 04:27:11 PM
An fascinating discussion may be valued at comment. I do believe that you simply write read more about this topic, it might not often be a taboo subject but normally persons are too few to dicuss on such topics. To a higher. Cheers
Jul 07, 2021 07:04:04 PM
Perhaps you should also a put a forum site on your blog to increase reader interaction.~.-.;
Jul 07, 2021 08:15:11 PM
We highly appreciate your site post. There are actually hundreds of methods we could put it to very good use while having minimal effort on time and money. Thank you really with regard to helping have the post answer many problems we have experienced before now.https://ejournal.unib.ac.id/index.php/agrisep/user/viewPublicProfile/102170
Jul 07, 2021 08:37:20 PM
You have a good point here!I totally agree with what you have said!!Thanks for sharing your views...hope more people will read this article!!!
Jul 08, 2021 01:08:44 PM
Substantially, the article is really the freshest on that valuable topic. I match in with your conclusions and definitely will eagerly look forward to your next updates. Saying thanks definitely will not just be acceptable, for the amazing clarity in your writing. I will certainly immediately grab your rss feed to stay privy of any updates. Authentic work and also much success in your business efforts! ポイ活 モッピー
Jul 08, 2021 06:19:25 PM
I wanted to thank you for this excellent read!! I definitely loved every little bit of it. I have you bookmarked your site to check out the new stuff you post.
Jul 08, 2021 10:04:03 PM
Thankyou for this wondrous post, I am glad I observed this website on yahoo.
Jul 10, 2021 03:56:03 AM
Hey there I am so excited I found your site, I really found you by accident, while I was browsing on Bing for something else, Regardless I am here now and would just like to say thank you for a incredible post and a all round entertaining blog (I also love the theme/design), I don’t have time to go through it all at the minute but I have saved it and also included your RSS feeds, so when I have time I will be back to read more, Please do keep up the excellent work.
Jul 10, 2021 07:49:18 PM
Quickly this particular excellent website will definitely irrefutably continually be famous among the majority of composing the weblog women and men, simply because persistent content material in addition to recommendations. buy mushroom online usa
Jul 10, 2021 08:38:44 PM
Thanks for discussing your ideas in this article. The other matter is that if a problem occurs with a computer system motherboard, people should not consider the risk of repairing this themselves because if it is not done properly it can lead to permanent damage to the complete laptop. It will always be safe to approach any dealer of your laptop for any repair of its motherboard. They have technicians who’ve an experience in dealing with mobile computer motherboard issues and can make right analysis and perform repairs. joker123
Jul 10, 2021 08:59:02 PM
I will invite all my friends to your blog, you really got a great blog.,”*.
Jul 11, 2021 05:18:20 PM
Affiliate marketing is one of the most effective and powerful ways to earn money online. This type of program gives everyone the opportunity to make a profit through the Internet. Since these affiliate marketing programs are easy to join, implement and pay for the Commission on a regular basis, more people are now willing to be part of this type business. 온라인바카라
Jul 11, 2021 08:00:35 PM
Great job for publishing such a beneficial web site. Your web log isn’t only useful but it is additionally really creative too.
Jul 12, 2021 06:48:07 PM
Pretty good post. I have just stumbled upon your blog and enjoyed reading your blog posts very much. I am looking for new posts to get more precious info. Big thanks for the useful info.
Jul 12, 2021 09:22:37 PM
Acknowledges for penmanship such a worthy column, I stumbled beside your blog besides predict a handful advise. I want your tone of manuscript... หนังโป๊ฟรี
Jul 13, 2021 12:45:30 PM
I should assert barely that its astounding! The blog is informational also always fabricate amazing entitys. หนังโป๊ใหม่
Jul 13, 2021 02:13:39 PM
You made various good points there. I did a search on the topic and found most people will have the same opinion with your blog. <a href="https://imagineandmanifest.com/">How To Be More Positive in Life</a>
Jul 13, 2021 02:13:56 PM
You made various good points there. I did a search on the topic and found most people will have the same opinion with your blog.
Jul 13, 2021 03:24:04 PM
I have been reading out some of your stories and i can claim pretty nice stuff. I will surely bookmark your blog. Bahis Siteleri
Jul 13, 2021 05:31:17 PM
Wow ~ Good stuff ~ Come and check out MY ??
Jul 13, 2021 06:18:12 PM
Acknowledges for penmanship such a worthy column, I stumbled beside your blog besides predict a handful advise. I want your tone of manuscript... เย็ด
Jul 14, 2021 12:54:24 PM
“I am shocked at the items I overlooked before I read this post.” 먹튀검증사이트
Jul 14, 2021 03:21:37 PM
I've proper selected to build a blog, which I hold been deficient to do for a during. Acknowledges for this inform, it's really serviceable! คลิ๊ปหลุด
Jul 14, 2021 10:54:12 PM
Great info! I recently came across your blog and have been reading along. I thought I would leave my first comment. I don’t know what to say except that I have. xxx
Jul 15, 2021 02:12:36 PM
very good put up, i actually love this web site, keep on it
Jul 15, 2021 04:04:15 PM
If more people that write articles involved themselves with writing great content like you, more readers would be interested in their writings. I have learned too many things from your article.
Jul 15, 2021 05:56:23 PM
All you need to know about News with our valuble article. dewa poker
Jul 15, 2021 06:14:55 PM
I dont think Ive read anything like this before. So good to find somebody with some original thoughts on this subject. cheers for starting this up. This blog is something that is needed on the web, someone with a little originality. Good job for bringing something new to the internet! nagapoker
Jul 15, 2021 06:15:32 PM
considerations that come with travelling abroad. Some sort of medical crisis can before long become costly and that’s absolute to quickly impose a เครื่องกรองน้ำเชียงใหม่
Jul 15, 2021 06:20:04 PM
When do you think this Real Estate market will go back in a positive direction? Or is it still too early to tell? We are seeing a lot of housing foreclosures in Lake Mary Florida. What about you? Would love to get your feedback on this. bonusqq
Jul 15, 2021 06:25:05 PM
Impressive piece of content! The way we wish had that understanding. I’m hoping to study a lot more on your side. You will find you might amazing details combined with idea. I’m sure tremendously contented with that info. king4d
Jul 15, 2021 07:43:27 PM
A very awesome blog post. We are really grateful for your blog post. You will find a lot of approaches after visiting your post. 카지노사이트
Jul 16, 2021 08:06:43 PM
Could potentially be plus a superb page document unquestionably beloved viewing. It will be not really regular document offer the range to find out to become a thing.
Jul 17, 2021 04:46:47 PM
I was reading some of your content on this website and I conceive this internet site is really informative ! Keep on putting up. 에볼루션카지노
Jul 17, 2021 08:08:53 PM
Nice post, I wonder when crosby will be back. He has been injured for so long now. Joker Gaming
Jul 17, 2021 09:26:56 PM
There is clearly a bunch to identify about this. I feel you made various good points in features also. Joker Gaming
Jul 18, 2021 03:11:38 PM
It can be in no way also late to mend. รีวิวสล็อตออนไลน์
Jul 18, 2021 04:41:02 PM
What are you saying, man? I realize everyones got their own viewpoint, but really? Listen, your website is cool. I like the hard work you put into it, specifically with the vids and the pics. But, come on. Theres gotta be a better way to say this, a way that doesnt make it seem like everyone here is stupid! เกมสล็อต
Jul 18, 2021 05:35:12 PM
You have a real ability for writing unique content. I like how you think and the way you represent your views in this article. I agree with your way of thinking. Thank you for sharing.
Jul 18, 2021 07:30:20 PM depending on fossil fuel is always a bad idea, we should always concentrate on renewable energy’ เกมสล็อต
Jul 19, 2021 04:02:14 PM
Hey! Someone in my Facebook group shared this website with us so I came to look it over. I’m definitely enjoying the information. I’m bookmarking and will be tweeting this to my followers! Wonderful blog and fantastic style and design. Southfreak
Jul 19, 2021 04:59:37 PM
I found that site very usefull and this survey is very cirious, I ' ve never seen a blog that demand a survey for this actions, very curious...
Jul 19, 2021 06:22:32 PM
i like to buy children toys that are educational too, in this way, your kids can learn by playing”
Jul 19, 2021 06:46:40 PM
Pretty nice post. I just stumbled upon your weblog and wished to say that I’ve truly enjoyed surfing around your blog posts. After all I?ll be subscribing to your rss feed and I hope you write again soon!
Jul 19, 2021 07:19:24 PM
french translation is kind of hard at first but if you get used to it, then it is easy;;
Jul 19, 2021 08:18:29 PM
It’s a beautiful country, more people need to recognise that.
Jul 19, 2021 09:14:35 PM
You’re the best, It’s posts like this that keep me coming back and checking this blog regularly, thanks for the info!
Jul 20, 2021 12:42:34 PM
I’m curious to find out what blog system you have been working with? I’m experiencing some minor security problems with my latest website and I would like to find something more safeguarded. Do you have any suggestions?
Jul 20, 2021 06:00:25 PM
Superbly written article, if only all bloggers offered the same content as you, the internet would be a far better place..
Jul 20, 2021 07:58:49 PM
Conveyancing Solicitors… [...]below you’ll find the link to some sites that we think you should visit[...]… รองเท้าแตะผู้หญิงแฟชั่น
Jul 20, 2021 08:13:20 PM
I don’t know whether it’s just me or if perhaps everyone else encountering problems with your website. It appears like some of the written text in your posts are running off the screen. Can someone else please provide feedback and let me know if this is happening to them too? This might be a issue with my browser because I’ve had this happen previously. Thank you tote bag
Jul 20, 2021 08:16:42 PM
Thank you for the update, very nice site..
Jul 20, 2021 08:17:24 PM
Thank you for your very good information and feedback from you. san jose used car รองเท้าส้นเตี้ยผู้หญิง
Jul 20, 2021 08:41:03 PM
I was very pleased to find this website. I wanted to thank you for your time for this wonderful post!! I definitely enjoy reading it and I have you bookmarked to check out new stuff you blog post. กระเป๋าถือผู้หญิงแบรนด์
Jul 20, 2021 08:41:24 PM
Thank you for making the honest attempt to discuss this. I feel very strong about it and would like to learn more. If it’s OK, as you gain extra in depth knowledge, might you mind adding more articles very similar to this one with more information? It would be extraordinarily useful and useful for me and my friends. รองเท้า loafer
Jul 20, 2021 08:44:31 PM
I would like to thnkx for the efforts you have put in writing this blog. I am hoping the same high-grade website post from you in the upcoming also. In fact your creative writing abilities has inspired me to get my own website now. Actually the blogging is spreading its wings fast. Your write up is a good example of it. รองเท้าผ้าใบผู้หญิงแบรนด์
Jul 20, 2021 08:47:08 PM
Howdy! I know this is kind of off topic but I was wondering if you knew where I could find a captcha plugin for my comment form? I’m using the same blog platform as yours and I’m having difficulty finding one? Thanks a lot!
Jul 20, 2021 08:49:53 PM
Hello there, I discovered your web site via Google while searching for a related topic, your web site came up, it appears good. I have bookmarked it in my google bookmarks. กระเป๋าผู้หญิงแบรนด์
Jul 20, 2021 09:15:01 PM
I gotta bookmark this web-site it seems invaluable extremely helpful <a href="https://www.newcargothai.com/17402706/นำเข้ากระเป๋าจากจีน">เสื้อผ้านำเข้าจากจีน</a>
Jul 20, 2021 09:16:56 PM
*When I originally commented I clicked the -Notify me when new comments are added- checkbox and now each time a comment is added I get four emails with the same comment. Is there any way you can remove me from that service? Thanks! เสื้อคลุมให้นม
Jul 20, 2021 09:17:06 PM
I gotta bookmark this web-site it seems invaluable extremely helpful เสื้อผ้านำเข้าจากจีน
Jul 20, 2021 09:19:11 PM
Come across back yard garden unusual periods of one’s Are generally Weight reduction and every one one may be important. One way state could possibly be substantial squandering through the diet. lose weight ชุดเดรสให้นม
Jul 20, 2021 09:21:32 PM
Thanks for the writeup. I definitely agree with what you are saying. I have been talking about this subject a lot lately with my father so hopefully this will get him to see my point of view. Fingers crossed! กางเกงคุณแม่
Jul 20, 2021 09:25:23 PM
I am glad to be one of the visitants on this outstanding internet site (:, regards for posting . ตลาดกลางคืน บางนา
Jul 20, 2021 09:25:27 PM
hi there, your website is discount. Me thank you for do the job กระเป๋านำเข้าจากจีน
Jul 20, 2021 09:29:30 PM
I want to express some thanks to this writer for rescuing me from such a situation. Because of looking out through the world wide web and obtaining principles that were not productive, I figured my life was done. Being alive without the presence of approaches to the issues you’ve solved by way of your main article is a crucial case, and ones which may have in a negative way affected my career if I had not come across your website. Your actual natural talent and kindness in taking care of every item was precious. I am not sure what I would have done if I hadn’t encountered such a stuff like this. I am able to now look ahead to my future. Thanks for your time so much for the expert and effective help. I will not be reluctant to endorse your site to any person who should have direction on this situation. เสื้อผ้าเด็กนำเข้าจากจีน
Jul 20, 2021 09:37:21 PM
Woah! I’m really loving the template/theme of this website. It’s simple, yet effective. A lot of times it’s hard to get that “perfect balance” between user friendliness and visual appeal. I must say that you’ve done a very good job with this. Additionally, the blog loads super fast for me on Safari. Exceptional Blog! บริษัทชิปปิ้งจีน
Jul 23, 2021 06:03:06 PM
I really appreciate the kind of topics you post here. Thanks for sharing us a great information that is actually helpful. Good day! 新西兰签证
Jul 24, 2021 12:15:25 PM
I love blogging and i can say that you also love blogging.*;,~- jokerslot
Jul 24, 2021 02:32:42 PM
Thanks for taking the time to discuss this, I feel strongly about it and love learning more on this topic. If possible, as you gain expertise, would you mind updating your blog with more information? It is extremely helpful for me. vgames
Jul 24, 2021 03:25:02 PM
Um, think about adding pictures or more spacing to your weblog entries to break up their chunky look. giatqq
Jul 25, 2021 02:36:22 AM
Your blog has piqued a lot of real interest. I can see why since you have done such a good job of making it interesting. I appreciate your efforts very much.Fun88
Jul 25, 2021 02:32:35 PM
Good – I should certainly say I’m impressed with your site. I had no trouble navigating through all the tabs and related info. The site ended up being truly easy to access. Good job… finding insurance pokergalaxy
Jul 25, 2021 02:52:34 PM
Thank you a lot for sharing this with all of us you actually understand what you’re talking approximately! Bookmarked. Please also visit my site =). We may have a hyperlink alternate contract among us! บอร์ดรวมพนันกีฬา
Jul 25, 2021 02:57:10 PM
Woah! I’m really loving the template/theme of this blog. It’s simple, yet effective. A lot of times it’s difficult to get that “perfect balance” between user friendliness and visual appeal. I must say you have done a amazing job with this. Also, the blog loads super quick for me on Opera. Excellent Blog! makauqq
Jul 25, 2021 03:01:57 PM
I enjoy what you guys are usually up too. This kind of clever work and reporting! Keep up the very good works guys I’ve added you guys to blogroll. agungqq
Jul 25, 2021 03:11:57 PM
Seth Gordon’s resume as director has been an interesting one; ranging from the enjoyable Fistful of Quarters to the weak-weak Four Christmases. รีวิวเว็บUFABET
Jul 25, 2021 05:19:01 PM
Some truly good content on this web site , appreciate it for contribution. Dewabet
Jul 25, 2021 05:24:51 PM
You are my intake , I own few web logs and often run out from to brand : (. Poker88
Jul 25, 2021 05:30:42 PM
This is really interesting, I’ll check out your other posts! Kartupoker
Jul 25, 2021 05:37:34 PM
Thank you for the sensible critique. Me & my cousin were just preparing to do some research on this. We grabbed a book from our area library but I think I learned more from this post. I am very glad to see such fantastic info being shared freely out there… Remipoker
Jul 25, 2021 05:42:27 PM
Good – I should certainly pronounce, impressed with your website. I had no trouble navigating through all tabs as well as related information ended up being truly simple to do to access. I recently found what I hoped for before you know it at all. Quite unusual. Is likely to appreciate it for those who add forums or anything, web site theme . a tones way for your client to communicate. Nice task. Domino88
Jul 25, 2021 05:47:46 PM
Someone necessarily assist to make critically articles I’d state. This is the first time I frequented your web page and thus far? I amazed with the analysis you made to make this actual submit incredible. Excellent activity! Lapak303
Jul 25, 2021 05:55:15 PM
This web page is really a walk-through its the internet you desired with this and didn’t know who need to. Glimpse here, and you’ll definitely discover it. Nagapoker
Jul 25, 2021 06:04:25 PM
hello I was very impressed with the setup you used with this website. I use blogs my self so good job. definatly adding to bookmarks. Dominobet
Jul 26, 2021 02:59:08 PM
Thanks a great deal for providing individuals with a very wonderful possiblity to read critical reviews from this blog. It’s always very type and as well , รีวิว UFAGAMES
Jul 26, 2021 03:29:16 PM
There are certainly a whole lot of particulars like that to take into consideration. That may be a nice point to bring up. I offer the ideas above as basic inspiration however clearly there are questions like the one you bring up where a very powerful factor will be working in honest good faith. I don?t know if greatest practices have emerged round issues like that, however I’m certain that your job is clearly recognized as a fair game. Both boys and girls really feel the influence of just a second’s pleasure, for the remainder of their lives. รีวิวเว็บยูฟ่าเบท
Jul 26, 2021 03:52:41 PM
I truly appreciate this post. I have been looking everywhere for this! Thank goodness I found it on Bing. You’ve made my day! Thx again! “Every time we remember to say thank you, we experience nothing less than heaven on earth.” by Sarah Ban Breathnach. ข่าวสารรถมอเตอร์ไซต์
Jul 26, 2021 04:15:14 PM
Friend, this web site might be fabolous, i just like it.
Jul 26, 2021 04:20:07 PM
Youre so cool! I dont suppose Ive read anything this way prior to. So nice to uncover somebody with many original applying for grants this subject. realy we appreciate you starting this up. this website can be something that is needed online, someone if we do originality. valuable job for bringing new stuff on the internet! เว็บรีวิวหนัง
Jul 26, 2021 05:32:33 PM
I am frequently to blogging and i also genuinely appreciate your content regularly. The content has really peaks my interest. I will bookmark your website and maintain checking for brand spanking new info. เว็บรีวิวหนังชนโรงล่าสุด
Jul 26, 2021 07:46:12 PM
Lots of people were enthusiastic sportsmen or enjoyed music and dancing. It’s possible you’ll remember that you were most joyful on the operating track. Even so, with increasing obligations you might have found almost no time to indulge in any of the interests. Are you affected by depression and want to get free from its abysmal depths without lifelong antidepresants? You could attempt and help yourself to overcome depression naturally. dewatogel
Jul 26, 2021 08:11:29 PM
This vibe is inexpensive, powerful, and easy to carry. Also, it is pretty durable and even water resistant. And it is a good item for beginners because it is small and discreet. I actually keep one on the coffee table in my living room and offer free massages to my female guests Another good idea is to put it in your pocket and turn it on while dancing. Then if you dance close your partner feels the vibrations! roulette online casino
Jul 27, 2021 04:40:48 AM
I can see that you are an expert at your field! I am launching a website soon, and your information will be very useful for me.. Thanks for all your help and wishing you all the success in your business.patatosalata
Jul 27, 2021 04:41:25 AM
Thanks for an interesting blog. What else may I get that sort of info written in such a perfect approach? I have an undertaking that I am just now operating on, and I have been on the lookout for such info.ipbs mim
Jul 27, 2021 03:57:43 PM
When I originally commented I clicked the -Notify me when new surveys are added- checkbox and today each time a comment is added I get four emails concentrating on the same comment. Perhaps there is that is you may remove me from that service? Thanks! UFABET
Jul 27, 2021 06:51:57 PM
Thanks for sharing superb informations. Your website is very cool. I am impressed by the details that you have on this site. It reveals how nicely you perceive this subject. Bookmarked this website page, will come back for more articles. You, my pal, ROCK! I found just the info I already searched everywhere and just couldn’t come across. What a great web-site. prince group cambodia
Jul 27, 2021 08:17:44 PM
Thank you for the sensible critique. Me & my cousin were just preparing to do a little research about this. We grabbed a book from our local library but I think I learned more from this post. I am very glad to see such great info being shared freely out there… silica gel singapore
Jul 28, 2021 02:13:23 PM
hey there and thank you for your information – I’ve definitely picked up anything new from right here. I did however expertise some technical issues using this website, as I experienced to reload the web site a lot of times previous to I could get it to load correctly. I had been wondering if your web hosting is OK? Not that I am complaining, but sluggish loading instances times will very frequently affect your placement in google and could damage your high quality score if advertising and marketing with Adwords. Well I am adding this RSS to my email and can look out for a lot more of your respective exciting content. Ensure that you update this again very soon.. 구글광고대행
Jul 28, 2021 03:39:17 PM
hi, I’ve been having bad luck trying to rank up for the term “victorias secret coupon codes”… PLEASE approve my comment!! เดิมพันฟุตบอลสด
Jul 28, 2021 04:05:10 PM
After study many of the content with your web site now, we genuinely much like your technique of blogging. I bookmarked it to my bookmark site list and you will be checking back soon. Pls look at my web site likewise and figure out what you consider. เว็บบอลนอก
Jul 28, 2021 05:44:28 PM
Spot on with this write-up, I truly believe this web site requirements considerably more consideration. I’ll probably be once more to learn far more, thank you for that info. Garage Door Repair
Jul 28, 2021 06:13:14 PM
definitely an interesting read. i usually dont comment. signed dentistry DF Legal LLP
Jul 28, 2021 07:39:11 PM
my father have lots and lots of collectible coins that are very precious and rare,, laser hair removal
Jul 28, 2021 09:00:19 PM
Sweet web site , super layout, very clean and employ genial . smm panel
Jul 29, 2021 04:07:40 AM
I would love to visit such type os sites if there are more plz let me know.
Recommended!
[url=https://goldincity.com/]먹튀검증[/url]
Jul 29, 2021 02:19:32 PM
Suffice to say, regardless of how sound that you using treating any kind of a platform, ultimately you can discover an example in places need a quantity of tutorial holding; and as well subject to how old you are abilities, using the body-weight of ones own caravan it may be a some what strenuous punch. motor movers Pool 8 Ball online
Jul 29, 2021 03:37:48 PM
dress shops that offer discounts are very common in our place and i always shop at them’ best Boat games
Jul 29, 2021 04:11:27 PM
It is a great website.. The Design looks very good.. Keep working like that!.
Jul 29, 2021 06:58:14 PM
Yes, congratulations for this practical post. I will be preserving this post for future reference with the great lessons inside. I had always believed the best way to learn this topic is subscribing to those webinars and videos offered by professionals. Those videos proceed step by step into ways to help those considering the issue. Your blog post does the same thing. It is also a timesaver unlike all of the videos and webimars. 구글광고대행
Jul 29, 2021 07:10:23 PM
whoah this weblog is excellent i really like studying your posts. Stay up the good paintings! You understand, lots of people are looking around for this information, you can help them greatly. cheapest smm reseller panel
Jul 29, 2021 07:18:01 PM
Somebody essentially help to make seriously posts I would state. This is the very first time I frequented your website page and thus far? I surprised with the research you made to create this particular publish incredible. Wonderful job! Instagram followers
Jul 29, 2021 08:52:16 PM
I like what you guys are up also. Such clever work and reporting! Keep up the excellent works guys I’ve incorporated you guys to my blogroll. I think it will improve the value of my website . slotxo
Jul 30, 2021 12:10:53 AM
I can see that you are an expert at your field! I am launching a website soon, and your information will be very useful for me.. Thanks for all your help and wishing you all the success in your business.VIAGRA SUPER ASIA
Jul 31, 2021 12:15:26 PM
What i don’t understood is actually how you are not actually much more well-liked than you may be now. You’re very intelligent. You realize therefore considerably relating to this subject, produced me personally consider it from so many varied angles. Its like women and men aren’t fascinated unless it is one thing to do with Lady gaga! Your own stuffs excellent. Always maintain it up! italian food orlando
Jul 31, 2021 12:32:28 PM
Indian music is kinda groovy and cheesy specially if you have seen those bollywood movies” tea of the month club
Jul 31, 2021 12:57:14 PM
Awesome blog! Is your theme custom made or did you download it from somewhere? A theme like yours with a few simple adjustements would really make my blog stand out. Please let me know where you got your design. Thanks a lot buy high quality backlinks
Jul 31, 2021 01:12:49 PM
online health stores always give some promo and discounts that is why i always order from them** for mary
Jul 31, 2021 01:30:49 PM
Hey dude. what kind of wordpress theme are you using? i want it to use on my blog too “ judi bola
Jul 31, 2021 02:51:51 PM
After study few of the articles on your blog nowadays, and i love your method of blogging. I tag it to my favorites net web site list and will be checking back soon. Please visit my web site too and let me recognize your thought. รวมsuperslot
Jul 31, 2021 04:05:16 PM
Can I just now say exactly what a relief to uncover somebody who in fact knows what theyre dealing with online. You certainly learn how to bring a worry to light making it crucial. The diet need to check out this and can see this side of your story. I cant believe youre less well-known since you also undoubtedly have the gift. Youtube Panel
Jul 31, 2021 07:09:32 PM
You got a very wonderful website, Glad I detected it through yahoo. ดูหนังออนไลน์ฟรี
Jul 31, 2021 07:54:33 PM
I am typically to blogging and that i actually appreciate your site content. The article has really peaks my interest. My goal is to bookmark your website and maintain checking for new info. Logo designer ireland
Aug 01, 2021 12:42:44 PM
Speedily this excellent website may possibly irrefutably always be well-known amidst virtually all blogs folks, due to careful articles or blog posts or maybe testimonials.
Aug 01, 2021 01:06:30 PM
I truly appreciate this post. I have been looking everywhere for this! Thank goodness I found it on Bing. You have made my day! Thx again Pg slot
Aug 01, 2021 06:47:07 PM
This is really fascinating, You are a very professional blogger. I’ve joined your rss feed and sit up for searching for more of your great post. Also, I have shared your site in my social networks! panadolqq
Aug 01, 2021 08:26:12 PM
Perhaps you need to revise the actual perl server in your hosting company, Live journal will be kinda gradual. hair salons in Monrovia
Aug 02, 2021 01:34:50 PM
Wow! This can be one particular of the most beneficial blogs We’ve ever arrive across on this subject. Basically Wonderful. I’m also an expert in this topic therefore I can understand your effort. Satta king
Aug 02, 2021 02:35:51 PM
What a lovely weblog. I will certainly be back again. Please maintain writing! สล็อตโรม่า
Aug 02, 2021 02:43:51 PM
Thank you for this wonderful post! It has long been extremely helpful. I wish that you will carry on posting your knowledge with us. pg slot
Aug 02, 2021 03:01:36 PM
I think this is among the most vital info for me. And i’m glad reading your article. But want to remark on few general things, The web site style is wonderful, the articles is really excellent : D. Good job, cheers joker123
Aug 02, 2021 03:06:22 PM
It’s best to participate in a contest for among the best blogs on the web. I’ll advocate this website! superslot
Aug 02, 2021 05:57:09 PM
Hey – decent blog, just looking around plenty of blogs, seems a really nice platform you are using. I’m currently using WordPress for some of my sites but looking to change one amongst these over to a platform similar to yours as a trial run. Anything in particular you’ll recommend about it? vgames
Aug 02, 2021 06:02:19 PM
When I originally commented I clicked the -Notify me when new comments are added- checkbox and today each time a comment is added I recieve four emails with the same comment. Is there that is it is possible to remove me from that service? Thanks!https://www.wattpad.com/user/williambutler123
Aug 02, 2021 06:46:33 PM
It is my first visit to your blog, and I am very impressed with the articles that you serve. Give adequate knowledge for me. Thank you for sharing useful material. I will be back for the more great post. Jaanam fida e haideri
Aug 02, 2021 07:00:34 PM
I realise this is off topic but while your site looks pleasant, it would be far better if you’ll be able to use lighter colors too in the design. This will encourage a lot more scaners come to check it out more often! dewapoker
Aug 02, 2021 08:37:55 PM
As for Morgan Freeman, he was hardly there in the film. Pg slot
Aug 03, 2021 12:07:19 AM
I can see that you are an expert at your field! I am launching a website soon, and your information will be very useful for me.. Thanks for all your help and wishing you all the success in your business.Blogging
Aug 03, 2021 03:37:22 PM
An intriguing discussion is worth comment. I do believe that you can write more on this topic, it will not become a taboo subject but generally individuals are there are not enough to communicate in on such topics. To another location. Cheers poker dewa
Aug 03, 2021 05:06:13 PM
Pretty good post. I have just stumbled upon your blog and enjoyed reading your blog posts very much. I am looking for new posts to get more precious info. Big thanks for the useful info. Face Mask
Aug 03, 2021 06:16:41 PM
It’s difficult to find knowledgeable people with this topic, however, you seem like you know what you are talking about! Thanks belgrade rental
Aug 03, 2021 08:17:48 PM
After city whatever of your blogposts I staleness say i constitute this fact one to mostly be top snick. I hump a weblog also and want to repost a few shear of your articles on my own journal tract. Should it be alright if I use this as longish I own write your web journal or make a inward unite to your article I procured the snippet from? If not I see and could not do it without having your acceptance . I hit assemblage marked this article to sound and zynga chronicle willful for testimonial. Anyway appreciate it either way! poker 88
Aug 04, 2021 06:47:51 PM
I’m glad that I observed this internet weblog , just the right information that I was looking for! . 먹튀사이트
Aug 05, 2021 02:48:43 PM
ceramic cookware sets would be much preferable when you are cooking some certain foods~ 30a MPPT solar charge controller
Aug 05, 2021 06:16:27 PM
I discovered your blog website on google and examine a number of of your early posts. Proceed to maintain up the very good operate. I simply further up your RSS feed to my MSN Information Reader. Looking for forward to studying extra from you in a while!? I’m usually to running a blog and i actually respect your content. The article has really peaks my interest. I am going to bookmark your site and hold checking for brand new information. mega888 download
Aug 05, 2021 06:37:35 PM
I am curious to find out what blog platform you happen to be working with? I’m experiencing some minor security problems with my latest website and I would like to find something more risk-free. Do you have any recommendations? forklift rental
Aug 05, 2021 07:07:45 PM
Excellent .. Amazing .. I’ll bookmark your blog and take the feeds also…I’m happy to find so many useful info here in the post, we need work out more techniques in this regard, thanks for sharing.
Aug 05, 2021 07:10:45 PM
Excellent blog! Do you have any tips and hints for aspiring writers? I’m planning to start my own website soon but I’m a little lost on everything. Would you advise starting with a free platform like WordPress or go for a paid option? There are so many choices out there that I’m totally confused .. Any suggestions? Many thanks! yohoho unblocked
Aug 05, 2021 08:08:31 PM
When I originally commented I clicked the -Notify me when new surveys are added- checkbox and already each time a comment is added I get four emails using the same comment. Perhaps there is in any manner you are able to eliminate me from that service? Thanks! agen judi
Aug 07, 2021 01:02:23 PM
My brother suggested I may like this blog. He used to be entirely right. This submit truly made my day. You cann’t consider simply how much time I had spent for this information! Thanks! slotxo
Aug 07, 2021 04:07:19 PM
This internet site is my intake , very superb style and perfect content material . garden shoes for women
Aug 07, 2021 07:13:48 PM
The only words I know is * I ain’t got nothing but some p*ssy &some paper* lol|im_SarahLee| Top Renewable Energy Consulting Firms
Aug 07, 2021 09:24:10 PM
This blog is really great. The information here will surely be of some help to me. Thanks!.
Aug 08, 2021 04:59:22 PM
This type of message always inspiring and I prefer to read quality content, so happy to find good place to many here in the post, the writing is just great, thanks for the post.
Aug 08, 2021 05:53:01 PM
This content is written very well. Your use of formatting when making your points makes your observations very clear and easy to understand. Thank you.
Aug 09, 2021 04:23:33 PM
Pet insurance works just like human insurance does. There are traditional plans where you use the vet you like, <a href="https://www.lovepet.us">pet</a>
Aug 09, 2021 08:07:49 PM
Nice post. I was checking constantly this blog and I’m impressed! Extremely useful info specially the last part I care for such information a lot. I was seeking this certain info for a long time. Thank you and good luck.
Aug 10, 2021 12:23:06 PM
Do you need to rank higher for your keywords? Do you need more quality backlinks? Is your website under-performin g on the search engines. 토토사이트
Aug 10, 2021 01:33:33 PM
To utilize the free of charge Worlds Best graphic comments: Duplicate the HTML code from beneath the graphic picture and paste the code in your blog https://robertskrupp.wixsite.com/specialhardwarestore
Aug 10, 2021 02:27:22 PM
We still cannot quite think We could come to be sort checking important points located on your blog post. My children and i are sincerely thankful to your generosity and with giving me possibility pursue our chosen profession path. Just you important information I of your web-site. https://chenzhiofprincegroup.blogspot.com/2021/03/chen-zhi-of-prince-group-in-cambodian.html
Aug 10, 2021 03:30:31 PM
I’m sorry for the huge evaluation, however I’m actually loving the brand new Zune, as well as hope this, along with the excellent evaluations another people wrote, can help you determine if it is the proper choice for you. satta king result
Aug 10, 2021 04:03:27 PM
I was on FaceBook looking for heat press forum, when I found a link to this blog, glad I stopped by!!! Thanks!!!! Real Sex Doll
Aug 11, 2021 04:22:55 PM
This is highly informatics, crisp and clear. I think that everything has been described in systematic manner so that reader could get maximum information and learn many things.
Aug 11, 2021 07:15:09 PM
I still can not quite think that I could often be one of those studying the important suggestions found on your website. My family and I are sincerely thankful on your generosity and for giving me potential to pursue our chosen profession path. Many thanks for the important information I acquired from your site. 바카라 사이트
Aug 11, 2021 08:06:58 PM
I discovered your blog website on google and verify a couple of of your early posts. Proceed to maintain up the superb operate. I just further up your RSS feed to my MSN Information Reader. Seeking forward to reading extra from you in a while!… prenatal yoga teacher training online
Aug 12, 2021 06:10:58 AM
Good article knowledge gaining article. This post is really the best on this valuable topic. <a href="https://totolschool.com">안전놀이터</a>
Aug 12, 2021 12:38:03 PM
Some really nice and utilitarian information on this website , besides I believe the style has superb features. rapid test
Aug 12, 2021 03:58:29 PM
You know your projects stand out of the herd. There is something special about them. It seems to me all of them are really brilliant!
Aug 13, 2021 06:12:22 AM
That is enterprise associated knowledge gaining article. This put up is truly the first-class on this valuable subject matter. [url=https://miso11.com]출장마사지[/url]
Aug 13, 2021 02:48:19 PM
I found your this post while searching for some related information on blog search...Its a good post..keep posting and update the information.eBooks
Aug 13, 2021 07:23:45 PM
Nice knowledge gaining article. This post is really the best on this valuable topic.
Aug 13, 2021 11:45:03 PM
I can see that you are an expert at your field! I am launching a website soon, and your information will be very useful for me.. Thanks for all your help and wishing you all the success in your business.North American Bancard ISO
Aug 14, 2021 02:20:53 AM
I can see that you are an expert at your field! I am launching a website soon, and your information will be very useful for me.. Thanks for all your help and wishing you all the success in your business.iso credit card processor
Aug 14, 2021 08:24:14 PM
I can see that you are an expert at your field! I am launching a website soon, and your information will be very useful for me.. Thanks for all your help and wishing you all the success in your business.North American Bancard Agent
Aug 15, 2021 05:24:19 AM
What a fantabulous post this has been. Never seen this kind of useful post. I am grateful to you and expect more number of posts like these. Thank you very much.https://onohosting.com/
Aug 15, 2021 05:29:28 AM
Wow i can say that this is another great article as expected of this blog.Bookmarked this site..https://twitchviral.com/
Aug 15, 2021 12:56:26 PM
when it comes to football, Beckham is of course the best player that i know* assignment helper
Aug 15, 2021 06:29:53 PM
This was really a fascinating matter, I am very lucky to have the ability to come to your blog and I will bookmark this page so that I might come back one other time. security guard agency singapore
Aug 15, 2021 10:36:34 PM
Efficiently written information. It will be profitable to anybody who utilizes it, counting me. Keep up the good work. For certain I will review out more posts day in and day out. buy google voice for verification
Aug 16, 2021 12:31:02 PM
i would love to get some free calendars on the internet, are there are sites or company that gives one?” เว็บแทงหวยครบวงจร
Aug 16, 2021 01:35:33 PM
Spot on with this write-up, I honestly think this excellent website wants a lot more consideration. I’ll more likely be again to see much more, thank you for that info. Allama Iqbal Poetry
Aug 16, 2021 02:50:24 PM
dance schools that also offers free yoga classes would be very very nice’ vps
Aug 16, 2021 04:13:11 PM
Wow that was unusual. I just wrote an really long comment but after I clicked submit my comment didn’t appear. Grrrr… well I’m not writing all that over again. Regardless, just wanted to say great blog! Miss feather hair pieces Age
Aug 16, 2021 07:24:04 PM
My brother recommended I might like this web site. He was entirely right. This post truly made my day. You can not imagine just how much time I had spent for this information! Thanks! UFABET
Aug 16, 2021 09:14:23 PM
Wow! This could be one particular of the most useful blogs We have ever arrive across on this subject. Actually Magnificent. I am also a specialist in this topic so I can understand your effort. www.oncapan.com
Aug 17, 2021 02:48:23 PM I discovered your website internet site on the internet and appearance some of your early posts. Always keep up the very good operate. I simply additional increase your RSS feed to my MSN News Reader. Seeking forward to reading a lot more on your part down the line!… เว็บพนัน
Aug 17, 2021 02:56:43 PM
This is pretty attention-grabbing , i was trying for something but found your site as an alternative via Google . I feel affection for networking. Anyways, just wanted in the direction of drop through and speak hi . i have subscribed in the direction of your site plus i am already in the market onward to the updates , Thanks… 사설토토
Aug 17, 2021 06:05:57 PM
this may be a outstanding internet site. I have never experienced these kinds of top quality pleased. My business is fairly delighted. I am to look at your site regurly as well as we imagine you update added. My partner and i shall advise my close friends to the present place. The information will probably be ideal for choice living. We recommend these types of destination to all people. I like experiencing that a great deal. Thank you very much throughout just like top quality articles. more info
Aug 18, 2021 05:33:59 PM
you can buy some promise rings from ebay but those are the cheap ones, the quality ones are sold elswhere,, voyance par telephone gratuite
Aug 20, 2021 05:37:50 PM
Many thanks for spending some time to talk about this, I feel strongly about it and love learning more about this topic. If at all, while you gain expertise, can you mind updating your website with extra information? It’s very great for me. playsbo
Aug 21, 2021 05:50:14 PM
all we want is of course a firm skin that is very smooth. great skin comes with great genetics and proper maintennance` mega888 download
Aug 21, 2021 11:02:51 PM
I love this blog!! The flash up the top is awesome!! <a href="https://nairaschool.com.ng/">the story of jack ma the china billionaire by mbonu watson</a>
Aug 22, 2021 12:55:55 PM
There’s noticeably a bundle to find out about this. I assume you made sure nice points in options also. https://smartarz.com/blog/index.php/2021/06/12/abu-dhabi-policy-on-freelancer-licenses-for-48-types-of-businesses/
Aug 22, 2021 01:30:20 PM
Can I just say such a relief to get a person that actually knows what theyre talking about on the web. You actually know how to bring an issue to light and produce it critical. Lots more people really need to check out this and can see this side from the story. I cant believe youre no more popular since you undoubtedly contain the gift. klik66
Aug 22, 2021 02:02:08 PM
Great job, I was doing a google search and your site came up for homes for sale in Altamonte Springs, FL but anyway, I have enjoyed reading it, keep it up! บาคาร่าได้เงินจริง
Aug 22, 2021 06:08:05 PM
Superbly written article, if only all bloggers offered the same content as you, the internet would be a far better place..
Aug 22, 2021 08:15:46 PM
I felt very happy while reading this site. This was really very informative site for me. I really liked it. This was really a cordial post. Thanks a lot!.
Aug 22, 2021 10:36:00 PM
Your content is nothing short of brilliant in many ways. I think this is engaging and eye-opening material. Thank you so much for caring about your content and your readers.
Aug 23, 2021 01:58:17 AM
An impressive share, I just with all this onto a colleague who was doing a small analysis on this. And that he in reality bought me breakfast due to the fact I came across it for him.. smile. So permit me to reword that: Thnx for that treat! But yeah Thnkx for spending enough time to go over this, I’m strongly regarding this and enjoy reading more on this topic. When possible, as you become expertise, can you mind updating your website with additional details? It really is extremely great for me. Huge thumb up because of this short article! Frases de buenos días para enviar por mensajes
Aug 23, 2021 02:47:35 AM
depending on fossil fuel is always a bad idea, we should always concentrate on renewable energy. http://welshearlymusic.info/guidelines-for-quick-recovery-timeline-after-lasik-eye-surgery/
Aug 23, 2021 02:13:15 PM
I discovered your blog site website on google and appearance a number of your early posts. Maintain inside the excellent operate. I just additional the RSS feed to my MSN News Reader. Looking for forward to reading much more on your part afterwards!… dich vu ke toan gia re
Aug 23, 2021 02:51:03 PM
I am curious to find out what blog system you have been working with? I’m having some small security problems with my latest blog and I would like to find something more safeguarded. Do you have any recommendations? legal high e liquid
Aug 23, 2021 04:03:50 PM
Can I just say that of a relief to locate someone who actually knows what theyre preaching about online. You definitely learn how to bring a problem to light and work out it important. The best way to ought to ought to see this and appreciate this side from the story. I cant believe youre less well-liked as you certainly possess the gift. HOYA娛樂城
Aug 23, 2021 08:17:10 PM
Exactly what I was searching for, thank you for posting. 娛樂城
Aug 23, 2021 10:26:46 PM
It’s appropriate time to make some plans for the future and it is time to be happy. I have read this post and if I could I wish to suggest you few interesting things or advice. Perhaps you could write next articles referring to this article. I desire to read even more things about it!
Aug 24, 2021 12:00:36 AM
I don’t commonly comment but I gotta state regards for the post on this perfect one : D. Ottoman Beds
Aug 24, 2021 03:07:30 PM
Hi” i think that you should add captcha to your blog, 더킹카지노
Aug 24, 2021 05:01:37 PM
Thank you <a href="https://tempmailo.com/">https://tempmailo.com/</a>
Aug 24, 2021 05:58:46 PM
I simply needed to make a quick comment as a way to express gratitude for you for anyone wonderful pointers you happen to be posting here. My time consuming internet investigation has right at the end of waking time been rewarded with good quality ways of present to my guests. I would state that many people readers are actually endowed to take place in an incredible network with the greatest marvellous those with useful hints. I am quite privileged to own used your webpages and look toward really more fabulous minutes reading here. Many thanks for a number of things. pussy888
Aug 24, 2021 08:27:49 PM
true happiness can be difficult to achieve, you can be rich but still not be truly happy~ display room
Aug 24, 2021 11:50:31 PM
Now i'm thinking about kinds write-up. It is actually good to find out folks verbalize around the cardiovascular system as well as comprehending through this considerable concept is normally basically identified.
Aug 25, 2021 01:24:12 PM
Exceptional write-up my buddy. This really is precisely what I’ve been searching for for very a time now. You have my gratitude man เล่นเกมยิงปลา
Aug 25, 2021 04:04:26 PM
No doubt this is an excellent post I got a lot of knowledge after reading good luck. Theme of blog is excellent there is almost everything to read, Brilliant post. agencja nieruchomosci rybnik
Aug 25, 2021 04:10:56 PM
hi!,I really like your writing so a lot! proportion we keep up a correspondence more approximately your article on AOL? I require an expert on this space to resolve my problem. May be that is you! Having a look forward to look you. รีวิวเทคนิคเกมคาสิโน
Aug 25, 2021 05:38:32 PM
This is a great post. I like this topic.This site has lots of advantage.I found many interesting things from this site. It helps me in many ways.Thanks for posting this again.
Aug 25, 2021 09:02:03 PM
You created some decent points there. I looked over the internet for your problem and found most individuals should go coupled with with your internet site. เล่นบาคาร่าเว็บไหนดี
Aug 25, 2021 09:08:09 PM
This is a great blog” and i want to visit this every day of the week . เดิมพันไฮโลออนไลน์
Aug 25, 2021 09:26:01 PM
very good post, i definitely love this website, keep on it เอาชนะบาคาร่า
Aug 26, 2021 12:18:12 PM
Very nice post, I surely love this site, keep it up. เทคนิคแทงไฮโล
Aug 26, 2021 12:28:22 PM
Sooner or later (which transit can last a long time) you are going to rid all by yourself of aged fears and restrictions, likewise as things that were programmed into you whenever you ended up pretty youthful! รีวิว-venus-casino
Aug 26, 2021 12:32:19 PM
My wife and i have been quite contented Edward managed to finish off his basic research through the entire precious recommendations he obtained when using the site. It’s not at all simplistic to just find yourself releasing helpful hints which often a number of people might have been making money from. And we also see we have got the blog owner to be grateful to for that. All the explanations you made, the straightforward blog navigation, the relationships you will help promote – it is mostly superb, and it is letting our son in addition to our family understand this subject is cool, which is unbelievably important. Thanks for the whole lot! รีวิวคาสิโนออนไลน์-sa-gaming
Aug 26, 2021 03:34:19 PM
I hate my boss. So during the spare times, I am quite down and dumbed from the repetitive tasks. Your posts give my brain some needed excercise. Thanks! Suburbicon
Aug 28, 2021 01:17:10 AM
Thank you for very usefull information.. <a href="https://www.launchora.com/story/play-your-favorite-casino-games-over-internet">Play your favorite casino games over the internet</a>
Aug 28, 2021 02:51:38 PM
You created some decent points there. I looked on the web for that problem and discovered most people may go as well as with your website. สล็อตออนไลน์
Aug 28, 2021 04:19:35 PM
great post <a href="https://tempmailo.com/">mail</a>
Aug 28, 2021 07:49:34 PM
I usually dont post in Blogs but your blog forced me to, amazing work. beautiful. แทงบอลออนไลน์
Aug 28, 2021 11:20:04 PM
This site is my intake , very fantastic design and style and perfect subject matter. seriestreaming.fun
Aug 29, 2021 02:10:40 PM
You can certainly see your enthusiasm within the work you write. The sector hopes for even more passionate writers like you who aren’t afraid to say how they believe. At all times follow your heart. buy youtube subscribers
Aug 29, 2021 03:01:19 PM
I am often to blogging and i genuinely appreciate your site content. This article has really peaks my interest. I am about to bookmark your internet site and maintain checking for brand spanking new data. บอลสเต็ป UFA365
Aug 29, 2021 07:19:16 PM
I think about it is most required for making more on this get engaged <a href="https://wownews.top/">wownews</a>
Aug 30, 2021 02:59:58 PM
Nice post mate, keep up the great work, just shared this with my friendz
Aug 30, 2021 03:30:17 PM
When I originally commented I clicked the -Notify me when new surveys are added- checkbox and after this whenever a comment is added I buy four emails with similar comment. Is there any way it is possible to eliminate me from that service? Thanks! ทางเข้าเว็บแทงบอลufabet
Aug 30, 2021 08:02:57 PM
All the contents you mentioned in post is too good and can be very useful. I will keep it in mind, thanks for sharing the information keep updating, looking forward for more posts.Thanks
Aug 31, 2021 05:13:35 PM
Fashion Courses Online… [...]here are some links to sites that we link to because we think they are worth visiting[...]… situs qq online
Aug 31, 2021 05:20:47 PM
Im no expert, but I believe you just made an excellent point. You certainly fully understand what youre speaking about, and I can truly get behind that.
Aug 31, 2021 05:43:34 PM
Wonderful post, thanks for discussing the data. It isn’t all too often that you simply read articles where the poster knows what they’re running a blog regarding. Grammar and punctuational are spot on too, only trouble We seemed to possess had been mentioning the website, seemed sluggish. Looks like additional visitors experienced exactly the same difficulty? <a href="https://seoservices32c.blogspot.com/2021/08/retiree-health-attention-advantages.html">TPP report</a>
Aug 31, 2021 05:44:18 PM
Wonderful post, thanks for discussing the data. It isn’t all too often that you simply read articles where the poster knows what they’re running a blog regarding. Grammar and punctuational are spot on too, only trouble We seemed to possess had been mentioning the website, seemed sluggish. Looks like additional visitors experienced exactly the same difficulty?
Aug 31, 2021 05:45:38 PM
Wonderful post, thanks for discussing the data. It isn’t all too often that you simply read articles where the poster knows what they’re running a blog regarding. Grammar and punctuational are spot on too, only trouble We seemed to possess had been mentioning the website, seemed sluggish. Looks like additional visitors experienced exactly the same difficulty?
Aug 31, 2021 05:47:36 PM
Wonderful post, thanks for discussing the data. It isn’t all too often that you simply read articles where the poster knows what they’re running a blog regarding. Grammar and punctuational are spot on too, only trouble We seemed to possess had been mentioning the website, seemed sluggish. Looks like additional visitors experienced exactly the same difficulty? <a href="https://seoservices32c.blogspot.com/2021/08/retiree-health-attention-advantages.html">TPP report</a>
Aug 31, 2021 06:43:43 PM
Simply a smiling visitor here to share the love (:, btw outstanding design . "Audacity, more audacity and always audacity." by Georges Jacques Danton. pkv games
Aug 31, 2021 07:24:25 PM
What a lovely blog. I’ll surely be back again. Please preserve writing! cenforce 150mg
Sep 01, 2021 12:49:07 PM
I conceive other website proprietors should take this web site as an example , very clean and wonderful user pleasant pattern . construction company in Pakistan
Sep 01, 2021 03:42:03 PM
Hello! I just now would choose to provide a large thumbs up for any excellent information you have here for this post. We are returning to your blog to get more detailed soon. limoges boxes
Sep 01, 2021 04:35:29 PM
I recently came across your blog and have been reading along. I thought I could leave my first comment. I don’t know what to say except that I have enjoyed scaning what you all have to say Daftar Situs Judi Slot Online Tepercaya
Sep 01, 2021 06:11:34 PM
i read a lot of stuff and i found that the way of writing to clearifing that exactly want to say was very good so i am impressed and ilike to come again in future..rent a car beograd
Sep 01, 2021 06:12:24 PM
I really loved reading your blog. It was very well authored and easy to undertand. Unlike additional blogs I have read which are really not tht good. I also found your posts very interesting. In fact after reading, I had to go show it to my friend and he ejoyed it as well! security guard services in singapore
Sep 01, 2021 10:11:34 PM
i read a lot of stuff and i found that the way of writing to clearifing that exactly want to say was very good so i am impressed and ilike to come again in future.. 먹튀검증
Sep 01, 2021 10:45:51 PM
Great write-up, I am a big believer in leaving comments on sites to help the blog writers know that they’ve added some thing advantageous to the world wide web! prader willi syndrome life expectancy
Sep 01, 2021 11:44:57 PM
You make so many great points here that I read your article a couple of times. Your views are in accordance with my own for the most part. This is great content for your readers.letou
Sep 02, 2021 12:00:35 AM
I definitely enjoying every little bit of it. It is a great website and nice share. I want to thank you. Good job! You guys do a great blog, and have some great contents. Keep up the good work.hosting-lelo
Sep 02, 2021 02:27:36 PM
i have seen a few mobile browsers and used some of them, they are still a bit slow; Film streaming
Sep 02, 2021 02:29:11 PM
It is a good site post without fail. Not too many people would actually, the way you just did. I am impressed that there is so much information about this subject that has been uncovered and you’ve defeated yourself this time, with so much quality. Good Works!
Sep 02, 2021 04:12:29 PM
I do not even know how I stopped up here, however I believed this post used to be great. I do not recognize who you are but certainly you’re going to a well-known blogger should you are not already Cheers! numero voyance
Sep 02, 2021 08:08:57 PM
Loving the information on this site, you have done great job on the content . MAG instructions
Sep 02, 2021 09:19:39 PM
Adding to my bookmarks thanks, needed some more pictures maybe. สล็อตออนไลน์
Sep 04, 2021 02:51:55 PM
I also didn’t care for the over-the-top “final mission” where this particular platoon, led by the initially realistic but ultimately too heroic Aaron Cleftjaw, manages to locate (spoiler) and destroy the inevitable mothership. mind lab pro review
Sep 04, 2021 03:37:07 PM
An fascinating discussion will probably be worth comment. I believe that you ought to write more on this topic, may possibly not be described as a taboo subject but usually everyone is too little to communicate on such topics. To another location. Cheers husky tools website
Sep 04, 2021 05:35:08 PM
Oh my goodness! an excellent post dude. Thanks a ton However We are experiencing problem with ur rss . Don’t know why Cannot sign up for it. Is there everyone acquiring identical rss problem? Anybody who knows kindly respond. Thnkx รีวิวufa168
Sep 04, 2021 06:36:53 PM
I haven’t checked in here for some time because I thought it was getting boring, but the last few posts are really good quality so I guess I’ll add you back to my daily bloglist. You deserve it my friend. insurance guidesagen liga parlay bola
Sep 04, 2021 07:22:08 PM
very nice post, i surely really like this excellent website, continue it เล่นรูเล็ต
Sep 04, 2021 07:25:15 PM
I can see that you are an expert at your field! I am launching a website soon, and your information will be very useful for me.. Thanks for all your help and wishing you all the success in your business. areaslot
Sep 04, 2021 08:03:47 PM
Unquestionably believe that which you stated. Your favorite justification appeared to be on the internet the simplest thing to be aware of. I say to you, I definitely get annoyed while people consider worries that they just don’t know about. You managed to hit the nail upon the top as well as defined out the whole thing without having side-effects , people can take a signal. Will likely be back to get more. Thanks วิธีเล่นรูเล็ตมือใหม่
Sep 05, 2021 01:25:19 PM
Aw, i thought this was a really nice post. In thought I would like to set up writing such as this additionally – taking time and actual effort to manufacture a great article… but exactly what can I say… I procrastinate alot and no indicates manage to go carried out. วางเดิมพันเกมสล็อต
Sep 05, 2021 01:49:08 PM
This is actually to boot the most fantastic post we tend to earnestly veteran researching throughout. It happens to be definitely not consistently we've found financial risk view a little. car headliner material suppliers
Sep 05, 2021 03:48:52 PM
Youre so cool! I dont suppose Ive read anything like this prior to. So nice to find somebody with some original ideas on this subject. realy appreciation for starting this up. this web site is one thing that is needed on-line, an individual if we do originality. valuable task for bringing interesting things for the net! bike umbrella canopy
Sep 06, 2021 01:18:10 PM
This type of looks entirely finest. These tiny details are usually made along with a lot of foundation details. I prefer in which a lot. Healing-bark.com
Sep 06, 2021 03:39:05 PM
Some times its a pain in the ass to read what blog owners wrote but this internet site is rattling user friendly ! . Divorce
Sep 06, 2021 03:45:23 PM
Quickly our own web site will, no doubt definitely turn into well regarded together with practically all running any website family members, due to its careful content and evaluate posts. como comprar seguidores LosFamos
Sep 06, 2021 08:37:14 PM
These you will then see the most important thing, the application provides you a website a powerful important internet page: plagius crackeado
Sep 07, 2021 01:48:06 PM
Hey very nice site!! Guy .. Excellent .. Wonderful .. I’ll bookmark your blog and take the feeds also?I’m glad to seek out a lot of useful information here in the put up, we’d like develop extra techniques on this regard, thank you for sharing. . . . . . ทีเด็ดบอลเต็ง
Sep 07, 2021 03:12:37 PM
I’m happy! It’s pleasant to see someone really educated about what they do. Hold up the excellent perform and I’ll return for additional! Many thanks! superslot wallet
Sep 07, 2021 05:25:30 PM
Normally I don’t read article on blogs, but I would like to say that this write-up very forced me to try and do it! Your writing style has been surprised me. Thanks, quite nice article. Cereal milk weed strain
Sep 08, 2021 05:37:05 PM
This blog website is pretty cool! How was it made ! pgslot
Sep 09, 2021 01:01:40 PM
Hello! I recently would want to provide a enormous thumbs up for that excellent information you’ve got here about this post. I’ll be coming back to your website to get more soon. Youtube reseller Panel
Sep 09, 2021 07:28:47 PM
I can’t believe focusing long enough to research; much less write this kind of article. You’ve outdone yourself with this material without a doubt. It is one of the greatest contents.
Sep 09, 2021 08:52:28 PM
Wow, fantastic blog layout! How long have you been blogging for? you made blogging look easy. The overall look of your site is fantastic, let alone the content! Josephine County Property Management
Sep 10, 2021 12:22:53 AM
Thank you so much for the post you do. I like your post and all you share with us is up to date and quite informative, i would like to bookmark the page so i can come here again to read you, as you have done a wonderful job. Is Conan Exiles Cross Platform Game
Sep 10, 2021 02:02:10 AM
Good post but I was wondering if you could write a litte more on this subject? I’d be very thankful if you could elaborate a little bit further. Appreciate it! <a href="https://www.fiverr.com/share/90Gm1D">200 blog comment unique domain</a>
Sep 10, 2021 10:16:50 PM
Superbly written article, if only all bloggers offered the same content as you, the internet would be a far better place.. New mp3
Sep 11, 2021 02:29:32 PM
Have you already setup a fan page on Facebook ?~-.:. เว็บแทงบอลสเต็ป 2-12 คู่
Sep 11, 2021 08:11:07 PM
Are you psychic? You have to be as your writing so perfectly fits the questions I possess in mind on this topic. I only entered a few terms in the search results and I’m very thankful that your article jumped up. remove image from google
Sep 11, 2021 10:06:03 PM
Hello I want to to share the remark here regarding you to be able to let you know just how much i actually Liked this particular read. I have to elope to aTurkey Day Supper however desired to depart you a simple remark. We saved a person So will end up being coming back subsequent function to see more of yer high quality articles. Continue the quality work. สล็อต
Sep 12, 2021 02:31:01 PM
This type of shows up absolutely excellent. Most of these smaller specifics are set up as well as lots of record being familiar with. I like this specific quite a lot. Nowgoal
Sep 12, 2021 06:14:05 PM
Thank you so much as you have been willing to share information with us. We will forever admire all you have done here because you have made my work as easy as ABC. The Uncanny Counter
Sep 12, 2021 07:50:51 PM
of course internet dating is the trend these days, you can meet lots of people on the internet. judi slot online
Sep 13, 2021 02:35:29 PM
There are certainly a number of details like that to take into consideration. That is a great level to deliver up. I provide the thoughts above as normal inspiration but clearly there are questions like the one you bring up where a very powerful factor can be working in sincere good faith. I don?t know if greatest practices have emerged around issues like that, however I’m positive that your job is clearly identified as a good game. Both boys and girls really feel the impact of just a second’s pleasure, for the remainder of their lives. situs pkv games
Sep 13, 2021 09:34:13 PM
This is certainly also quite a very good putting up many of us really seasoned hunting by way of. It can be not even close each day we've got threat to view a little something. 꽁머니
Sep 14, 2021 01:10:34 PM
Clients marketing strategies that you choose to useful survey before establishing. It can be straightforward to jot down top-quality write-up like this. <a href="www.google.com.co/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F">www.google.com.co/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F</a>
Sep 14, 2021 02:35:48 PM
The tips you provided here are extremely precious. It turned out this sort of pleasurable surprise to acquire that watching for me after i awakened today. There’re constantly to the point and to comprehend. Thanks a ton to the valuable ideas you’ve got shared here. What is Check Valves?
Sep 14, 2021 02:58:57 PM
sony music would be the biggest company in entertainment from what i see in the future. they have a good business plan- What is Solenoid Valve?
Sep 14, 2021 07:00:59 PM
The style absolutely superb. These types of tiny facts usually are fashioned using lots of story practical knowledge. I'd prefer everthing appreciably. www.google.com.co/url?sa=t&url=https%3A%2F%2Fwijidigital.com %2F
Sep 14, 2021 10:49:12 PM
This is additionally a fairly excellent post that individuals undoubtedly appreciated studying. Definitely not everyday which usually take pleasure in the odds to discover a merchandise. https://barowatt.com
Sep 15, 2021 01:06:30 PM
What a thrilling post. It is extremely chock-full of useful information. Thanks for such a great info.
Sep 15, 2021 08:55:37 PM
i always make sure that our kitchen appliances are very clean and shiny before using them. Animeflv
Sep 16, 2021 07:36:01 PM
cheers for posting this post. I am definitely tired of struggling to find relevant and intelligent commentary on this subject. Everyone nowadays seem to go to extremes to either drive home their viewpoint or suggest that everybody else in the globe is wrong. cheers for your concise and relevant insight. maps.google.com.sa/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 16, 2021 09:36:48 PM
Once i received onto your website even though getting consideration basically somewhat tad submits. Pleasurable strategy for upcoming, I am bookmarking at the same time acquire kinds end rises upwards. leidsa
Sep 16, 2021 09:49:06 PM
of course like your web site but you need to check the spelling on several of your posts. Many of them are rife with spelling problems and I to find it very bothersome to inform the truth on the other hand I will surely come again again. Buy Pumpkin Seeds
Sep 17, 2021 12:07:51 AM
Impressive web site, Distinguished feedback that I can tackle. Im moving forward and may apply to my current job as a pet sitter, which is very enjoyable, but I need to additional expand. Regards. -go88
Sep 17, 2021 09:39:49 PM
I was reading some of your content on this website and I conceive this internet site is really informative ! Keep on putting up.bong88
Sep 18, 2021 01:43:34 PM
Wow, cool post. I’d like to write like this too – taking time and real hard work to make a great article… but I put things off too much and never seem to get started. Thanks though. เว็บแทงบอลออนไลน์
Sep 18, 2021 01:45:18 PM
I was just itching to know do you trade featured posts Bandarqq
Sep 18, 2021 02:12:49 PM
I exactly got what you mean, thanks for posting. And, I am too much happy to find this website on the world of Google. รีวิวเว็บแทงบอล
Sep 18, 2021 06:20:26 PM
I consume around four cups a week, I will begin my week with close to one and then move on to many other groups. I like to think the more the better though. เว็บแทงบอลออนไลน์
Sep 18, 2021 06:58:42 PM
hello!,I like your writing very much! share we communicate more about your post on AOL? I require a specialist on this area to solve my problem. May be that’s you! Looking forward to see you. maps.google.co.ve/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 18, 2021 08:29:17 PM
Within the present day culture look at Language is now a whole lot even more necessary and in addition well-known. Yet once i has long been younger, My spouse and i failed to comprehend with this as well as determine to like exterior instead of realize Language. Nevertheless my private mommy stated: “English can be the essential tools for being capable to consult with foreign most people, and which means it’s essential to analyze within a Language school. UFABET
Sep 18, 2021 09:33:32 PM
Because of this , advertising campaigns strategies to be able to helpful check out sooner than publishing. Be more successful to jot down far better location such as this. 먹튀폴리스
Sep 18, 2021 09:53:47 PM
This is the proper weblog for everyone who wishes to find out about this topic. You already know a lot its virtually difficult to argue with you (not that I just would want…HaHa). You certainly put a fresh spin with a topic thats been discussing for many years. Excellent stuff, just fantastic! voyance numero
Sep 18, 2021 10:12:15 PM
Photos available on your site even though producing attention rapidly some quantity submits. Satisfying way of long-term long term, I'm going to be book-marking in the period turn out to be your own area complete occurs inch upward inch. mrkeo
Sep 19, 2021 03:12:20 AM
It is my first visit to your blog, and I am very impressed with the articles that you serve. Give adequate knowledge for me. Thank you for sharing useful material. I will be back for the more great post.
Sep 19, 2021 02:57:17 PM
At times it’s easier to simply take a step again and also understand that not everybody shares your own values ทางเข้ายูฟ่าเบท
Sep 19, 2021 08:02:52 PM
Hello there, just became alert to your blog through Google, and found that it’s truly informative. I’m gonna watch out for brussels. I’ll be grateful if you continue this in future. A lot of people will be benefited from your writing. Cheers! images.google.com.tr/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 19, 2021 09:22:39 PM
Thanks for the nice blog. It was very useful for me. I'm happy I found this blog. Thank you for sharing with us,I too always learn something new from your post. https://vaccin8id.com/
Sep 20, 2021 01:25:42 PM
Hey, this day is too much good for me, since this time I am reading this enormous informative article here at my home. Thanks a lot for massive hard work. images.google.com.qa/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 20, 2021 01:32:19 PM
Your blog is too much amazing. I have found with ease what I was looking. Moreover, the content quality is awesome. Thanks for the nudge! <a href="https://images.google.com.qa/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F">images.google.com.qa/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F</a>Sep 20, 2021 01:42:50 PM
I think this is an informative post and it is very beneficial and knowledgeable. Therefore, I would like to thank you for the endeavors that you have made in writing this article. All the content is absolutely well-researched. Thanks... images.google.com.pr/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 20, 2021 03:02:48 PM
This really is both equally a very good information when i rather definitely preferred verifying. This may not be at all times i always get likely to see a challenge. cse.google.com.pr/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 20, 2021 03:52:18 PM
Your blog is too much amazing. I have found with ease what I was looking. Moreover, the content quality is awesome. Thanks for the nudge! cse.google.co.cr/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 20, 2021 04:50:03 PM
Nice blog. Fine theme except of footer. I really like this post. It`s amazing what you wrote here. I hope you will write something so amazing soon. prowoodworkingguides.com
Sep 20, 2021 08:13:33 PM
Normally I do not read post on blogs, however I wish to say that this write-up pressured me to check out. Your writing style is amazing. Thanks, very nice article. https://www.wijidigital.com/
Sep 20, 2021 08:54:31 PM
You lost me, buddy. I mean, I imagine I get what youre indicating. I recognize what you’re saying, but you just appear to have ignored that you’ll find some other individuals inside the world who look at this matter for what it truly is and may perhaps not agree with you. You may well be turning away many of folks who might have been fans of your web log. images.google.com.ng/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 21, 2021 05:25:08 PM
It’s difficult to acquire knowledgeable men and women within this topic, however you seem like guess what happens you are preaching about! Thanks 토토사이트
Sep 21, 2021 07:30:04 PM
Took me time to read all the comments, but I really enjoyed the article. It proved to be Very helpful to me and I am sure to all the commenters here! It’s always nice when you can not only be informed, but also entertained! Baby Sleeping Music
Sep 21, 2021 08:48:24 PM
This article is an appealing wealth of informative data that is interesting and well-written. I commend your hard work on this and thank you for this information. You’ve got what it takes to get attention. รีวิว สล็อต
Sep 21, 2021 10:24:15 PM
This is the proper weblog for everyone who wishes to find out about this topic. You already know a lot its virtually difficult to argue with you (not that I just would want…HaHa). You certainly put a fresh spin with a topic thats been discussing for many years. Excellent stuff, just fantastic! blogger kampung
Sep 22, 2021 12:32:34 PM
This article was written by a real thinking writer without a doubt. I agree many of the with the solid points made by the writer. I’ll be back day in and day for further new updates. images.google.com.uy/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 22, 2021 01:32:46 PM
You actually make it seem so easy with your presentation but I find this matter to be really something which I think I would never understand. It seems too complex and very broad for me. I am looking forward for your next post, I will try to get the hang of it! cse.google.com.ng/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 22, 2021 02:33:08 PM
I am really enjoying the theme/design of your site. Do you ever run into any internet browser compatibility problems? A number of my blog audience have complained about my blog not working correctly in Explorer but looks great in Chrome. Do you have any ideas to help fix this issue? images.google.com.mx/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 22, 2021 02:40:42 PM
I really impressed after read this because of some quality work and informative thoughts . I just wanna say thanks for the writer and wish you all the best for coming!. แนะนำเกมยิงปลา UFABET
Sep 22, 2021 07:18:47 PM
you are really a good webmaster. The site loading speed is incredible. It seems that you are doing any unique trick. Furthermore, The contents are masterwork. you have done a excellent job on this topic! cse.google.com.gt/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 22, 2021 07:34:08 PM
I’m impressed, I have to admit. Truly rarely do I encounter a weblog that’s both educative and entertaining, and let me tell you, you could have hit the nail about the head. Your idea is outstanding; ab muscles an element that inadequate people are speaking intelligently about. We are delighted i came across this inside my look for something regarding this. maps.google.com.ng/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 22, 2021 08:00:53 PM
Thank you for some other informative blog. Where else could I get that type of information written in such an ideal means? I have a mission that I'm just now working on, and I have been at the look out for such information. https ://www.deviantart.com/drifitshirts/journal/The-Benefits-of-Buying-Dri-Fit-Shirts-891873435
Sep 22, 2021 08:42:19 PM
The article is really very interesting! I will continue to try me here to keep you informed. Thank you! plus.sandbox.google.com.ng/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 22, 2021 09:32:46 PM
Quickly your website can irrefutably acquire well known being among the most regarding submitting buyers, due to its thorough content articles or simply just essential critiques. what-is-the-best-material-for-custom-mailer-boxes
Sep 22, 2021 10:23:47 PM
Very useful post. This is my first time i visit here. I found so many interesting stuff in your blog especially its discussion. Really its great article. Keep it up. Molded rubber
Sep 23, 2021 12:20:48 PM
I adore all the strings, My partner and i savored, I'd personally love far more details using this, for the reason that it really is really pleasurable., Enjoy it designed for offering. dark web links
Sep 23, 2021 02:01:05 PM
I went over this website and I believe you have a lot of wonderful information, saved to my bookmarks https://medium.com/@secom291/the-usefulness-of-alarm-monitoring-service-providers-3ac1b6eda8
Sep 23, 2021 03:12:09 PM
I exactly got what you mean, thanks for posting. And, I am too much happy to find this website on the world of Google. www.google.co.ke/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 23, 2021 03:49:54 PM
Great content material and great layout. Your website deserves all of the positive feedback it’s been getting. sky-lego.sandbox.google.com.ng/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 23, 2021 03:58:20 PM
This is very educational content and written well for a change. It's nice to see that some people still understand how to write a quality post! maps.google.com.bh/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 23, 2021 04:49:37 PM
Hello there, just became alert to your blog through Google, and found that it’s truly informative. I am going to watch out for brussels. I will appreciate if you continue this in future. A lot of people will be benefited from your writing. Cheers! cse.google.com.np/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 23, 2021 06:23:56 PM
What a thrilling post, you have pointed out some excellent points, I as well believe this is a superb website. I have planned to visit it again and again. bamboo clothing manufacturers
Sep 23, 2021 06:31:26 PM
you possess a excellent weblog here! want to have invite posts on my weblog? bitcoin sports betting
Sep 23, 2021 07:46:20 PM
If conceivable, as you clear knowledge, would you mind updating your blog with more information? It is damned helpful in return me. maps.google.com.np/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 23, 2021 08:23:46 PM
Rapidly this kind of internet site can easily unquestionably recognition among virtually all blogging and site-building and also site-building individuals, to be able to the meticulous content or simply opinions. get more info about packaging material
Sep 23, 2021 09:49:03 PM
I admit, I have not been on this web page in a long time... however it was another joy to see It is such an important topic and ignored by so many, even professionals. I thank you to help making people more aware of possible issues. buy youtube views
Sep 24, 2021 07:06:10 AM
Vape Carts are on high demand now due to the great high derived from it as compared to exotic carts, thus leading to it’s rise in popularity in the vaping world. But due to it’s popularity, many people still find it difficult to get Dank Vapes. The question “where can I buy eureka carts” is becoming a high search keyword on Google.com and many other search engines. Glo Carts can mostly be gotten online from a Dank Vapes Official Website or Dank Vapes
https://thcvapesmart.com/
<a href="https://thcvapesmart.com/ " rel="dofollow">Glo Carts </a>
<a href="https://thcvapesmart.com/ " rel="dofollow">THC Carts</a>
<a href="https://thcvapesmart.com/ " rel="dofollow">eureka carts</a>
Sep 24, 2021 03:05:06 PM
I like this site so much, bookmarked . Discount Codes
Sep 25, 2021 12:54:15 PM
My brother recommended I may like this web site. He was entirely right. This publish actually made my day. You can not consider just how so much time I had spent for this information! Thank you! images.google.com.np/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 25, 2021 01:56:53 PM
I do not even know how I ended up here, but I believed this submit used to be great. I don’t recognize who you might be but certainly you’re going to a well-known blogger should you are not already Cheers! images.google.com.vn/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 25, 2021 02:32:51 PM
Rather than produce the same old content you have taken this subject to a whole new level . Kudos for not following the standard writing crowd. www.google.com.np/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 25, 2021 03:37:11 PM
I visit your blog regularly and recommend it to all of those who wanted to enhance their knowledge with ease. The style of writing is excellent and also the content is top-notch. Thanks for that shrewdness you provide the readers! Anwalt Hattingen
Sep 25, 2021 05:00:38 PM
This really is both equally a very good information when i rather definitely preferred verifying. This may not be at all times i always get likely to see a challenge. relaxante
Sep 25, 2021 06:38:38 PM
That is why it can be more effective that one could essential investigation in advance of making. You'll be able to write increased content using this method. classical piano music
Sep 25, 2021 08:53:02 PM
Nowhere on the Internet is there this much quality and clear information on this subject. How do I know? I know because I’ve searched this topic at length. Thank you. cse.google.com.mt/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 25, 2021 09:02:39 PM
I dont think Ive read anything like this before. So good to find somebody with some original thoughts on this subject. thank for starting this up. This website is something that is needed on the web, someone with a little originality. Good job for bringing something new to the internet! www.google.com.mt/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 26, 2021 03:16:43 AM
I definitely enjoying every little bit of it. It is a great website and nice share. I want to thank you. Good job! You guys do a great blog, and have some great contents. Keep up the good work.vimax
Sep 26, 2021 03:29:36 PM
It can be as well a considerable position i incredibly savored surfing around. Isn't really day by day that supply the candidate to watch a specific thing. images.google.com.py/url?sa=t&url=https%3A%2F%2Fwijidigital.com%2F
Sep 26, 2021 06:43:35 PM
Really instructive and great structure of content material , now that’s user friendly (:. hotmail connexion
Sep 26, 2021 07:38:11 PM
To consider obtained on your own website however establishing therapy simply just a tiny bit of submits. Pleasant technique for prospective upcoming, We have been book-marking at a stretch protected kinds quit goes up with each other. ข่าวกีฬา ข่าวกีฬาวันนี้ ข่าวกีฬาสดใหม่ ข่าวกีฬาล่าสุด เว็บข่าวกีฬาครบวงจร
Sep 26, 2021 08:12:36 PM
Wow! Thank you! I always wanted to write on my site something like that. Can I include a portion of your post to my website? coronavirus u.s. virgin islands
Sep 26, 2021 10:26:54 PM
Normanton Park by Kingsford Huray. Hotline 61009266. Get Discounts, Direct Developer Price, Brochure, Floor Plan, Price List & More. Former Normanton Park HUDC. Normanton Park Showflat
Sep 27, 2021 12:25:15 AM
I definitely enjoying every little bit of it. It is a great website and nice share. I want to thank you. Good job! You guys do a great blog, and have some great contents. Keep up the good work. Complete Scholarship List
Sep 27, 2021 12:49:52 PM
A great content material as well as great layout. Your website deserves all of the positive feedback it’s been getting. I will be back soon for further quality contents. เกมสล็อต
Sep 27, 2021 12:54:35 PM
I cannot wait to dig deep and kickoff utilizing resources that I received from you. Your exuberance is refreshing. เกมสล็อต
Sep 27, 2021 01:34:45 PM
Thanks for another informative web site. Where else could I get that kind of information written in such an ideal way? I’ve a project that I’m just now working on, and I have been on the look out for such information. howling wind
Sep 27, 2021 02:22:40 PM
I found this is an informative and interesting post so i think so it is very useful and knowledgeable. I would like to thank you for the efforts you have made in writing this article. เกมสล็อต
Sep 27, 2021 02:31:06 PM
I still can not quite think that I could often be one of those studying the important suggestions found on your website. My family and I are sincerely thankful on your generosity and for giving me potential to pursue our chosen profession path. Many thanks for the important information I acquired from your site. sleep rain music
Sep 27, 2021 03:28:10 PM
I’m interested in using some of your material for my website. Please let me know if that’s OK and I will link back to this page. music
Sep 27, 2021 04:12:13 PM
It's on top of that a superb upload that him and i definitely treasured analyzing. It's actually not each day we have opportunity to know a specific thing. สล็อตออนไลน์ฟรีเครดิต
Sep 27, 2021 08:11:32 PM
Thank you again for all the knowledge you distribute,Good post. I was very interested in the article, it's quite inspiring I should admit. I like visiting you site since I always come across interesting articles like this one.Great Job, I greatly appreciate that.Do Keep sharing! Regards, iOS 15
Sep 27, 2021 10:59:24 PM
Online Casino Roulette. Roulette is all alone of the amazing famous 'wheel' casino online games. It is zest superb to lose true a round and there are various types of online casino roulette... Online Casino Roulette. Online Slot Machines. Slots are the easiest casino ... <a href="https://www.google.com/">owner of google by Nadir</a>
Sep 28, 2021 05:32:46 AM
Its a great pleasure reading your post.Its full of information I am looking for and I love to post a comment that "The content of your post is awesome" Great work.
Sep 28, 2021 01:49:11 PM
I found that site very usefull and this survey is very cirious, I ' ve never seen a blog that demand a survey for this actions, very curious...
Sep 28, 2021 02:15:08 PM
Thanks for your post. I’ve been thinking about writing a very comparable post over the last couple of weeks, I’ll probably keep it short and sweet and link to this instead if thats cool. Thanks. http://162.213.251.4/
Sep 28, 2021 02:49:19 PM
Great article with excellent idea!Thank you for such a valuable article. I really appreciate for this great information..
Sep 28, 2021 03:19:29 PM
Because of this , advertising campaigns strategies to be able to helpful check out sooner than publishing. Be more successful to jot down far better location such as this. prince chenzhi
Sep 28, 2021 03:30:20 PM
After reading many of your blogposts I staleness say i launch this fact one to mostly be top notch. I soul a weblog also and require to repost a few shears of your articles on my own diary site. Should it be alright if I use this as eternal I own testimonial your web blog or create a inward unification to your article I procured the snipping from? If not I realise and could not do it without having your tolerance . I change accumulation scarred this article to sound and zynga calculate intended for remark. Anyway realize it either way! graphic design Brisbane
Sep 28, 2021 03:37:03 PM
I really appreciate this post. I have been looking all over for this! Thank goodness I found it on Bing. You have made my day! Thanks again reamcity
Sep 28, 2021 05:36:39 PM
Thanks for sharing this information. I really like your blog post very much. You have really shared a informative and interesting blog post with people.. Summoners War: Chronicles
Sep 28, 2021 06:38:07 PM
I have read all the comments and suggestions posted by the visitors for this article are very fine,We will wait for your next article so only.Thanks! PS4 Pro
Sep 28, 2021 08:19:25 PM
Great blog, I am going to spend more time reading about this subject SEO Galway
Sep 28, 2021 09:41:45 PM
But the unimaginative writers couldn’t be bothered to work out a plot consistent with the all the rest of the Star Trek collection. nursing test banks free
Sep 28, 2021 10:41:46 PM
I would like most of the accounts, Favor actually enjoyed, We wish addiitional details regarding it, because it will be comparatively outstanding., Respect only for proclaiming. movil android
Sep 29, 2021 04:33:08 AM
New web site is looking good. Thanks for the great effort.
Sep 29, 2021 07:18:34 AM
What an amazing article this was. Would recommend you!
Sep 29, 2021 12:40:15 PM
I am very enjoyed for this blog. Its an informative topic. It help me very much to solve some problems. Its opportunity are so fantastic and working style so speedy. https://toolbarqueries.google.de/url?q=http%3A%2F%2Fwww.oncarbrands.com https://toolbarqueries.google.de/url?q=http%3A%2F%2Fwww.oncarbrands.com https://maps.google.de/url?source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=WOilJLXihyL17N25ZYukrrpAWbAueb&usg=DZVwbSnPNfdVziomVo1gcgsPOEyQxH https://maps.google.de/url?source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=WOilJLXihyL17N25ZYukrrpAWbAueb&usg=DZVwbSnPNfdVziomVo1gcgsPOEyQxH%2F%3Fhl%3Den https://images.google.de/url?sa=t&url=http%3A%2F%2Fwww.oncarbrands.com http://images.google.de/url?sa=t&url=http%3A%2F%2Fwww.oncarbrands.com%3Fhl%3Den https://www.google.com/url?sa=t&url=http%3A%2F%2Fwww.oncarbrands.com%3Fhl%3Den https://plus.google.com/url?q=http%3A%2F%2Fwww.oncarbrands.com https://plus.google.com/url?q=http%3A%2F%oncarbrands.com%2F https://plus.google.com/url?q=http%3A%2F%2Foncarbrands%2F https://www.google.com/url?sa=t&url=http%3A%2F%2Foncarbrands.com http://maps.google.com/url?q=http%3A%2F%2Fwww.oncarbrands.com http://maps.google.com/url?sa=t&url=http%3A%2F%2Fwww.oncarbrands.com%3Fhl%3Den https://www.google.com/url?q=http%3A%2F%2Fwww.oncarbrands.com https://www.google.com/url?q=http%3A%2F%2Fwww.oncarbrands.com%2F https://www.google.com/url?sa=t&url=http%3A%2F%2Fwww.oncarbrands.com https://clients1.google.de/url?source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=kCdg3UgLLjRjlphE1gmKplC67xGgQG&usg=tFsf3JSsnCfkMRy23cIjMsEVr78fhG https://clients1.google.de/url?source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=kCdg3UgLLjRjlphE1gmKplC67xGgQG&usg=tFsf3JSsnCfkMRy23cIjMsEVr78fhG%2F%3Fhl%3Den https://www.google.de/url?sa=t&url=http%3A%2F%2Fwww.oncarbrands.com https://www.google.de/url?sa=t&url=http%3A%2F%2Fwww.oncarbrands.com%3Fhl%3Den I am very enjoyed for this blog. Its an informative topic. It help me very much to solve some problems. Its opportunity are so fantastic and working style so speedy.
Sep 29, 2021 01:17:15 PM
I found so many interesting stuff in your blog especially its discussion. From the tons of comments on your articles, I guess I am not the only one having all the enjoyment here! keep up the good work... http://toolbarqueries.google.co.jp/url?source=web&rct=j&url=http%3A%2F%2Fwww.oncarbrands.com&ved=ianNRV0XdtgMvbi0Pd3LPea8h8ipLC&usg=ELFUBFdkjiM0WoTlZaJw5ZZiUdanFS http://toolbarqueries.google.co.jp/url?sa=t&source=web&rct=j&url=https%3A%2F%2Foncarbrands.com&ved=Jj6igadClHginRBs4CmHRKlJwFFoFn&usg=loTLCFFdy6POFUIgkygvG3vaW77wUJ http://toolbarqueries.google.co.jp/url?q=http%3A%2F%2Foncarbrands.com/ http://toolbarqueries.google.co.jp/url?sa=t&source=web&rct=j&url=https%3A%2F%2Foncarbrands.com/&ved=GdS2Ac7Y8RIRRI31pLSVMtH2wBRNdB&usg=Knb07Ovm4ODdq8yrvrVS1KgyZnFYF8 http://toolbarqueries.google.co.jp/url?rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=Ix7sUsbrWe81Sudi1mdyvixRBVs5Wb&usg=kHZdvWnQJDJkgsf4BRzvMa515zaq07 http://toolbarqueries.google.co.jp/url?sa=t&source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=Jj6igadClHginRBs4CmHRKlJwFFoFn&usg=loTLCFFdy6POFUIgkygvG3vaW77wUJ http://toolbarqueries.google.co.jp/url?source=web&rct=j&url=https%3A%2F%2Foncarbrands.com&ved=UQXYVlS0roSH8NQGDyBPTrbIBxP7Q6&usg=lEI4DUO5YEyKMIG0usHQCDCoRDPpwx http://toolbarqueries.google.co.jp/url?rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=OfjCcjm0DC4O7MnLrRApstJhx3agLg&usg=j2YSzIIJvHnYezAC2QfAkGfCQuFbeh http://toolbarqueries.google.co.jp/url?sa=t&source=web&rct=j&url=http%3A%2F%2Fwww.oncarbrands.com&ved=dqGTGZ4BgDLUeSNoREbNEW22LcxKNa&usg=cEAPWNinxcmr5524tLdvxhyfvqxMhD http://toolbarqueries.google.co.jp/url?sa=t&source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=GdS2Ac7Y8RIRRI31pLSVMtH2wBRNdB&usg=Knb07Ovm4ODdq8yrvrVS1KgyZnFYF8 http://toolbarqueries.google.co.jp/url?q=http%3A%2F%2Fwww.oncarbrands.com http://toolbarqueries.google.co.jp/url?rct=j&url=http%3A%2F%2Fwww.oncarbrands.com&ved=25SCosWDXojepQD2ptMXICKc7WthaM&usg=Ht2r5obsrajlu1TCkJ3DNmeESzuPDB http://toolbarqueries.google.co.jp/url?source=web&rct=j&url=https%3A%2F%2Foncarbrands.com/&ved=ip0PJqr3qMf8cNfrthU3muySJsMjTv&usg=tCebubirJ1JcetZHcz6BODpy8W0ifq http://toolbarqueries.google.co.jp/url?rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=LbItywGHzdm03MkD2RzXBfGnJdUBna&usg=wm0YCr1I7xrzazk6th5yWU8oaFEvSv http://toolbarqueries.google.co.jp/url?source=web&rct=j&url=http%3A%2F%2Foncarbrands.com/&ved=ianNRV0XdtgMvbi0Pd3LPea8h8ipLC&usg=ELFUBFdkjiM0WoTlZaJw5ZZiUdanFS http://www.google.co.jp/url?rct=j&url=http%3A%2F%2Foncarbrands.com/&ved=8PCkQYk6Tp05bMOxiRrEMSmG7upyIG&usg=2uXZaDRjl3rmYOLQlBYuqLx7YpC5lw http://www.google.co.jp/url?q=http%3A%2F%2Fwww.oncarbrands.com http://www.google.co.jp/url?sa=t&source=web&rct=j&url=http%3A%2F%2Fwww.oncarbrands.com&ved=CtWgBhty58gEg8AnZ5aQSVGsM4fvtF&usg=qEf3J1DZEUK4Oeo1azNiAAMAUQWEDF http://www.google.co.jp/url?source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=Nhj3tL4atdjbH1ujqe1bqnmsPYnOcG&usg=jalsoB1kanMbf2sN5weYGWqeaz40n http://www.google.co.jp/url?rct=j&url=https%3A%2F%2Foncarbrands.com/&ved=afDV2BcO7p4lLJXkcfMGuKFAxkK6h5&usg=W5ZKCEPuyN1VSjAByweVw4MtNzIdxS This is my first time i visit here and I found so many interesting stuff in your blog especially it's discussion, thank you.
Sep 29, 2021 02:00:52 PM
Impressive web site, Distinguished feedback that I can tackle. Im moving forward and may apply to my current job as a pet sitter, which is very enjoyable, but I need to additional expand. Regards. 토토사이트
Sep 29, 2021 06:32:40 PM
I found your this post while searching for information about blog-related research ... It's a good post .. keep posting and updating information. http://www.astro.wisc.edu/?URL=www.oncarbrands.com http://www.astro.wisc.edu/?URL=www.oncarbrands.com http://maten.sakura.ne.jp/index.php/view/3836493 http://maten.sakura.ne.jp/index.php/view/4329094 https://t.me/iv?url=http%3A%2F%2Fwww.oncarbrands.com https://t.me/iv?url=http%3A%2F%2Fwww.oncarbrands.com%3Fhl%3Den https://www.bing.com/news/apiclick.aspx?ref=FexRss&aid=&tid=9BB77FDA801248A5AD23FDBDD5922800&url=http%3A%2F%2Fwww.oncarbrands.com%3Fhl%3Den http://oncarbrands.idea.informer.com/ https://clients1.google.co.uk/url?source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=o83fYlZguGVI1SEfITIfCDHG2bbFW5&usg=KMkQogpH2mcXRbwezUqmzoFcdTAwlW https://maps.google.co.uk/url?source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=kusy4jxlEyZa0wdOVFjYKpoKFvgiME&usg=O1wfcQFtgnPoq1wyxj8y64nvl3fQ1J%2F%3Fhl%3Den https://clients1.google.co.uk/url?source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=o83fYlZguGVI1SEfITIfCDHG2bbFW5&usg=KMkQogpH2mcXRbwezUqmzoFcdTAwlW%2F%3Fhl%3Den https://maps.google.co.uk/url?source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=kusy4jxlEyZa0wdOVFjYKpoKFvgiME&usg=O1wfcQFtgnPoq1wyxj8y64nvl3fQ1J https://www.google.co.uk/url?source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=doHaS6NVuvjCz5jw8woh65jnGTOb2h&usg=LXAFkAPpiyULYNpEEqlY4SCUMgftD8%2F%3Fhl%3Den https://www.google.co.uk/url?source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=doHaS6NVuvjCz5jw8woh65jnGTOb2h&usg=LXAFkAPpiyULYNpEEqlY4SCUMgftD8 https://toolbarqueries.google.co.uk/url?source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=aubRwt5fToLDKdHN2v4bxRqLeUauyl&usg=t4Md3iIVgYpy2kOD8s3fbB27CreyML%2F%3Fhl%3Den https://toolbarqueries.google.co.uk/url?source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=aubRwt5fToLDKdHN2v4bxRqLeUauyl&usg=t4Md3iIVgYpy2kOD8s3fbB27CreyML https://maps.google.co.jp/url?source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=tLQH3Q0HjzfgofU7Yg6JUQAsk0bOJL&usg=ekiEEMRup6MBjEa3nWmDC6BcZLkyxc https://maps.google.com/url?sa=t&url=http%3A%2F%2Fwww.oncarbrands.com https://maps.google.com/url?q=http%3A%2F%2Foncarbrands%2F https://tinyurl.com/yazdbsas I found your this post while searching for information about blog-related research ... It's a good post .. keep posting and updating information.
Sep 29, 2021 06:36:21 PM
This is actually to boot the most fantastic post we tend to earnestly veteran researching throughout. It happens to be definitely not consistently we've found financial risk view a little. www.google.co.jp/url?rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=afDV2BcO7p4lLJXkcfMGuKFAxkK6h5&usg=W5ZKCEPuyN1VSjAByweVw4MtNzIdxS www.google.co.jp/url?rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=KfuyPa8ek2LtTcGbfgdMTNFXnLnMY5&usg=VFZLWmfKTk6o5dWCa5R7zyrgL6JFle www.google.co.jp/url?sa=t&source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=uuUGhvPZKpFdQerIdHEfgz0uJagMaU&usg=iFP4ujrS1cKEQGmY3cgqj6uA13CA6h www.google.co.jp/url?sa=t&source=web&rct=j&url=http%3A%2F%2Foncarbrands.com/&ved=CtWgBhty58gEg8AnZ5aQSVGsM4fvtF&usg=qEf3J1DZEUK4Oeo1azNiAAMAUQWEDF www.google.co.jp/url?rct=j&url=https%3A%2F%2Foncarbrands.com&ved=igoxtbYomNdQv2bCpkP4btak4LWvce&usg=dGEoygKPgzMNDAxClmBnfuujgYfdBR www.google.co.jp/url?sa=t&url=http%3A%2F%2Foncarbrands.com www.google.co.jp/url?rct=j&url=http%3A%2F%2Fwww.oncarbrands.com&ved=8PCkQYk6Tp05bMOxiRrEMSmG7upyIG&usg=2uXZaDRjl3rmYOLQlBYuqLx7YpC5lw www.google.co.jp/url?source=web&rct=j&url=https%3A%2F%2Foncarbrands.com/&ved=Nhj3tL4atdjbH1ujqe1bqnmsPYnOcG&usg=jalsoB1kanMbf2sN5weYGWqeaz40nD www.google.co.jp/url?q=http%3A%2F%2Foncarbrands.com www.google.co.jp/url?q=http%3A%2F%2Fwww.oncarbrands.com www.google.co.jp/url?q=http%3A%2F%2Foncarbrands.com/ www.google.co.jp/url?sa=t&source=web&rct=j&url=https%3A%2F%2Foncarbrands.com/&ved=uuUGhvPZKpFdQerIdHEfgz0uJagMaU&usg=iFP4ujrS1cKEQGmY3cgqj6uA13CA6h www.google.co.jp/url?rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=igoxtbYomNdQv2bCpkP4btak4LWvce&usg=dGEoygKPgzMNDAxClmBnfuujgYfdBR www.google.co.jp/url?source=web&rct=j&url=http%3A%2F%2Foncarbrands.com/&ved=NKmKXDgKJMWE2V8YrUp5ihPoFOVx8x&usg=FYNADbNlzqeoA6IB5di4Vo7JJF46ej www.google.co.jp/url?sa=t&source=web&rct=j&url=https%3A%2F%2Foncarbrands.com&ved=DY57w1xLo4W0ep0cfzbpvhhjQq1TYE&usg=GirXCZSGxPSIkkIOZgiT2IvFowQVrg www.google.co.jp/url?sa=t&source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=DY57w1xLo4W0ep0cfzbpvhhjQq1TYE&usg=GirXCZSGxPSIkkIOZgiT2IvFowQVrg www.google.co.jp/url?rct=j&url=https%3A%2F%2Foncarbrands.com&ved=KfuyPa8ek2LtTcGbfgdMTNFXnLnMY5&usg=VFZLWmfKTk6o5dWCa5R7zyrgL6JFle www.google.co.jp/url?source=web&rct=j&url=http%3A%2F%2Fwww.oncarbrands.com&ved=NKmKXDgKJMWE2V8YrUp5ihPoFOVx8x&usg=FYNADbNlzqeoA6IB5di4Vo7JJF46ej www.google.co.jp/url?sa=t&url=http%3A%2F%2Fwww.oncarbrands.com www.google.co.jp/url?source=web&rct=j&url=https%3A%2F%2Foncarbrands.com&ved=EUjudn7dj40GJ6qjNBbKdxz8ERbuna&usg=fyJAaNArFt1qjMY43F6IYnoVthukZu Because of this it will be significantly better which you could suitable studies just before manufacturing. You'll be able to create significantly greater guide that way.
Sep 29, 2021 09:21:58 PM
Thanks for taking the time to discuss this, I feel strongly that love and read more on this topic. If possible, such as gain knowledge, would you mind updating your blog with additional information? It is very useful for me. Fun88
Sep 29, 2021 09:22:08 PM
I think other web site proprietors should take this web site as an model, very clean and wonderful user friendly style and design, as well as the content. You’re an expert in this topic! how to verify a facebook business page
Sep 29, 2021 10:06:07 PM
It proved to be Very helpful to me and I am sure to all the commentators here!
Sep 30, 2021 03:57:47 AM
I’ve been surfing online more than three hours today, yet I never found any interesting article like yours. It’s pretty worth enough for me. In my opinion, if all webmasters and bloggers made good content as you did, the web will be a lot more useful than ever before.situs idn poker
Sep 30, 2021 04:44:43 AM
I definitely enjoying every little bit of it. It is a great website and nice share. I want to thank you. Good job! You guys do a great blog, and have some great contents. Keep up the good work.idn poker
Sep 30, 2021 05:52:35 AM
What an amazing article this was. Would recommend you!
Sep 30, 2021 12:22:58 PM
Wonderful blog! I found it while surfing around on Yahoo News. Do you have any suggestions on how to get listed in Yahoo News? I’ve been trying for a while but I never seem to get there! Appreciate it. safe deposit box website in singapore
Sep 30, 2021 01:23:58 PM
very interesting post.this is my first time visit here.i found so mmany interesting stuff in your blog especially its discussion..thanks for the post! NSW fake ID
Sep 30, 2021 01:30:57 PM
Very informative and useful post. You have nice command on the post and have explained in a very great way. Thanks for helping .Good work,hope your blog be better!I just want to make a blog like this! http://clients1.google.com.br/url?source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=qpwsYYDi2o1g1k51R43qHBxopDkNf7&usg=XzDwZCpW5ZmpSYd7pe4lynYcOX0idu http://clients1.google.com.br/url?source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=qpwsYYDi2o1g1k51R43qHBxopDkNf7&usg=XzDwZCpW5ZmpSYd7pe4lynYcOX0idu%2F%3Fhl%3Den http://toolbarqueries.google.com.br/url?q=http%3A%2F%2Fwww.oncarbrands.com https://www.google.com.br/url?source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=OYc4ACLEuCM48edrSHkqnfR3IJKARb&usg=KhSKkxmXyJvUSCIDnU8wft6VgIhivZ http://toolbarqueries.google.com.br/url?q=http%3A%2F%2Fwww.oncarbrands.com%3Fhl%3Den https://www.google.com.br/url?source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=OYc4ACLEuCM48edrSHkqnfR3IJKARb&usg=KhSKkxmXyJvUSCIDnU8wft6VgIhivZ%2F%3Fhl%3Den http://maps.google.com.br/url?sa=t&url=http%3A%2F%2Fwww.oncarbrands.com%3Fhl%3Den http://maps.google.com.br/url?sa=t&url=http%3A%2F%2Fwww.oncarbrands.com http://maps.google.co.jp/url?sa=t&source=web&rct=j&url=http%3A%2F%2Foncarbrands.com%2F&ved=ZePuRiSAvF7hT1pEVUdihQmu4Y3Fjb&usg=EISbqGCsviP42Uqf8stW783xOj1uz2 http://maps.google.co.jp/url?sa=t&source=web&rct=j&url=https%3A%2F%2Foncarbrands.com%2F&ved=xbLX68aILyXMsjUJhelMuO8cbxJH3J&usg=qJjpS3ascPelQtuDycll1P00DScIWJ http://maps.google.co.jp/url?rct=j&url=https%3A%2F%2Foncarbrands.com&ved=oZkk3klNdBHwWgbdEbL2r7RuDOnyqK&usg=iPMxZi1fd4ExNmcjM0cwUKrCHqhYQo http://maps.google.co.jp/url?rct=j&url=http%3A%2F%2Foncarbrands.com%2F&ved=jviIhsKzKjx6wqU5cJ5Mt8L1zo5wUd&usg=hSTLkDvq3PRcgyfOyxy3Jf84DjSqj2 http://maps.google.co.jp/url?sa=t&url=http%3A%2F%2Fwww.oncarbrands.com http://maps.google.co.jp/url?rct=j&url=http%3A%2F%2Fwww.oncarbrands.com&ved=jviIhsKzKjx6wqU5cJ5Mt8L1zo5wUd&usg=hSTLkDvq3PRcgyfOyxy3Jf84DjSqj2 http://maps.google.co.jp/url?sa=t&source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=xbLX68aILyXMsjUJhelMuO8cbxJH3J&usg=qJjpS3ascPelQtuDycll1P00DScIWJ http://maps.google.co.jp/url?rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=oZkk3klNdBHwWgbdEbL2r7RuDOnyqK&usg=iPMxZi1fd4ExNmcjM0cwUKrCHqhYQo http://maps.google.co.jp/url?source=web&rct=j&url=http%3A%2F%2Foncarbrands.com%2F&ved=x823DoBTz1N5LusmwkQmAXZIRRCf0o&usg=cKxtbYo85AtPIboVpAELCIPOLJitlV http://maps.google.co.jp/url?sa=t&url=http%3A%2F%2Foncarbrands.com http://maps.google.co.jp/url?rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=G0KMeq5k3LD7f4OMViWc26dfkEgehL&usg=BLK6LOVd7mfNztXGHRDwdij8PJWFCI http://maps.google.co.jp/url?sa=t&source=web&rct=j&url=http%3A%2F%2Fwww.oncarbrands.com&ved=ZePuRiSAvF7hT1pEVUdihQmu4Y3Fjb&usg=EISbqGCsviP42Uqf8stW783xOj1uz2
Sep 30, 2021 01:35:01 PM
Instantaneously the web page may irrefutably find popular very involving putting up shoppers, for the careful content pages or perhaps important testimonials. cummins 855 marine engine for sale
Sep 30, 2021 03:29:35 PM
This is certainly as well a really good posting we seriously experienced looking through. It is far from on a daily basis we have risk to check out a little something. ดูหนัง Aquaman : อควาแมน เจ้าสมุทร (2018)
Sep 30, 2021 06:07:21 PM
The post is written in very a good manner and it contains many useful information for me.
Oct 01, 2021 12:54:57 AM
I like this post,And I guess that they having fun to read this post,they shall take a good site to make a information,thanks for sharing it to me.
Oct 01, 2021 02:42:21 AM
There are some fascinating points over time in this article but I do not know if them all center to heart. There may be some validity but I am going to take hold opinion until I take a look at it further. Excellent post , thanks therefore we want a lot more! Put into FeedBurner in addition Real registered German Passports for sale
Oct 01, 2021 03:37:24 AM
Great site. Lots of useful info here. I’m sending it to several friends ans also sharing in delicious. And obviously, thanks for your sweat! <a href="https://www.2ndpassportonline.com/passports/buy-irish-passport-online-real-ireland-passport/">Real registered Irish Passports for sale</a>
Oct 01, 2021 04:07:37 AM
An extremely good post. This post sums up for me just what this topic is all about and some of the major benefits that can be produced by knowing about it just like you. A friend once pointed out that you have a totally different approach when you do something for certain as opposed to when you’re simply just toying with it. In the case of this specific topic, I believe you’re taking, or start to go for, a more professional plus thorough approach to what and how you’re writing, which in turn helps you to continue to get better and help others who don’t know anything at all about what you have discussed here. Thank you. Real registered Italy Passports for sale
Oct 01, 2021 04:43:51 AM
This is really good idea that eliminate delay on toll roads by collecting the electronic tolls. According to the public are suffered with this toll problem and seeking help from the government to get rid of this problem.
Oct 01, 2021 04:49:16 AM
Thank you very much for the sharing! COOL..
Oct 01, 2021 04:51:03 PM
That's the reason it is best that you ought to appropriate investigation prior to composing. It is possible to create much better publish by doing this. Real registered Japanese Passports for sale
Oct 01, 2021 05:33:04 PM
It again has the opinion absolutely applicable. Most of less significant characteristics are established throughout a large number of log coaching. I really like the coating an abundance. Purchase registered Luxembourg Passport
Oct 01, 2021 05:52:15 PM
I prefer the particular distribute. It is actually outstanding to learn someone verbalize from the cardiovascular system and in addition top quality using this important material could be simply experienced. Real registered Mexican Passports for sale
Oct 01, 2021 06:09:45 PM
Speedily this great site will certainly indisputably always be renowned amid most writing a blog men and women, for the fastidious content as well as testimonials. Buy Real Portuguese passport online
Oct 01, 2021 06:23:58 PM
Oh my goodness! an incredible article dude. Thank you Nevertheless I am experiencing difficulty with ur rss . Don’t know why Unable to subscribe to it. Is there anyone getting equivalent rss drawback? Anybody who knows kindly respond. Thnkx Real registered Singapore Passports for sale
Oct 01, 2021 06:43:06 PM
Howdy! This is my first comment here so I just wanted to give a quick shout out and tell you I genuinely enjoy reading your blog posts. Can you suggest any other blogs/websites/forums that go over the same subjects? Thanks! Real registered Spanish Passports for sale
Oct 01, 2021 10:16:08 PM
Wonderful blog. I think we need to talk as i want to hire you. Registered Turkey Passport online
Oct 01, 2021 10:36:08 PM
I’ve also been meditating on the very same matter myself recently. Happy to see another person on the same wavelength! Nice article. Registered British Passport online
Oct 02, 2021 03:35:00 PM
This is really too a very great publishing all of us critically skilled searching via. It's not even close to every day we now have danger to look at something. ผลบอลล่าสุด
Oct 03, 2021 01:23:28 AM
Them believes altogether best suited. Every one of lesser areas ended up being built by lots of track record instruction. I like the necessary paperwork a good deal. Real registered Australia Passports for sale
Oct 03, 2021 01:37:34 AM
This is the reason it really is greater you could important examination before creating. It will be possible to create better write-up like this. Real registered Canadian Passports for sale
Oct 03, 2021 01:52:02 AM
I love your own publish. It's great to determine a person explain in words in the center as well as clearness about this essential topic could be very easily noticed. Real registered Chinese Passports for sale
Oct 03, 2021 02:23:23 AM
The extremely quite possibly a decent deal that in actual fact extremely savored perusing. Isn't really usual that have the option to check a given idea. wikipedia kickass torrents
Oct 03, 2021 03:24:58 AM
Its a great pleasure reading your post.Its full of information I am looking for and I love to post a comment that "The content of your post is awesome" Great work.
Oct 03, 2021 06:30:27 AM
Had been looking for such content now I got, Thankfully!
Oct 03, 2021 01:59:11 PM
I have been absent for some time, but now I remember why I used to love this blog. Thanks , I will try and check back more often. How frequently you update your web site? ผลบอลล่าสุด
Oct 03, 2021 03:47:24 PM
I hate my boss. So during the spare times, I am quite down and dumbed from the repetitive tasks. Your posts give my brain some needed excercise. Thanks! ตารางผลบอลสด
Oct 04, 2021 03:01:52 AM
Keep up the good work , I read few posts on this web site and I conceive that your blog is very interesting and has sets of fantastic information. Registered Spain Passport online
Oct 04, 2021 10:49:23 PM
I am continually amazed by the amount of information available on this subject. What you presented was well researched and well worded in order to get your stand on this across to all your readers. تأجير السيارات مسقط
Oct 05, 2021 01:14:34 PM
nice post, keep up with this interesting work. It really is good to know that this topic is being covered also on this web site so cheers for taking time to discuss this! chen zhi prince group
Oct 05, 2021 01:16:13 PM
I am very enjoyed for this blog. Its an informative topic. It help me very much to solve some problems. Its opportunity are so fantastic and working style so speedy. http://toolbarqueries.google.es/url?rct=j&url=https%3A%2F%2Foncarbrands.com&ved=CdLn836jjkvLGKYTjrYSkBr14MUG7o&usg=hbf7ik7RzJa3gHON6xXpgx4vtaUSsw http://toolbarqueries.google.es/url?sa=t&source=web&rct=j&url=https%3A%2F%2Foncarbrands.com&ved=MGyoBRegco2bPp2xAiBcHOyknsA2Wn&usg=XDhd4Ro8Ep2ZwWCdWqnwlUFdq7ioai http://toolbarqueries.google.es/url?rct=j&url=http%3A%2F%2Fwww.oncarbrands.com&ved=TGkrAbhawB78eVtnepbHUIccHcQXdY&usg=nCEueeHsADCteL5x0faB7S0BzkDiSx http://toolbarqueries.google.es/url?source=web&rct=j&url=https%3A%2F%2Foncarbrands.com/&ved=XDUKob0spXmfVLM54hXhDWb3tr5Y4i&usg=PeMRZM5oFWRapxptxvSgGxDaKaB0q5 http://toolbarqueries.google.es/url?q=http%3A%2F%2Foncarbrands.com http://toolbarqueries.google.es/url?rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=CdLn836jjkvLGKYTjrYSkBr14MUG7o&usg=hbf7ik7RzJa3gHON6xXpgx4vtaUSsw http://toolbarqueries.google.es/url?sa=t&source=web&rct=j&url=https%3A%2F%2Foncarbrands.com/&ved=IjRodTRc7pUTTJqJ1I8aFt1VG25XFQ&usg=iPbEUlE6aEjF2fWpwzIba32A7pq5Qk http://toolbarqueries.google.es/url?q=http%3A%2F%2Fwww.oncarbrands.com http://toolbarqueries.google.es/url?sa=t&source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=IjRodTRc7pUTTJqJ1I8aFt1VG25XFQ&usg=iPbEUlE6aEjF2fWpwzIba32A7pq5Qk http://toolbarqueries.google.es/url?rct=j&url=http%3A%2F%2Foncarbrands.com/&ved=TGkrAbhawB78eVtnepbHUIccHcQXdY&usg=nCEueeHsADCteL5x0faB7S0BzkDiSx http://toolbarqueries.google.es/url?source=web&rct=j&url=http%3A%2F%2Fwww.oncarbrands.com&ved=8QAZAFxGNcVvQvOxPwW7PHhiX64OgM&usg=tsc6LMW6bIm37maAGqpeikSr2AJrbC http://toolbarqueries.google.es/url?source=web&rct=j&url=http%3A%2F%2Foncarbrands.com/&ved=8QAZAFxGNcVvQvOxPwW7PHhiX64OgM&usg=tsc6LMW6bIm37maAGqpeikSr2AJrbC http://toolbarqueries.google.es/url?sa=t&source=web&rct=j&url=http%3A%2F%2Foncarbrands.com/&ved=L8FH45GvXtHM2vHQqHSNMMXZqa0h8I&usg=URebUKHUpPXAClAXZDjQD8Eyc8kOq4 http://toolbarqueries.google.es/url?sa=t&source=web&rct=j&url=http%3A%2F%2Fwww.oncarbrands.com&ved=L8FH45GvXtHM2vHQqHSNMMXZqa0h8I&usg=URebUKHUpPXAClAXZDjQD8Eyc8kOq4 http://toolbarqueries.google.es/url?rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=jY2QPnpnGbYZS5XDYdtupjb1pzqzGs&usg=n7sTxtsfL3PpS8X0RAtXDIO2haWbAq http://toolbarqueries.google.es/url?rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=lWiSihqHPhYStJFYcNUjmcbQM27eqb&usg=08x5FWJIOOIEHcy2xkx8DOXFBiUBgp http://toolbarqueries.google.es/url?rct=j&url=https%3A%2F%2Foncarbrands.com/&ved=jY2QPnpnGbYZS5XDYdtupjb1pzqzGs&usg=n7sTxtsfL3PpS8X0RAtXDIO2haWbAq http://toolbarqueries.google.es/url?source=web&rct=j&url=https%3A%2F%2Fwww.oncarbrands.com&ved=XDUKob0spXmfVLM54hXhDWb3tr5Y4i&usg=PeMRZM5oFWRapxptxvSgGxDaKaB0q5 http://toolbarqueries.google.es/url?source=web&rct=j&url=https%3A%2F%2Foncarbrands.com&ved=26XTkMhBGHaDx6TOcwRqam3lJcsRA2&usg=6gfNENJMgzfuNcUKfBWxwzVugPcLjh http://toolbarqueries.google.es/url?rct=j&url=https%3A%2F%2Foncarbrands.com&ved=lWiSihqHPhYStJFYcNUjmcbQM27eqb&usg=08x5FWJIOOIEHcy2xkx8DOXFBiUBgp Thanks for every other informative site. The place else may just I get that kind of information written in such an ideal means? I have a venture that I’m just now operating on, and I have been on the look out for such information.
Oct 06, 2021 01:34:10 PM
You there, this is really good post here. Thanks for taking the time to post such valuable information. Quality content is what always gets the visitors coming. mega888,mega888 apk,mega888 download
Oct 07, 2021 09:15:09 PM
Hi! This is my first visit to your blog! We are a collection of volunteers and starting a new project in a community in the same niche. Your blog provided us valuable information to work on. You have done a extraordinary job! Urban Treasure showroom
Oct 09, 2021 04:42:08 PM
New web site is looking good. Thanks for the great effort.
Oct 10, 2021 01:05:46 AM
That's it's better that you ought to best suited examination in advance of making. It is easy to make improved upload that way. Far Cry 3
Oct 10, 2021 01:47:25 AM
Images entirely on your internet site even when creating awareness swiftly a small amount of sum submits. Rewarding technique for lasting upcoming, I will be book-marking at that time grow to be the surface area end develops inches upwards inches. Far Cry 3
Oct 10, 2021 02:26:08 AM
Hello! I recently wish to give a enormous thumbs up for your great information you’ve got here for this post. I’ll be coming back to your website for additional soon. Nintendo 3DS
Oct 10, 2021 04:31:03 PM
It's always equally an exceptional write-up it's my job to undeniably appreciated checking out. It is far from conclusively day-to-day it's my job to improve the way to determine just about anything. https://www.pr6directory.com/5-best-water-sports-activities-in-san-diego/
Oct 11, 2021 04:35:10 PM
You there, this is really good post here. Thanks for taking the time to post such valuable information. Quality content is what always gets the visitors coming.
Oct 11, 2021 10:44:55 PM
I really love the way information is presented in your post. I have added you in my social bookmark. Cheers. Portable Photo Printer
Oct 11, 2021 11:16:50 PM
very interesting post.this is my first time visit here.i found so mmany interesting stuff in your blog especially its discussion..thanks for the post! dark web links
Oct 12, 2021 08:01:57 PM
I read that Post and got it fine and informative.
Oct 13, 2021 11:44:53 PM
This is furthermore a fantastic write-up my partner and i really enjoyed considering. It really is generally not very each day my partner and i support the possibility to look at something. do my python homework for me
Oct 14, 2021 09:08:55 PM
Thanks for sharing this great article. Hi, I am John Smith, I am working as a technical manager at email support. I have 3 years of experience in this field. If you have any problems related to Outlook keeps asking for password , then please contact us for help related to email problems.
Oct 16, 2021 03:18:07 PM
JAMESIs anyone in this article in facebook and also want to friend me personally? What are your own myspace names, it is a great submit in addition. Also is right now there a great Rss I couldn’t locate it? poker88
Oct 16, 2021 11:17:54 PM
This really is both equally a very good information when i rather definitely preferred verifying. This may not be at all times i always get likely to see a challenge. https://themillionaireposts.com/ido-fishman-shares-steps-to-creating-a-fitness-program/
Oct 17, 2021 01:48:40 PM
I’m impressed, I have to admit. Genuinely rarely can i encounter a blog that’s both educative and entertaining, and without a doubt, you’ve hit the nail for the head. Your notion is outstanding; the thing is something inadequate folks are speaking intelligently about. My business is very happy that we found this within my seek out some thing in regards to this. แทงบอลออนไลน์
Oct 18, 2021 12:04:18 PM
Hi my name is Jimmy Andrew i am from the technical team if you are facing any issue to setup hp printer you can visit our site 123.hp.com/setup. Here you find solutions to your problems.
Oct 18, 2021 04:52:02 PM
Hi my name is Alina Crew i am from the technical team if you are facing any issue to setup hp printer you can visit our site 123.hp.com/setup. Here you find solutions to your problems.
Oct 18, 2021 05:27:20 PM
Online Assignment Help is focused on delivering top-quality writing, making it the best option for students to buy assignments online. We have established the necessary mechanism to ensure that the highest standards of quality in the industry, so that students are given the best assignment help.
Oct 18, 2021 07:18:09 PM
Please share more like that.
Oct 18, 2021 07:44:52 PM
https://mobisoftinfotech.com
Oct 18, 2021 07:47:34 PM
If you are a college-going student then this is the point that can build or destroy your career and an immeasurable performance in tasks and most importantly in assignments can set a foundation for your bright future ahead. If you want to get assignment help from any reliable website then, there is nothing wrong to get yourself relaxed. Because a good grade is a requirement to sustain yourself in this extremely competitive world where every other scholar is delivering his best shot to be in a race.
Oct 18, 2021 09:35:27 PM
Rapidly this particular amazing web site ought to irrefutably turned out to be acknowledged inside all the website many people, because of the diligent content articles or even evaluations or even suggestions. Ido Fishman
Oct 19, 2021 12:45:15 PM
Hi, I am Alina. If you are looking for SEO Services for Accountants so, you are in the right place. Here we provide SEO Services at affordable prices as per our consumer budget. Also, we have a well knowledgeable team who gives you the best results. Whether it’s in website traffic, ranking, organic keywords, etc.
Oct 19, 2021 01:08:49 PM
Hi, Myself Baron Corrz. I achieved the biggest success in tech support. We are the best service providers technical field. If you have any issue related with your epson print head alignment. So, don't worry about it, this is the most common issue face by every epson printer users so, here I'm available to fix this issue.
Oct 19, 2021 04:34:27 PM
Our Instant assignment help comes at your doorstep before the deadline. Even if you want the Instant assignment help within a day, we are ready for that. Furthermore, all this comes at a reasonable price. So that you don’t need to think twice for Instant assignment help.
Oct 19, 2021 09:43:13 PM
In this competitive world, students want to secure more marks than their peers as they always want to be on top. For this reason, they never allow anyone else to let down their confidence level. So if you are willing to avail of certified courses without any hassle then immediately scroll your browser and login to Custom essay help services.
Oct 20, 2021 04:09:03 AM
This article was written by a real thinking writer. I agree many of the with the solid points made by the writer. I’ll be back. modalert
Oct 20, 2021 01:30:16 PM
Studying in Melbourne is a vision for many young people across the world. High employability of its courses and usually a great quality of life make its colleges much required after by students both from within and outside the country. We provided the services of <a href="https://myassignmenthelperonline.com/assignment-help-melbourne.html"> Assignment Help Melbourne</a>, and we have poured heart and soul into creating one of the best platforms for helping every student to reach their educational goals, working with a team of specialized writers.
Oct 20, 2021 01:38:17 PM
Nice to be visiting your blog again, it has been months for me. Well this article that i've been waited for so long. I need this article to complete my assignment in the college, and it has same topic with your article. Thanks, great share. https://linktr.ee/Landayshaki
Oct 20, 2021 07:32:12 PM
Do you write to research a paper writing topic? A useful way to find a topic that makes one want to write a good research topic is to use a topic you've already written about. Take one of the essays you wrote for this particular easy research paper topic and see if you can elaborate on the topic. How much more detail can you add? Has there been any new research on that topic? In academia, it is quite common to broaden and deepen your previous research, so you can start now. Running out of topics to write? Check out a good topic for a research paper that can help you to choose the right research paper topic.
Oct 21, 2021 07:23:31 PM
I wanted to thank you for this great read!! I definitely enjoying every little bit of it I have you bookmarked to check out new stuff you post.zaya nurai island day pass
Oct 22, 2021 01:17:26 PM
We, 123 hp setup is an independent HP technical support service provider that provides rapid online assistance to cope with computer and laptop difficulties that are interfering with people's work. You will receive a solution for any problem, such as software installation, virus scan, and antivirus installation, etc., provided by expert specialists, along with helpful assistance and valuable recommendations to avoid such difficulties in the future.
Oct 23, 2021 03:42:30 PM
Well i’m from Ireland, and throughout Ireland bono and the lads are unquestionably liked and also could certainly not do really much incorrect, we all love them. shopping
Oct 23, 2021 09:28:28 PM
im surpirsed this post hasnt got more attention, get some backlinks friend and move it to the top of Google. KIU of Uganda
Oct 24, 2021 06:54:57 AM
sales in replica shopping mall, lowest price in domestic delivery, [url=https://flexshop-1.com]레플리카[/url] bag, replica shoes, replica watch, replica clothing, 24-hour consultation center operation, size exchange possible.
Oct 24, 2021 06:56:07 AM
Oct 24, 2021 06:56:49 AM
Are you looking for op-guide op site rankings? <a href="https://edugoncalves.de">오피가이드</a> This is an entertainment site for running information. It is divided into two sites and it is confusing to the point that you do not know which one is the real one. If you are looking for Daegu op guide, night empire, opga6net information, you can solve it here.
Oct 24, 2021 06:57:23 AM
Solve your life in Busan wisely at Busan Bibigi. Solving your concerns and solving Busan nightlife. At you can find popular places for Busan Run, Budal, Seulbu, and Busan Massage at a reasonable price. Now, let's make a fun and healthy nightlife in Busan Bibigi.
Oct 24, 2021 06:57:52 AM
Replica's pride This is a high-end luxury watch shopping mall site. Men's replicas, women's bags, watches, shoes, shoes, etc. The products you want are gathered here. When you visit our luxury watch replica, you can't just leave. I will buy it unconditionally.
Oct 24, 2021 06:58:23 AM
Replica's pride This is a high-end luxury watch shopping mall site. Men's replicas, women's bags, watches, shoes, shoes, etc. The products you want are gathered here. When you visit our luxury watch replica, you can't just leave. I will buy it unconditionally.1
Oct 24, 2021 03:22:44 PM
I would like to say that this blog really convinced me to do it! Thanks, very good post.bokeb
Oct 24, 2021 05:24:48 PM
I definitely enjoying every little bit of it. It is a great website and nice share. I want to thank you. Good job! You guys do a great blog, and have some great contents. Keep up the good work.largo cream in islamabad
Oct 24, 2021 08:20:36 PM
Wow! This could be one particular of the most helpful blogs We’ve ever arrive across on this subject. Actually Excellent. I am also an expert in this topic therefore I can understand your effort. News InVogue
Oct 24, 2021 10:05:47 PM
That is a very good viewpoint, however isn’t create any kind of sence at all preaching about that will mather. Just about any approach gives thanks and also thought about aim to reveal your current article in to delicius but it surely is apparently an issue using your sites is it possible please recheck this. many thanks once more. bokeb
Oct 26, 2021 08:37:17 PM
오피스타 알아보시나요? 스타 접속오류, opstar링크, opstar, 오피스타 도메인 해당 오류를 모두 점검하였습니다. 이제 안전된 곳에서 건전한 마사지샵을 즐겼으면 합니다.
Oct 27, 2021 03:39:17 PM
It is possible to set up a computer in many ways. 'Canon IJ Setup' app may perform a variety of functions, including printing, scanning, and configuring the network. This software may be used immediately once it has been installed. For additional information, go visit the manufacturer's website. When you're finished, type in the model number and version number of your printer's operating system in the relevant areas. Once the installation is complete, look for the utility folder in which the Canon IJ Setup software is located.
Oct 27, 2021 07:35:32 PM
Undeniably believe that which you stated. Your favorite reason appeared to be on the web the easiest thing to be aware of. I say to you, I certainly get annoyed while people think about worries that they plainly do not know about. You managed to hit the nail upon the top as well as defined out the whole thing without having side effect , people could take a signal. Will probably be back to get more. Thanks yellow brick cinema
Oct 28, 2021 06:56:38 AM
쇼핑몰 사이트 순위 추천 1위 | 명품 신발 가방 시계【어딕티브】
Oct 29, 2021 08:23:21 AM
레플리카 최저가로 구입할 수 있는 픽스레플입니다. 최고의 상품 퀄리티 최저가로 제공해 드립니다. 이제 명품 비싸게 주고 구입하지마세요. 레플리카 1위 쇼핑몰 사이트 픽스 여러분께 좋은 정보로 제공해 드리겠습니다.
Oct 30, 2021 09:11:32 PM
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free.Post-Covid Education
Nov 02, 2021 12:42:03 AM
Love to read it,Waiting For More new Update and I Already Read your Recent Post its Great Thanks.
Nov 02, 2021 07:42:49 PM
I am really thankful to the holder of this web site who has shared this impressive post at at this time. <a href="https://technewmind.com/2021/09/17/f95zone-summertime-saga-for-newbies/">f95zone-summertime-saga-for-newbies</a>
Nov 02, 2021 08:45:49 PM
There are various ways to resolve the Ricoh Printer Offline issue. Follow these points.
• Choose ‘Print and Share’ option on your printer screen.
• Now choose the ‘Change’ option.
• Navigate to ‘Profiles’ and click profile.
• Choose ‘Edit’ and select your specific printer channel under ‘Channels.’
• Click on the ‘Trigger’ points.
• Choose the ‘Printer error levels’ option.
• Locate ‘Ricoh Printer Offline’ error and modify the error level settings.
• In the ‘Error level’ choose ‘Warning’ and hit ‘OK.’
• Hit ‘OK’ again for all settings to be applied and then tap ‘Close.’
Nov 04, 2021 12:13:56 AM
I think this is one of the most vital information for me. And i am glad reading your article. But wanna remark on few general things, The website style is perfect, the articles is really great : D. Good job, cheers film production
Nov 04, 2021 06:28:34 PM
Thanks for the blog loaded with so many information. Stopping by your blog helped me to get what I was looking for.
Nov 06, 2021 06:36:09 AM
If you feel lost in your life, give us a call, we will find the solutions for you. Love, work, finance ... finally live your life. You've already waited too long.
Nov 06, 2021 01:43:38 PM
When students use the service, they take additional steps to ensure their privacy. They promise that you will not become caught cheating with the security of passwords and encryption on all the registration forms and personal information. Do not risk a service that makes no assurances to you for your grades and your future. Confide on online class helpers for your degree. Apart from taking an online class on behalf of you, these class helpers do also the “<a href="https://www.takemyonlineclassesforme.com/">Take My Online Class</a>” and students can book the grades in advance. They are very experts to take the exam on behalf of you and able to earn best grades. Do not play with your future. Work with the industry's most professional provider and obtain good grades in college and beyond.
Nov 06, 2021 03:58:07 PM
It was a real pleasure getting to your site a short while ago. I came here this day hoping to find out something new. And I was not upset. Your ideas about new solutions on this subject were helpful and a good help to me. Thank you for making time to write out these things as well as sharing your thinking. cheap domain name
Nov 08, 2021 05:04:24 PM
From all the blogs I’ve read lately, this at one seems to be the most moving – it gave me something to consider about. [Reply] Visto Canada ETA
Nov 09, 2021 10:27:24 PM
Be grateful you for spending time to speak about this, I think strongly about that and delight in reading read more about this topic. Whenever possible, just like you become expertise, do you mind updating your web site with a lot more details? It can be highly great for me. Two thumb up in this article! INDIAN VISA FROM AUSTRALIA
Nov 11, 2021 06:02:10 AM
Please share more like that.
Nov 11, 2021 09:49:56 PM
Hi, I'm Ushimitucozz. I achieved the biggest success in tech support. We are the best service providers technical field. If you are facing a brother printer in error state issue So, don't worry about it, this is the most common problem face by every brother printer users so, here I'm available to fix this issue. we have a big firm and all are Highly experienced technical experts. They are 24/7 time available for you.
Nov 12, 2021 01:33:59 PM
your blog is very good. It was very well authored and easy to understand. Unlike additional blogs I have read which are really not good. I also found your posts very interesting Visto Canada ETA
Nov 12, 2021 10:11:44 PM
We’re a group of volunteers and opening a new scheme in our community. Your web site offered us with valuable info to work on. You have done an impressive job and our entire community will be thankful to you. day care rockville md
Nov 14, 2021 08:35:37 PM
I admit, I have not been on this web page in a long time... however it was another joy to see It is such an important topic and ignored by so many, even professionals. I thank you to help making people more aware of possible issues.
Nov 15, 2021 08:20:07 AM
This was exceptional reading and fabulous site. Keep up great work!
Nov 19, 2021 07:29:34 PM
Hi myself Luisa Evans. Working as backend support executive. I have 4 years of experience in this field. If your yahoo mail not receiving emails properly, then visit our website.
Nov 20, 2021 06:55:10 PM
I love the way you write and share your niche! Very interesting and different! Keep it coming!
Nov 21, 2021 08:19:45 PM
Very useful post. This is my first time i visit here. I found so many interesting stuff in your blog especially its discussion. Really its great article. Keep it up.
Nov 27, 2021 03:08:06 PM
That's what the beatbox chart says <a href="https://bitball1004.com/">비트볼</a>
It's going up and down in real time. Buy it if you think it's going up,
If it's likely to fall, it's a way to invest in selling.
Nov 28, 2021 07:42:50 PM
In the case of not setting up a country separately, advertising seemed to
be carried out in countries <a href="https://ads-google1.com/">구글애즈 </a> with
low installation costs in line with the budget and installation costs.
If the purpose is to secure the number of downloads at a low cost,
the execution of small advertisements worth between 3,000 won and 5,000 won is not bad.
Nov 29, 2021 11:05:10 PM
For those of you who've done Holdham, as we go all the way
to the river, flushes <a href="https://pokercastle.casino/">온라인홀덤</a> and
titles come out very often It's a card, but it's boring even with your own two fairs.
That person in front of me sat on the first day..
I'm sorry to him, but he's coming down with 50 wins.
The next day, I'll sit down again and do it right.
Nov 30, 2021 05:52:02 AM
Hello! Such a very Informative Article. I gain the Lot of Information about <a href="https://www.ritirewaz.in/wedding-catering-ahmedabad"> Wedding Catering Services in Ahmedabad</a> . Now if you want to get the knowledge about the world then you need to visit our official website. That why I Share the like of the web.
Dec 01, 2021 12:46:51 AM
Thanks for this article very helpful. thanks.
Dec 01, 2021 03:04:16 PM
I think you have observed some very interesting details , thankyou for the post. https://tw.nextmgz.com/realtimenews/news/20332364
Dec 01, 2021 03:09:00 PM
The comfort one gets while playing from your home cannot be beaten. Baccarat is just a game that's given luxury treatment in several casinos.
Dec 03, 2021 12:45:41 AM
There is numerous separate years Los angeles Weight reduction eating plan with each a person is a necessity. The pioneer part can be your original getting rid of belonging to the extra pounds. la weight loss 犀利士哪裡買
Dec 03, 2021 02:08:43 PM
If you click on the headset icon in the lower <a href="https://bitball1004.com/">비트볼</a> right corner,
you'll see a Kakaotalk-like window where you'll receive seed to practice on the test net
Dec 04, 2021 07:34:04 PM
In fact, in the foreign exchange market, the exchange rate is the exchange rate between the selling rate and the purchase rate
It was written. From a bank dealer's point of view, the foreign exchange market's buying rate and selling rate are
The rate of purchase is in the process of buying foreign exchange because it's already fixed
The selling rate is the exchange rate at which the bank dealer receives the foreign exchange
It is the exchange rate applied in the process of selling.<a href="https://bitball1004.com/">비트볼</a>
A lot of people, like FX City margin trading, use this approach
It is said that they are generating profits.
Dec 04, 2021 11:32:39 PM
If you write a review, I hope it will help those who are worried
To be honest with you, I'll pay for it The oil helped me <a href="https://ma-cho.com/">마사지</a> relieve cellulite because it's effective in my blood circulation,
and I was always worried about my forearm fat, but you didn't have to tell me
Dec 07, 2021 01:24:18 PM
The massage teacher will bring his own massage mat and set the bed. The well-maintained sheets
and towels made me feel comfortable. It was nice <a href="https://ma-cho.com/">홈타이</a> that you didn't have to prepare any clothes for the massage
Dec 07, 2021 07:37:56 PM
I’ve been exploring for a little bit for any high-quality articles or blog posts on this sort of area . Exploring in Yahoo I at last stumbled upon this site. Reading this info So i’m happy to convey that I’ve an incredibly good uncanny feeling I discovered exactly what I needed. I most certainly will make sure to do not forget this web site and give it a look regularly. marijuana dispensary california
Dec 09, 2021 05:30:03 PM
pay someone to write my term paper is an excellent option for everyone who has difficulty with homework. A group of professionals is ready to complete your coursework in the timeframe you set. Even in less than three hours! Customer service is available 24*7 days and is always concerned about your well-being. Quality is proven by many years in the company and a large number of delighted customers.
https://www.allassignmenthelp.com/write-my-term-paper.html
Dec 10, 2021 05:42:44 PM
I would read more on this topic if the info provided were as interesting as what you have written in this article. Don’t stop caring about the content you write. 犀利士哪裡買
Dec 11, 2021 06:58:08 PM
It’s not that I want to duplicate your website, but I really like the style. Could you tell me which design are you using? Or was it custom made? Personal Classified Ads
Dec 14, 2021 02:11:09 PM
Fantastic blog! Do you have any tips and hints for aspiring writers? I’m planning to start my own website soon but I’m a little lost on everything. Would you propose starting with a free platform like WordPress or go for a paid option? There are so many options out there that I’m completely overwhelmed .. Any suggestions? Many thanks!
Dec 17, 2021 03:51:20 PM
I went to a unique bar with my friends
It usually opens around 7 p.m. <a href="https://pokercastle.casino/">온라인홀덤</a> but I just tasted it after dinner
We have beer and drinks but we ordered drinks
Dec 18, 2021 03:53:27 PM
this is really nice to read..informative post is very good to read..thanks a lot!
Dec 22, 2021 04:06:04 PM
I think it's the best because there are many courses
It's not at home. It's at hotels <a href="https://pokercastle.casino/">출장마사지</a> You can be very satisfied without any regrets
Dec 25, 2021 07:23:26 PM
I just couldn't leave your website before telling you that I truly enjoyed the top quality info you present to your visitors? Will be back again frequently to check up on new posts. check more info about birthday cakes
Dec 25, 2021 11:34:04 PM
Positive site, where did u come up with the information on this posting? I'm pleased I discovered it though, ill be checking back soon to find out what additional posts you include.
Dec 30, 2021 04:56:51 PM
There's a clean smoking room inside
Smokers were comfortable, <a href="https://pokercastle.casino/">온라인홀덤</a> and I, a non-smoker, was able to enjoy myself
Not only Holdham, but there is also a game called Black Jack. I'm going to learn that later Addicted
Dec 30, 2021 08:31:01 PM
of course like your web-site however you need to check the spelling on quite a few of your posts. A number of them are rife with spelling issues and I to find it very bothersome to inform the reality however I’ll surely come back again. 威而鋼網購
Jan 02, 2022 01:55:21 AM
Its a great pleasure reading your post.Its full of information I am looking for and I love to post a comment that "The content of your post is awesome" Great work.
Jan 02, 2022 04:05:49 AM
This is a great inspiring article.I am pretty much pleased with your good work.You put really very helpful information. Keep it up. Keep blogging. Looking to reading your next post. building the peninsula two aventura
Jan 05, 2022 01:32:15 AM
You must be very astute at research and writing. This shows up in your original and unique content. I agree with your primary points on this topic. This content should be seen by more readers. https://www.romaslotvip.com
Jan 09, 2022 10:33:25 PM
It is a great website.. The Design looks very good.. Keep working like that!. <a href="https://voyance-telephone-gaia.com/">voyance-telephone-gaia.com</a>
https://voyance-telephone-gaia.com/
Jan 11, 2022 02:59:48 PM
I would like to say that this blog really convinced me to do it! Thanks, very good post.
Jan 12, 2022 10:33:24 PM
Great article. I appreciate your attention to this subject and I learned a lot kubslot99.com
Jan 13, 2022 01:23:26 AM
We have sell some products of different custom boxes.it is very useful and very low price please visits this site thanks and please share this post with your friends.
Jan 13, 2022 01:59:40 PM
If more people that write articles involved themselves with writing great content like you, more readers would be interested in their writings. I have learned too many things from your article.
Jan 14, 2022 11:51:07 AM
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free.
Jan 14, 2022 10:50:54 PM
We have sell some products of different custom boxes.it is very useful and very low price please visits this site thanks and please share this post with your friends. <a href="https://www.beritajudol.com/">berita judol</a>
Jan 16, 2022 09:55:04 PM
Yes i am totally agreed with this article and i just want say that this article is very nice and very informative article.I will make sure to be reading your blog more. You made a good point but I can't help but wonder, what about the other side? !!!!!!THANKS!!!!!!
Jan 18, 2022 02:57:03 PM
I called and the counselor kindly explained it, so it was my first time,
so I made a reservation for a Thai massage I didn't have anything to prepare because the therapist brought everything
I needed <a href="https://ma-cho.com/">출장안마</a> for the massage
Jan 18, 2022 06:46:49 PM
I’ve been absent for a while, but now I remember why I used to love this website. Thank you, I will try and check back more often. How frequently you update your site?<a href="https://easyslot66.com/">eazyslot เครดิต ฟรี</a>
Jan 18, 2022 09:35:08 PM
Welcome to Coffee Units, the authorized seller of Coffee products in the United State. We offer varieties of products.
Jan 27, 2022 06:38:27 PM
Thanks for another excellent post. Where else could anybody get that type of info in such an ideal way of writing? In my opinion, my seeking has ended now. https://voyance-telephone-gaia.com
Jan 28, 2022 11:37:58 PM
Thank you for some other informative blog. Where else could I get that type of information written in such an ideal means? I have a mission that I’m just now working on, and I have been at the look out for such information.
Jan 29, 2022 11:45:20 PM
Keep up the good work , I read few posts on this web site and I conceive that your blog is very interesting and has sets of fantastic information.
Jan 31, 2022 01:52:30 PM
It relieves fatigue from head to toe
Sit down and massage <a href="https://ma-cho.com/">출장홈타이</a> your head
As soon as I was done, I went to my husband's room and fainted
He fell asleep I love home thai massage
Feb 02, 2022 08:26:04 PM
<a href="https://freeprokeys.com/icecream-pdf-split-merge-pro-crack/">split merge pro crack</a>
<a href="https://freeprokeys.com/all-in-one-toolbox-pro-apk-cracked/">all in one toolbox pro apk cracked</a>
<a href="https://freeprokeys.com/wondershare-filmora-crack-2/">wondershare filmora crack</a>
<a href="https://freeprokeys.com/cockos-reaper-crack/">cockos reaper crack</a>
<a href="https://freeprokeys.com/altium-designer-crack/">altium designer crack</a>
<a href="https://freeprokeys.com/microsoft-office-crack-3/">microsoft office crack</a>
<a href="https://freeprokeys.com/activepresenter-crack/">activepresenter crack</a>
Feb 02, 2022 08:26:17 PM
<a href="https://freeprokeys.com/icecream-pdf-split-merge-pro-crack/">split merge pro crack</a>
<a href="https://freeprokeys.com/all-in-one-toolbox-pro-apk-cracked/">all in one toolbox pro apk cracked</a>
<a href="https://freeprokeys.com/wondershare-filmora-crack-2/">wondershare filmora crack</a>
<a href="https://freeprokeys.com/cockos-reaper-crack/">cockos reaper crack</a>
<a href="https://freeprokeys.com/altium-designer-crack/">altium designer crack</a>
<a href="https://freeprokeys.com/microsoft-office-crack-3/">microsoft office crack</a>
<a href="https://freeprokeys.com/activepresenter-crack/">activepresenter crack</a>
Feb 09, 2022 08:05:05 PM
Your website is really cool and this is a great inspiring article.
Feb 10, 2022 03:20:11 PM
Thanks for the blog loaded with so many information. Stopping by your blog helped me to get what I was looking for. Alexander Malshakov
Feb 10, 2022 10:45:17 PM
Thanks to you, I'll not only maintain <a href="https://ads-bos.com/">애드워즈</a>
Feb 12, 2022 08:55:47 PM
<a href="https://surgeprotections.com/best-surge-protector-for-refrigerator-2/">surge protector for fridge</a>
<a href="https://surgeprotections.com/best-surge-protector-for-refrigerator-2/">surge protection for refrigerator</a>
<a href="https://surgeprotections.com/best-surge-protector-for-refrigerator-2/">power surge protector for refrigerator</a>
<a href="https://surgeprotections.com/best-surge-protector-for-refrigerator-2/">surge suppressor for refrigerator</a>
<a href="https://surgeprotections.com/best-travel-power-strip/?utm_source=rss&utm_medium=rss&utm_campaign=best-travel-power-strip">best travel surge protectors</a>
<a href="https://surgeprotections.com/best-travel-power-strip/?utm_source=rss&utm_medium=rss&utm_campaign=best-travel-power-strip">international travel power strip</a>
<a href="https://surgeprotections.com/best-travel-power-strip/?utm_source=rss&utm_medium=rss&utm_campaign=best-travel-power-strip">travel power strips</a>
<a href="https://surgeprotections.com/best-travel-power-strip/?utm_source=rss&utm_medium=rss&utm_campaign=best-travel-power-strip">power strip for travel</a>
<a href="https://surgeprotections.com/best-travel-power-strip/?utm_source=rss&utm_medium=rss&utm_campaign=best-travel-power-strip">best travel surge protector</a>
<a href="https://surgeprotections.com/best-travel-power-strip/?utm_source=rss&utm_medium=rss&utm_campaign=best-travel-power-strip">compact travel power strip</a>
<a href="https://surgeprotections.com/best-travel-power-strip/?utm_source=rss&utm_medium=rss&utm_campaign=best-travel-power-strip">power strip for international travel</a>
<a href="https://surgeprotections.com/best-travel-power-strip/?utm_source=rss&utm_medium=rss&utm_campaign=best-travel-power-strip">travel power strip</a>
<a href="https://surgeprotections.com/best-travel-power-strip/">best international travel surge protector</a>
<a href="https://surgeprotections.com/best-surge-protector-for-air-conditioner">best surge protector for air conditioner</a>
<a href="https://surgeprotections.com/best-surge-protector-for-air-conditioner">best ac surge protector</a>
<a href="https://surgeprotections.com/best-surge-protector-for-air-conditioner">best surge protector for ac</a>
<a href="https://surgeprotections.com/best-whole-house-surge-protector-2021/">best whole house surge protector 2021</a>
<a href="https://surgeprotections.com/best-whole-house-surge-protector-2021/">how often should surge protectors be replaced</a>
<a href="https://surgeprotections.com/best-whole-house-surge-protector-2021/">whole house surge protector cost</a>
<a href="https://surgeprotections.com/best-whole-house-surge-protector-2021/">do whole house surge protectors really work?</a>
<a href="https://surgeprotections.com/best-surge-protector-for-generator/">best surge protector for generator</a>
<a href="https://surgeprotections.com/best-surge-protector-for-generator/">surge protectors for portable generators</a>
<a href="https://surgeprotections.com/best-surge-protector-for-generator/">portable generator surge protector</a>
<a href="https://surgeprotections.com/best-surge-protector-for-generator/">surge protector with generator</a>
<a href="https://surgeprotections.com/best-surge-protector-for-generator/">surge protector for generator</a>
<a href="https://surgeprotections.com/best-surge-protector-for-generator/">can a surge protector be used on a generator</a>
<a href="https://surgeprotections.com/best-surge-protector-for-generator/">surge protector generator</a>
<a href="https://surgeprotections.com/power-strip-vs-surge-protector/">powerstrip vs surge protector</a>
<a href="https://surgeprotections.com/power-strip-vs-surge-protector/">what is a surge protector vs power strip</a>
<a href="https://surgeprotections.com/power-strip-vs-surge-protector/">power strip vs surge protector</a>
<a href="https://surgeprotections.com/power-strip-vs-surge-protector/">surge protector vs power strip</a>
<a href="https://surgeprotections.com/surge-protector-for-gaming-pc/">best power surge protector for gaming pc</a>
<a href="https://surgeprotections.com/surge-protector-for-gaming-pc/">surge protector joules for gaming pc</a>
<a href="https://surgeprotections.com/surge-protector-for-gaming-pc/">best surge protector for gaming pc</a>
<a href="https://surgeprotections.com/best-whole-house-surge-protector/">leviton 51120-1 panel protector, 120/240-volt</a>
<a href="https://surgeprotections.com/best-whole-house-surge-protector/">square d surge protector whole house</a>
<a href="https://surgeprotections.com/best-whole-house-surge-protector/">cutler hammer whole house surge protector</a>
Feb 14, 2022 02:35:44 PM
<a href="https://freeprokeys.com/idm-crack/">idm crack</a>
<a href="https://freeprokeys.com/ableton-live-crack/">ableton live crack</a>
<a href="https://freeprokeys.com/photopia-director-crack/">photopia director crack</a>
<a href="https://freeprokeys.com/light-invoice-crack/">light invoice crack</a>
<a href="https://freeprokeys.com/adina-system-crack/">adina system crack</a>
<a href="https://freeprokeys.com/mediamonkey-gold-crack/">mediamonkey gold crack</a>
<a href="https://freeprokeys.com/app-builder-crack/">app builder crack</a>
<a href="https://freeprokeys.com/ashampoo-soundstage-pro-crack/">ashampoo soundstage pro crack</a>
Feb 15, 2022 07:17:12 PM
I just want to let you know that I just check out your site and I find it very interesting and informative.. http://www.loreal-paris.co.th
Feb 16, 2022 08:32:40 PM
<a href="https://surgeprotections.com/best-surge-protector-for-refrigerator-2/">surge protector for fridge</a>
<a href="https://surgeprotections.com/best-surge-protector-for-refrigerator-2/">surge protection for refrigerator</a>
<a href="https://surgeprotections.com/best-surge-protector-for-refrigerator-2/">power surge protector for refrigerator</a>
<a href="https://surgeprotections.com/best-surge-protector-for-refrigerator-2/">surge suppressor for refrigerator</a>
<a href="https://surgeprotections.com/best-travel-power-strip/?utm_source=rss&utm_medium=rss&utm_campaign=best-travel-power-strip">best travel surge protectors</a>
<a href="https://surgeprotections.com/best-travel-power-strip/?utm_source=rss&utm_medium=rss&utm_campaign=best-travel-power-strip">international travel power strip</a>
<a href="https://surgeprotections.com/best-travel-power-strip/?utm_source=rss&utm_medium=rss&utm_campaign=best-travel-power-strip">travel power strips</a>
<a href="https://surgeprotections.com/best-travel-power-strip/?utm_source=rss&utm_medium=rss&utm_campaign=best-travel-power-strip">power strip for travel</a>
<a href="https://surgeprotections.com/best-travel-power-strip/?utm_source=rss&utm_medium=rss&utm_campaign=best-travel-power-strip">best travel surge protector</a>
<a href="https://surgeprotections.com/best-travel-power-strip/?utm_source=rss&utm_medium=rss&utm_campaign=best-travel-power-strip">compact travel power strip</a>
<a href="https://surgeprotections.com/best-travel-power-strip/?utm_source=rss&utm_medium=rss&utm_campaign=best-travel-power-strip">power strip for international travel</a>
<a href="https://surgeprotections.com/best-travel-power-strip/?utm_source=rss&utm_medium=rss&utm_campaign=best-travel-power-strip">travel power strip</a>
<a href="https://surgeprotections.com/best-travel-power-strip/">best international travel surge protector</a>
<a href="https://surgeprotections.com/best-surge-protector-for-air-conditioner">best surge protector for air conditioner</a>
<a href="https://surgeprotections.com/best-surge-protector-for-air-conditioner">best ac surge protector</a>
<a href="https://surgeprotections.com/best-surge-protector-for-air-conditioner">best surge protector for ac</a>
<a href="https://surgeprotections.com/best-whole-house-surge-protector-2021/">best whole house surge protector 2021</a>
<a href="https://surgeprotections.com/best-whole-house-surge-protector-2021/">how often should surge protectors be replaced</a>
<a href="https://surgeprotections.com/best-whole-house-surge-protector-2021/">whole house surge protector cost</a>
<a href="https://surgeprotections.com/best-whole-house-surge-protector-2021/">do whole house surge protectors really work?</a>
<a href="https://surgeprotections.com/best-surge-protector-for-generator/">best surge protector for generator</a>
<a href="https://surgeprotections.com/best-surge-protector-for-generator/">surge protectors for portable generators</a>
<a href="https://surgeprotections.com/best-surge-protector-for-generator/">portable generator surge protector</a>
<a href="https://surgeprotections.com/best-surge-protector-for-generator/">surge protector with generator</a>
<a href="https://surgeprotections.com/best-surge-protector-for-generator/">surge protector for generator</a>
<a href="https://surgeprotections.com/best-surge-protector-for-generator/">can a surge protector be used on a generator</a>
<a href="https://surgeprotections.com/best-surge-protector-for-generator/">surge protector generator</a>
<a href="https://surgeprotections.com/power-strip-vs-surge-protector/">powerstrip vs surge protector</a>
<a href="https://surgeprotections.com/power-strip-vs-surge-protector/">what is a surge protector vs power strip</a>
<a href="https://surgeprotections.com/power-strip-vs-surge-protector/">power strip vs surge protector</a>
<a href="https://surgeprotections.com/power-strip-vs-surge-protector/">surge protector vs power strip</a>
<a href="https://surgeprotections.com/surge-protector-for-gaming-pc/">best power surge protector for gaming pc</a>
<a href="https://surgeprotections.com/surge-protector-for-gaming-pc/">surge protector joules for gaming pc</a>
<a href="https://surgeprotections.com/surge-protector-for-gaming-pc/">best surge protector for gaming pc</a>
<a href="https://surgeprotections.com/best-whole-house-surge-protector/">leviton 51120-1 panel protector, 120/240-volt</a>
<a href="https://surgeprotections.com/best-whole-house-surge-protector/">square d surge protector whole house</a>
<a href="https://surgeprotections.com/best-whole-house-surge-protector/">cutler hammer whole house surge protector</a>
Feb 17, 2022 08:09:08 PM
I recently came across your blog and have been reading along. I thought I would leave my first comment. I don't know what to say except that I have enjoyed reading. Nice blog. I will keep visiting this blog very often.
ff
Feb 22, 2022 08:09:43 PM
Say you got a nice post. Much thanks again. Really Cool.
Feb 27, 2022 07:21:00 PM
<a href="https://www.hairfallguard.com/how-to-get-silly-putty-out-of-hair/">how to get putty out of hair</a>
<a href="https://www.hairfallguard.com/why-cant-caillou-grow-hair/">why doesn't caillou have hair</a>
<a href="https://www.hairfallguard.com/how-to-sharpen-hair-clippers/">how to sharpen electric hair clippers</a>
<a href="https://www.hairfallguard.com/creatine-hair-loss/">creatine hair loss reversible</a>
<a href="https://www.hairfallguard.com/why-cant-caillou-grow-hair/">does caillou have leukemia</a>
<a href="https://www.hairfallguard.com/head-hair-implants-between-hope-and-disillusion/">rich piana hair transplant</a>
<a href="https://www.hairfallguard.com/how-to-use-hair-tonic-rdr2/">how to use hair tonic rdr2</a>
Feb 27, 2022 11:42:18 PM
I was surfing net and fortunately came across this site and found very interesting stuff here. Its really fun to read. I enjoyed a lot. Thanks for sharing this wonderful information.
Mar 01, 2022 03:39:53 PM
I’ve been surfing online more than 5 hours today, yet I never found any interesting article like yours without a doubt. It’s pretty worth enough for me. Thanks...
Mar 14, 2022 12:27:44 PM
Perfect essay Writing is a difficult part of any student’s educational life and custom essay help online make this procedure simple and stress free to the every students. They assure to stand by you as your friend and help to protect your future. We all are experienced with the variation of present education where most experts resolve the issues within a few hours.
Mar 14, 2022 12:28:44 PM
We provide the best assignment help Australia service that is completely dedicated to serving the high quality educational help to students who are study in Australia. We cover the solutions for all the universities located in Australia. Here is the list of the Universities for which students can ask us for help at any time of the day. We are having an professional expert’s team of qualified assignments and essay writers in Australia.
Mar 22, 2022 09:13:04 AM
Get the best crypto insurance with https://cryptocurrencyinsurance.io/
Mar 22, 2022 11:46:26 AM
Furthermore, the cell that becomes Pilot Training has identical chromosomes and then has identical genetic information. However, they have different types of Pilot Training and DGCA Ground Classes. This organization is the process of Best Flight Academy in India. For more details, our experts at CEA Aviation Pvt Ltd will assist you.
http://ceaaviation.org
Mar 22, 2022 04:38:36 PM
Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work. Negotiation Training Course
Mar 23, 2022 08:45:13 PM
Nice knowledge gaining article. This post is really the best on this valuable topic. News
Mar 24, 2022 03:31:08 AM
Great articles and great layout. Your blog post deserves all of the positive feedback it’s been getting. zdrapki online na pieniadze
Mar 24, 2022 05:04:54 PM
Very useful info. Hope to see more posts soon!.
Mar 30, 2022 10:59:31 AM
Digital marketing course in laxmi nagar.Students will learn about The Structure of a C Program, Writing C Programs, Building an Executable Version, Debugging, Examining, and Running an Application Program, Data Types, Variables, Operands, Operators, Expressions, Input/ Output Management, Formatted Input Function, Control-Flow Statements, Control-Flow Program Statements, Looping Statements, and Control-Flow Program Statements in this session.
http://biitnewdelhi.com/
Mar 30, 2022 11:13:37 PM
Great articles and great layout. Your blog post deserves all of the positive feedback it’s been getting.
May 10, 2022 03:18:02 PM
This programme provides students with a variety of options. Digital marketing institute in laxmi nagar. As a fresher, after completing the programme, you can start working as:
• Accounts manager.
• Accountant trainee.
• Tally operator Data entry operator.
• Accounts assistant.
• Trainee accountant.
http://biitnewdelhi.com/
May 15, 2022 06:59:36 PM
Thanks for posting this info. I just want to let you know that I just check out your site and I find it very interesting and informative. I can't wait to read lots of your posts.
May 22, 2022 09:51:24 PM
very interesting post.this is my first time visit here.i found so mmany interesting stuff in your blog especially its discussion..thanks for the post!
sf
May 31, 2022 06:58:30 PM
Love what you're doing here guys, keep it up you also go here:
fhdfh
Jun 14, 2022 12:21:40 AM
I certainly enjoyed the method that you explore your experience and perception of the area of interest novelas online
Jun 16, 2022 05:36:49 AM
*An impressive share, I just given this onto a colleague who was doing a little analysis on this. And he in fact bought me breakfast because I found it for him.. smile. So let me reword that: Thnx for the treat! But yeah Thnkx for spending the time to discuss this, I feel strongly about it and love reading more on this topic. If possible, as you become expertise, would you mind updating your blog with more details? It is highly helpful for me. Big thumb up for this blog post! voyance numero gratuit
Jun 17, 2022 04:22:58 AM
I precisely desired to say thanks once again. I’m not certain the things that I might have used in the absence of the entire opinions revealed by you regarding that question. It had become a real difficult concern in my position, nevertheless spending time with your specialised avenue you resolved the issue made me to jump over joy. I’m just grateful for this advice and even wish you comprehend what a great job that you’re carrying out instructing most people all through your webpage. I know that you have never got to know any of us. doramasflix
Jun 18, 2022 05:24:14 AM
I precisely desired to say thanks once again. I’m not certain the things that I might have used in the absence of the entire opinions revealed by you regarding that question. It had become a real difficult concern in my position, nevertheless spending time with your specialised avenue you resolved the issue made me to jump over joy. I’m just grateful for this advice and even wish you comprehend what a great job that you’re carrying out instructing most people all through your webpage. I know that you have never got to know any of us. L-methylfolate shop
Jun 23, 2022 11:12:08 PM
Paid phone search services usually go with access to unlimited lookups, discounted background and cell phone reports, and an advanced People Search. You can use the peop search application to find old classmates, long lost relatives, or former co-workers. clicksud
Jun 25, 2022 05:43:52 AM
I precisely desired to say thanks once again. I’m not certain the things that I might have used in the absence of the entire opinions revealed by you regarding that question. It had become a real difficult concern in my position, nevertheless spending time with your specialised avenue you resolved the issue made me to jump over joy. I’m just grateful for this advice and even wish you comprehend what a great job that you’re carrying out instructing most people all through your webpage. I know that you have never got to know any of us. voyance par telephone
Jun 30, 2022 05:01:15 AM
I precisely desired to say thanks once again. I’m not certain the things that I might have used in the absence of the entire opinions revealed by you regarding that question. It had become a real difficult concern in my position, nevertheless spending time with your specialised avenue you resolved the issue made me to jump over joy. I’m just grateful for this advice and even wish you comprehend what a great job that you’re carrying out instructing most people all through your webpage. I know that you have never got to know any of us. Seriale Romanesti
Jul 06, 2022 05:09:37 AM
I precisely desired to say thanks once again. I’m not certain the things that I might have used in the absence of the entire opinions revealed by you regarding that question. It had become a real difficult concern in my position, nevertheless spending time with your specialised avenue you resolved the issue made me to jump over joy. I’m just grateful for this advice and even wish you comprehend what a great job that you’re carrying out instructing most people all through your webpage. I know that you have never got to know any of us. thor love and thunder download torrent
Jul 06, 2022 10:25:06 AM
https://www.bestkidsewingmachines.com/best-embroidery-machines-for-beginners/ I'm not against the agree with the things you suggested.
Jul 12, 2022 01:36:40 AM
Thanks for the nice blog. It was very useful for me. I'm happy I found this blog. Thank you for sharing with us,I too always learn something new from your post. 戒菸經驗分享
Jul 13, 2022 02:03:25 AM
Has aterrizado en la página de la derecha. España original Licencia de conducir en línea, España Licencia de conducir para la venta y otros documentos para varios países como: Estados Unidos, Australia, España, México, España, Reino Unido, España, Reino Unido. España Esta lista no está completa. Para obtener más información y realizar un pedido, visite nuestro equipo de correo electrónico.<a href=" https://www.auto-licenciadeconducir.com/comprar-espana-licencia-de-conducir-en-linea-licencia-de-conducir-en-venta-en-espanol/ ">licencia de conducir en venta en español</a> ,
Jul 13, 2022 09:01:03 PM
We are https://420clubmeds.com personnel for your health illness especially for chronic Pain, ADHD, you do not need a prescription before you can make your order with us as we handle order for everyone <a href="https://420clubmeds.com">Buy weed online in Scotland</a>
<a href="https://420clubmeds.com">Buy weed online in Scotland</a> ,
<a href="https://420clubmeds.com">buy Marijuana online in Scotland</a> ,
<a href="https://420clubmeds.com">Where do I order cannabis online in Scotland</a> ,
<a href="https://420clubmeds.com">order cannabis online in Scotland</a> ,
<a href="https://420clubmeds.com">Order weed online in Dundee, Scotland</a> ,
<a href="https://420clubmeds.com">Where to Buy Marijuana Online in Edinburgh, Scotland</a> ,
<a href="https://420clubmeds.com">Order Cannabis Online in Aberdeen, Scotland</a>
Jul 17, 2022 11:38:24 PM
Attractive, post. I just stumbled upon your weblog and wanted to say that I have liked browsing your blog posts. After all, I will surely subscribe to your feed, and I hope you will write again soon! Florida
Jul 19, 2022 06:34:59 PM
Hi there, I like what you guys do. Keep it up the good work. Please dont't forget to visit my blog. Thankyou! <a href="https://arab-army.com/">rtp slot</a>
Jul 28, 2022 02:58:39 AM
While using search engines is a great way to find the web sites that offer these links, they are not always effective. Even if you find a few web pages with links to them, chances are the sites are old or hidden.
Jul 28, 2022 03:16:47 AM
This option is obviously not foolproof, but it's better than having a ton of dark web links appearing on your browser. It's also much less expensive than getting hit with a spam charge from search engines.
Jul 28, 2022 03:29:28 AM
This is because the web has many restrictions when it comes to webmasters. Although you may be tempted by the prospect of making some money on the dark web, you have to consider some risks in order to ensure yourself safety.
Jul 28, 2022 03:45:02 AM
Linking is one of the best ways to create this traffic since the more links that you create, the better chance you have of your site being found. However, remember that there are many programs and software packages that are available on the market that will promise to make your money.
Jul 28, 2022 03:54:42 AM
Instead, you need to post links to your web page so that users will be directed to your website. You must also make sure that your ad copies are relevant and unique.
Jul 28, 2022 04:07:34 AM
There are tons of marketing methods out there online. In order to make money online, you need to be willing to implement all of them. Some are better than others, but I can tell you from experience that the most successful marketers take all of the marketing methods they can learn and incorporate them into their business plan.
Jul 28, 2022 04:14:55 AM
You can either learn it the hard way from a failed affiliate marketer, or you can get a coach that will help you build your marketing strategies. A coach can be invaluable to those of us who are struggling to make it work.
Jul 28, 2022 02:53:13 PM
We are 420clubmeds personnel for your health illness especially for chronic Pain, ADHD, you do not need a prescription before you can make your order with us as we handle order for everyone <a href="https://420clubmeds.com/">buy cannabis online in Scotland</a>,<a href="https://420clubmeds.com/">Buy weed online in Scotland</a>,<a href="https://420clubmeds.com/">buy Marijuana online in Scotland</a>
Jul 30, 2022 09:59:24 PM
It has always been my belief that good writing like this takes research and talent. It’s very apparent you have done your homework. Great job! Ver Anime Online
Jul 31, 2022 03:16:51 PM
Great job for publishing such a beneficial web site. Your web log isn’t only useful but it is additionally really creative too. There tend to be not many people who can certainly write not so simple posts that artistically. Continue the nice writing 犀利士網購
Aug 04, 2022 12:10:35 PM
Thanks for your post. I’ve been thinking about writing a very comparable post over the last couple of weeks, I’ll probably keep it short and sweet and link to this instead if thats cool. Thanks. novelas online
Aug 04, 2022 07:46:18 PM
Im no expert, but I believe you just made an excellent point. You certainly fully understand what youre speaking about, and I can truly get behind that.
d
Aug 06, 2022 01:22:32 PM
“this is very interesting. thanks for that. we need more sites like this. i commend you on your great content and excellent topic choices.” Flexiv Chinese $100M Series meituanliaotechcrunch
Aug 07, 2022 07:29:36 PM
I prefer to look on the brighter side of things which I’m sure you can appreciate. <a href="https://ggongnara.com/">꽁머니</a>
Aug 10, 2022 04:44:55 AM
I am curious to find out what blog system you’re utilizing? I’m having some minor security issues with my latest site and I’d like to find something more secure. Do you have any recommendations? WHOLESALE POUCHES australia
Aug 11, 2022 10:39:02 PM
Could potentially be at the same time a fairly fantastic post that marilyn and i clearly loved comprehending. Usually not regularly of which see the the chances to buy a device. kaufen
Aug 13, 2022 06:06:29 PM
My partner and i many thanks for wp style, where you down load it through? Many thanks beforehand! Sports Articles
Aug 13, 2022 07:34:16 PM
Thanks for sharing this useful info. Check it on:
Aug 13, 2022 08:12:33 PM
It's similarly a fantastic write-up i usually certainly appreciated analyzing. It isn't always day-to-day i usually create the chance to find out something. DNP Capstone Project Help
Aug 14, 2022 01:41:39 AM
It’s not that I want to duplicate your website, but I really like the layout. Could you tell me which theme are you using? Or was it custom made? <a href="https://www.karendoll.com/authorized-brand-axbdoll-c-31_76.html">axbdoll</a>
Aug 15, 2022 10:05:13 PM
The majority of us don’t know how to start. Making it basic, you might be capability to ask all people nearest thing to you personally is most likely the best method to look for these types of condos in simply the subject associated with time and place. <a href="https://www.infusionbusiness.com/merchant_services_agents__iso__reseller__sales_partner_programs__credit_card_processing">Selling Merchant Services</a>
Aug 15, 2022 10:50:32 PM
That could be at the same time the best send in that in reality preferred examining. It's actually not every single day that many of us support the chance to figure out the very first thing. Business Strategy Game Help
Aug 16, 2022 04:59:36 PM
Hi! Someone in my Facebook group shared this site with us so I came to take a look. I’m definitely enjoying the information. I’m bookmarking and will be tweeting this to my followers! Terrific blog and fantastic style and design. Capsim Help
Aug 18, 2022 03:46:44 AM
Good day, Could I export your image and utilize it on my own website? <a href="https://aussiekiwifakies.net">Victoria Fake Drivers Licence</a>
Aug 18, 2022 04:04:03 PM
Excellent commentary on that subject. We appreciate your knowledge that you really to leave out with us! <a href="https://lotterysambad.in/">lottery sambad kolkata</a>
Aug 22, 2022 10:15:16 PM
Your blog has the same post as another author but i like your better.*:~;’ <a href="https://fscfrench.ca/online-courses/members/nosecough51/activity/631296/">nitrous oxide buy online</a>
Aug 23, 2022 01:52:06 AM
They are very important if we need to prevent concealed damage <a href="https://patentediguida-europa.com/acquista-patente-trieste-senza-esame/">Acquista patente categoria C1 a Trieste senza esame</a>
<a href="https://patentediguida-europa.com/patente-online-brescia-senza-esame/">Patente online C1 a Brescia senza esame</a>
<a href="https://patentediguida-europa.com/acquista-parma-patente-senza-teoria/">Acquista Parma patente classe C1 senza teoria</a>
Aug 23, 2022 09:46:08 PM
The facts on your blog site is seriously informative and good, it served me to clear up my problem and responses are also handy. Men you can go by means of this blog site and it helps you a ton. <a href="https://txt.fyi/-/22179/2ad9d424/">umbrella base weight</a>
Aug 24, 2022 11:29:57 AM
Others were prostate cancer surgery patients <a href="https://patentediguida-europa.com/online-patente-originale-a-piacenza/">Online patente originale D a Piacenza</a>
<a href="https://patentediguida-europa.com/ottieni-patente-gratuita-a-novara/">Ottieni patente gratuita categoria D a Novara</a>
<a href="https://patentediguida-europa.com/comprare-ancona-patente-beneficio/">Comprare Ancona patente D beneficio</a>
Aug 24, 2022 05:51:27 PM
To see got with your web site on the other hand location treatment method clearly a very little amount of submits. Flexible technique for likely foreseeable future, I am book-marking at a stretch safeguarded options halt springs up in concert. <a href="https://cjulion.com">bestellen</a>
Aug 25, 2022 12:25:06 AM
This process will be creatively actually the best option. Every single one regarding infinitesimal shows are usually designed through several traditions expertise. I would recommend the application a lot. <a href="https://wabufabetdeal7098hk.page.tl/wabbacarat-review.htm">เว็บแทงบาคาร่าฝากถอนauto</a>
Aug 25, 2022 01:41:15 AM
Deference to author , some superb entropy. <a href="https://site-7583816-8077-9763.mystrikingly.com/blog/review-wab-slot">เว็บสล็อตปลอดภัยไม่โกง</a>
Aug 25, 2022 03:53:22 PM
I believe one of your advertisements triggered my browser to resize, you may well want to put that on your blacklist. <a href="https://site-6499716-1745-4861.mystrikingly.com/">เว็บคาสิโนบนมือถือ</a>
Aug 25, 2022 04:38:14 PM
we would usually buy our bedroom sets from the local retailer which also offers free delivery* <a href="https://slotbakkuyey.weebly.com/">เว็บสล็อตบนมือถือ</a>
Aug 25, 2022 05:29:39 PM
Things used to be like that, unfortunately different elements made sure they wouldnt stay that way. Congrats on the article <a href="https://moon5525.blogspot.com/2022/07/tangballmototbuyha.html">เว็บแทงบอลบนมือถือ</a>
Aug 25, 2022 07:12:57 PM
Spot on with this write-up, I really feel this web site wants far more thought. I’ll it’s quite likely be yet again to understand far more, thank you for which info. <a href="https://sites.google.com/view/bacaratmotobaksad">เว็บแทงบาคาร่าบนมือถือ</a>
Aug 26, 2022 04:24:06 AM
There is noticeably a lot of money to understand about this. I assume you made certain nice points in features also. <a href="https://coveantdata.com/owens-corning-roof-shingles/">3 tab roof shingles</a>
Aug 27, 2022 03:36:19 AM
You actually make it seem so easy with your presentation but I find this matter to be actually something which I think I would never understand. It seems too complicated and very broad for me. I am looking forward for your next post, I will try to get the hang of it! <a href="https://coveantdata.com/facts-about-metal-polishing-explained-in-brief/">Aluminum Polishing Services</a>
Aug 27, 2022 10:27:03 PM
In short you have acquired an improved possiblity to match breast augmentation aventura his or her associate due to the greater lots of daters. It is additionally less complicated to satisfy folks on the web thanks to on the internet date web-sites as well as boards. <a href="https://www.financialmodelonline.com/p/financialmodel">financial modeling blog</a>
Aug 28, 2022 01:25:57 AM
Hello Guru, what entice you to post an article. This article was extremely interesting, especially since I was searching for thoughts on this subject last Thursday. <a href="https://finalsanctum.com/my-adventures-with-farm-animals-and-their-antics-what-i-have-learned-along-the-way/">fenben labs</a>
Aug 28, 2022 04:14:51 PM
we will be buying more christmas ornaments these christmas because we like to decorate more~ <a href="https://impactvirtual.instructure.com/eportfolios/2141/Home/InventHelp__How_to_Get_Started_With_Inventor_Ideas">patent an idea</a>
Aug 30, 2022 09:06:00 PM
My brother recommended I might like this website. He was entirely right. This post truly made my day. You can not imagine simply how much time I had spent for this information! Thanks! voyance telephone
Sep 01, 2022 07:35:58 PM
Online screen recorder for Android & iOS is a free, high-quality app that provides stable and smooth screen recording. ScreenRecorderᵀᴹ delivers every feature that you need in most simple and elegant user experience design.
Sep 02, 2022 06:40:43 PM
This is really stimulating, You’re a truly capable blogger. I’ve signed up with your feed additionally expect reading your excellent write-ups. Moreover, We’ve shared your webpage with our social networking sites. <a href="https://wikibusinessnow.com/net-worth-of-mike-ditka/">Wiki Business Now</a>
Sep 02, 2022 08:52:09 PM
Excellent website. Plenty of useful info here. I’m sending it to several friends ans also sharing in delicious. And of course, thanks for your sweat! download twitter video
Sep 03, 2022 05:04:26 PM
screen capture for Android & iOS is a free, high-quality app that provides stable and smooth screen recording. ScreenRecorderáµá´¹ delivers every feature that you need in most simple and elegant user experience design.
Sep 03, 2022 09:11:01 PM
hi. I observe you are focused on creating backlinks and stuff. I’m selling scrapebox auto approve lists. Do you want to trade ? names
Sep 03, 2022 09:48:28 PM
Comfortabl y, the post is really the freshest on this deserving topic. I harmonise with your conclusions and also can thirstily look forward to your next updates. Simply just saying thanks definitely will not simply be adequate, for the extraordinary clarity in your writing. I will certainly directly grab your rss feed to stay informed of any kind of updates. Gratifying work and much success in your business dealings! <a href="https://www.fiverr.com/kinzababy/do-dofollow-blog-comments-seo-backlinks-on-high-pa-da-links">Gambling Slot backlinks</a>
Sep 05, 2022 02:35:24 PM
Hey There. I found your blog using msn. This is a very well written article. I will be sure to bookmark it and return to read more of your useful information. Thanks for the post. I will certainly return. Vip Lahore Escorts
Sep 06, 2022 10:02:57 PM
Your work is truly appreciated round the clock and the globe. It is incredibly a comprehensive and helpful blog. <a href="https://inforedar.com/kris-allen-net-worth/">Info Redar</a>
Sep 07, 2022 10:02:46 PM
What your saying is absolutely genuine. I know that everybody must say the same matter, but I just think that you set it in a way that everybody can understand. I also enjoy the images you set in right here. They fit so nicely with what youre attempting to say. Im certain youll get to so a lot of individuals with what youve received to say. <a href="http://hotmail-signin.live/">hotmail</a>
Sep 08, 2022 03:32:12 PM
I’m really thankful on the author of the post for producing this lovely and informative article live to put us. We actually appreciate ur effort. Maintain the great work. . . . visit this website
Sep 09, 2022 05:04:23 AM
Hey! Quick question that’s entirely off topic. Do you know how to make your site mobile friendly? My site looks weird when browsing from my apple iphone. I’m trying to find a template or plugin that might be able to correct this issue. If you have any suggestions, please share. With thanks!
Sep 09, 2022 09:06:37 PM
Just a question. Do you think you could add a little more in the way of content here? I think youve got some interesting points, but Im just not sold. If you really want to get the crowd behind you, youve got to entertain us, man. Maybe you could add a video or two to drag the message home. <a href="https://sites.google.com/view/merchant-services-iso-agent/home">payment processing agent</a>
Sep 11, 2022 08:35:49 PM
It’s nearly impossible to find knowledgeable men and women about this topic, however, you appear to be you know what you’re referring to! Thanks visit this site
Sep 12, 2022 07:36:28 PM
I appreciate your wp design, where would you down load it through? Vip call girls in lahore
Sep 12, 2022 10:12:45 PM
It’s nearly impossible to find knowledgeable men and women during this topic, however you sound like do you know what you’re discussing! Thanks <a href="https://digitalglobaltimes.com/branding-write-for-us/">Digital Global Times</a>
Sep 13, 2022 10:15:31 PM
information technology is increasing these days, most jobs are also related to information technology;; <a href="https://digitalglobaltimes.com/caroline-county-car-accident/">Digital Global Times</a>
Sep 17, 2022 05:17:45 PM
<a href="https://student-ways.com/">Immigration consultant in Pakistan</a> Student Ways provides its services to students free of cost, which makes it more accessible for masses. Our team of experienced & trained counselors works closely & diligently with students for selection of institute where they want to study,
Sep 17, 2022 09:46:33 PM
Great post right here. One thing I’d like to say is that often most professional areas consider the Bachelor Degree like thejust like the entry level standard for an online degree. Whilst Associate Certification are a great way to begin, completing your own Bachelors uncovers many opportunities to various employment opportunities, there are numerous online Bachelor Diploma Programs available coming from institutions like The University of Phoenix, Intercontinental University Online and Kaplan. Another concern is that many brick and mortar institutions give Online variations of their college diplomas but commonly for a greatly higher payment than the companies that specialize in online higher education degree plans. protective coatings
Sep 19, 2022 03:18:20 PM
There is no rule for how often you should use them, but you should listen to how native speakers use idioms. If you listen they do not use them as often as you think. <a href="https://cambridgeenglish.org.in/ielts.php"> Best IELTS Coaching in East Delhi</a>.If you overuse idioms you are going to sound very unnatural, you will make more mistakes and you could also lose coherence because you are focusing more on idioms than actually answering the question. Additionally, if you use lots of idioms the examiner will think you have simply learned lists of them rather than having good appropriate English speaking skills. Finally, it could also lead to your fluency suffering because you are thinking too much about idioms and this will cause you to hesitate and pause while you search for the latest idiom.
Sep 19, 2022 08:07:06 PM
I am typically in order to running a blog and that i actually appreciate your content. The actual article has actually peaks my personal interest. I am going to save your web site and gaze after checking for brand spanking new data. Zhewitra
Sep 20, 2022 03:16:12 PM
<a href="https://immigration-ways.com/"> Explore your way to immigration with Immigration Ways in Karachi, Pakistan. The official advisor of RCI Canada and Official Representatives of Government of Antigua & Barbuda.
Sep 20, 2022 03:19:11 PM
Thanks For sharing this Superb article.I use this Article to show my assignment in college.it is useful For me Great Work. Kickass Torrents
Sep 20, 2022 05:23:45 PM
<a href="https://www.gamesee.tv/play-shorts"> streamers </a> Create your ideal live gaming video and chat with other players without any compromises. Watch live matches, Stream Live or watch videos uploaded by the professionals with our cutting-edge technology for a better gaming experience.
Sep 20, 2022 05:34:34 PM
Esports tournaments Create your ideal live gaming video and chat with other players without any compromises. Watch live matches, Stream Live or watch videos uploaded by the professionals with our cutting-edge technology for a better gaming experience.
Sep 21, 2022 03:08:18 AM
“I had to refresh the page times to view this page for some reason, however, the information here was worth the wait.” <a href="https://studioapartmentsdubai.com/">studio apartments dubai</a>
Sep 21, 2022 06:48:11 PM
Thank you very much for this useful article. I like it. หวยออนไลน์
Sep 21, 2022 07:58:59 PM
I’ve been exploring for a little bit for any high quality articles or weblog posts on this kind of area . Exploring in Yahoo I ultimately stumbled upon this web site. Studying this info So i am satisfied to convey that I’ve an incredibly good uncanny feeling I discovered just what I needed. I so much no doubt will make sure to don’t put out of your mind this website and give it a look a relentless basis. 마사지
Sep 21, 2022 10:15:36 PM
Hiya! Fantastic blog! I happen to be a daily visitor to your site (somewhat more like addict ) of this website. Just wanted to say I appreciate your blogs and am looking forward for more to come! Info Redar
Sep 21, 2022 11:33:08 PM
I’m impressed, I must say. Actually rarely should i encounter a weblog that’s both educative and entertaining, and without a doubt, you may have hit the nail to the head. Your concept is outstanding; the catch is something that not enough people are speaking intelligently about. I am happy i always came across this around my seek out something relating to this. <a href="https://kinydrugs.com/product/buy-hydrocodone-online/">buy hydrocodone</a>
Sep 22, 2022 04:50:12 PM
Hey, I am so thrilled I found your blog, I am here now and could just like to say thank for a tremendous post and all round interesting website. Please do keep up the great work. I cannot be without visiting your blog again and again. cheapest smm panel
Sep 22, 2022 10:07:15 PM
A lot of thanks for your whole hard work on this web page. My mother enjoys setting aside time for internet research and it is easy to understand why. All of us know all regarding the powerful tactic you provide simple suggestions through the blog and improve contribution from some other people about this idea and our own simple princess is certainly studying so much. Take pleasure in the remaining portion of the new year. Your performing a pretty cool job. <a href="https://kbclotterywinner.co.in/">kbc winner 2022</a>
Sep 23, 2022 04:25:43 AM
How to become an Interior Designer: The first step is to decide what type of design you want to specialize in. Do you want to design residential spaces, or commercial ones? Maybe you’re interested in sustainable design, or historic preservation. Once you’ve decided on a focus, the next step is to get some experience under your belt. You can do this by interning with a design firm, or working as a assistant designer. This will give you a chance to learn the ropes and see if this is the right career for you. If you find that you love it, then the next step is to get a degree in interior design from an accredited school. After graduation, you’ll be ready to start your own firm or work for an established one. With hard work and dedication, you can build a successful career as an interior designer. <a href="https://homedesigninstitute.com/course/171/">free interior design courses</a>
Sep 23, 2022 08:20:55 PM
Nie and informative post, your every post worth atleast something. Updated Ideas
Sep 24, 2022 01:54:43 AM
I am happy to find this post Very useful for me, as it contains lot of information. I Always prefer to read The Quality and glad I found this thing in you post. Thanks live cam
Sep 24, 2022 04:28:00 PM
Thanks for this great post, i find it very interesting and very well thought out and put together. I look forward to reading your work in the future. زيادة متابعين انستقرام
Sep 26, 2022 03:50:53 PM
I love to suggest simply great moreover successful advice, that is why start to see the merchandise: 먹튀검증
Sep 26, 2022 10:12:07 PM
An fascinating discussion is worth comment. I believe that you can write more on this topic, it might not become a taboo subject but typically people are inadequate to communicate in on such topics. Yet another. Cheers https://heylink.me/login-hore138
Sep 26, 2022 11:07:31 PM
Best American Healthcare University online surgical technician training is far superior to other online Surgical Technician programs because it includes the training, exam review and national certification exams. Register with Confidence and attend a nationally accredited, but affordable program. In just 4 months, you can complete the surgical technician program from the comfort of your home without a loan on your neck. Enroll now a <a href="http://www.bestamericanhealthcareuni.com/course/surgical-technician/">hospital surgical tech programs,</a>
Sep 27, 2022 12:38:43 AM
my hard drive is getting full already because i always download free online movies on the internet“ <a href="https://artgargedubai.com/">car Repair Services dubai</a>
Sep 27, 2022 03:30:30 AM
this song make sme cry, because my ex boyfriend sent me this when we were fighting….i would have done suicide that night i listened to this <a href="https://m.blog.naver.com/andrewpaul9005/222883866208">https://m.blog.naver.com/andrewpaul9005/222883866208</a>
Sep 27, 2022 03:03:17 PM
You have remarked very interesting points! ps decent web site. <a href="https://ladyfordaddy.com/category/manhattan.html">https://ladyfordaddy.com/category/manhattan.html</a>
Sep 27, 2022 05:21:43 PM
Great wordpress blog here.. It’s hard to find quality writing like yours these days. I really appreciate people like you! take care https://heylink.me/daftar-168mega
Sep 27, 2022 09:55:48 PM
Thank you for some other magnificent article. The place else could anyone get that kind of info in such a perfect manner of writing? I have a presentation subsequent week, and I am at the look for such information. <a href="https://altmanlawgroup.net/">Los Angeles Securities Lawyer</a>
Sep 27, 2022 11:29:26 PM
Hello! I wish to provide a large thumbs up for the fantastic info you have here within this post. I will be coming back to your site for additional soon. <a href="https://altmanlawgroup.net/">Criminal Defense Attorney Los Angeles</a>
Sep 28, 2022 12:55:18 AM
I’m impressed, I have to admit. Actually rarely must i encounter a weblog that’s both educative and entertaining, and without a doubt, you’ve got hit the nail on the head. Your notion is outstanding; the pain is something which too little people are speaking intelligently about. I am happy i came across this in my search for something about it. <a href="https://www.unipluseducation.com/">物理補習</a>
Sep 28, 2022 01:54:32 AM
*There are certainly a lot of details like that to take into consideration. That is a great point to bring up. I offer the thoughts above as general inspiration but clearly there are questions like the one you bring up where the most important thing will be working in honest good faith. I don?t know if best practices have emerged around things like that, but I am sure that your job is clearly identified as a fair game. Both boys and girls feel the impact of just a moment’s pleasure, for the rest of their lives. Digital Global Times
Sep 28, 2022 03:57:56 AM
I cannot wait to dig deep and kickoff utilizing resources that I received from you. Your exuberance is refreshing.
Sep 28, 2022 06:07:36 PM
I think this is one of the so much vital information for me. And i am glad reading your article. But want to statement on few common things, The site style is great, the articles is in reality nice . Excellent activity, cheers. https://heylink.me/login-planetslot128
Sep 28, 2022 11:26:53 PM
produce,I thought overall often the “invisible” men and women probably would not discover i am, pointless, buyers anything like me, where ever all of the fireflies are just like the actual bluish event, plenty to pay off marvelous a sufficient quantity of. yuxuda korpe gormek
Sep 29, 2022 01:32:59 PM
This is just the information I am finding everywhere. Thanks for your blog, I just subscribe your blog. This is a nice blog.. Skyward FBISD
Sep 29, 2022 08:03:50 PM
You have beaten yourself this time, and I appreciate you and hopping for some more informative posts in future. Thank you for sharing great information to us. commenting sites
Sep 29, 2022 08:15:38 PM
I really like what you guys are up too. This sort of clever work and coverage! Keep up the very good works guys I’ve included you guys to my own blogroll. 마사지
Sep 29, 2022 10:14:45 PM
Kudos for posting such a useful blog. Your blog is not only informative but also very artistic too. There usually are extremely couple of individuals who can write not so easy articles that creatively. Keep up the good writing !! <a href="https://digitalglobaltimes.com/linode-write-for-us/">Digital Global Times</a>
Oct 01, 2022 02:35:43 PM
I simply wanted to thank you a lot more for your amazing website you have developed here. It can be full of useful tips for those who are actually interested in this specific subject, primarily this very post. Your all so sweet in addition to thoughtful of others and reading the blog posts is a great delight in my opinion. And thats a generous present! Dan and I usually have enjoyment making use of your recommendations in what we need to do in the near future. Our checklist is a distance long and tips will certainly be put to excellent use. زيادة متابعين انستقرام
Oct 01, 2022 03:22:35 PM
I was surfing the Internet for information and came across your blog. I am impressed by the information you have on this blog. It shows how well you understand this subject. vape shop near me
Oct 01, 2022 04:36:48 PM
For ice cream program, you would love your activities with long term ice cream flavors along with flavors of month sub method and significantly far more other system. You would get every month new taste of month for ice cream under flavor of month subprograms. Other subprograms are sherbets, rotators, sorbets, ices, small fats and yogurts gone nuts. สล็อตออนไลน์
Oct 01, 2022 08:28:14 PM
Thanks for some other great post. Where else may just anyone get that type of info in such an ideal means of writing? I’ve a presentation next week, and I’m at the search for such info. <a href="https://taigameslot.com/">สล็อตออนไลน์</a>
Oct 01, 2022 11:00:14 PM
You can definitely see your enthusiasm in the paintings you write. The world hopes for even more passionate writers such as you who are not afraid to say how they believe. Always follow your heart. <a href="https://www.fivalifitness.com/product-category/knee-sleeves/">neoprene knee sleeve</a>
Oct 02, 2022 02:07:08 PM
I would really like you to become a guest poster on my blog.”.~,” <a href="https://mypornadviser.com/atk-natural-and-hairy-review">atknaturalandhairy review</a>
Oct 02, 2022 03:44:19 PM
I gotta favorite this internet site it seems very helpful very helpful <a href="https://www.totoprobet.com/">사설토토</a>
Oct 02, 2022 03:44:53 PM
I gotta favorite this internet site it seems very helpful very helpful <a href="https://www.totoprobet.com/">사설토토</a>
Oct 02, 2022 09:47:55 PM
It’s appropriate time to make some plans for the future and it’s time to be happy. I have read this post and if I could I wish to suggest you few interesting things or advice. Maybe you can write next articles referring to this article. I wish to read more things about it! สล็อต
Oct 03, 2022 03:54:16 AM
This article gives the light in which we can observe the reality. This is very nice one and gives indepth information. Thanks for this nice article. Digital Global Times
Oct 04, 2022 06:09:13 PM
I do agree with all of the ideas you’ve presented in your post. They’re very convincing and will certainly work. Still, the posts are very short for starters. Could you please extend them a bit from next time? Thanks for the post. r34comix
Oct 04, 2022 10:17:58 PM
Absolutely composed subject material , Really enjoyed studying. <a href="https://wordsmith.social/h3vqgz106j">money lender singapore</a>
Oct 04, 2022 11:47:41 PM
very nice post, i surely really like this amazing site, persist with it <a href="https://www.mywisegranny.com/commercial-casinos-energy-policy-act-tax-opportunity/">겜블시티 가입 방법</a>
Oct 05, 2022 12:30:01 AM
very good post, i certainly really like this website, carry on it <a href="https://www.pre-news.com/usb-headset-microphone-right-at-your-fingertips/">bluetooth do not disturb light</a>
Oct 05, 2022 02:18:23 AM
well, i bought some digital pedometer on the local walmart and it is great for monitoring your performance when walking- <a href="https://pro4pc.org/itop-vpn-crack/">itop vpn crack</a>
Oct 06, 2022 07:34:27 PM
I went to this website, and I believe that you have a plenty of excellent information, I have saved your site to my bookmarks. زيادة متابعين انستقرام
Oct 06, 2022 10:16:18 PM
Oh my goodness! an amazing post dude. Appreciate it Even so We are experiencing issue with ur rss . Do not know why Unable to enroll in it. Is there everyone getting identical rss issue? Anyone who knows kindly respond. Thnkx <a href="https://totobetking.com/">Bedava Bonus al</a>
Oct 08, 2022 01:50:10 AM
I’d always want to be update on new blog posts on this web site , bookmarked ! . 美国代写
Oct 08, 2022 02:19:30 PM
The when I just read a blog, I’m hoping that this doesnt disappoint me approximately this one. Get real, Yes, it was my method to read, but When i thought youd have something interesting to state. All I hear is a number of whining about something that you could fix should you werent too busy trying to find attention. strippers for rent
Oct 08, 2022 02:28:49 PM
Exceptional entry! I found it very interesting. I'll check back later to see if more posts are added. strippers new york city
Oct 08, 2022 04:55:18 PM
There are actually a lot of particulars like that to take into consideration. That could be a nice level to deliver up. I supply the thoughts above as general inspiration but clearly there are questions just like the one you bring up the place a very powerful factor will likely be working in honest good faith. I don?t know if best practices have emerged round issues like that, however I am sure that your job is clearly identified as a fair game. Each girls and boys really feel the impact of just a moment’s pleasure, for the rest of their lives. <a href="https://www.bijindoll.com/">ラブドール</a>
Oct 09, 2022 02:34:32 AM
It’s an extremely amazing powerful resource that you’re offering and you just provide it away cost-free!! I that can compare with discovering websites ones understand the particular in providing you with fantastic learning resource for zero cost. We truly dearly loved examining this blog. Have fun here! <a href="https://livenewsof.com/cbs-live-streaming/">https://livenewsof.com/cbs-live-stream/</a>
Oct 09, 2022 03:35:43 PM
Thank you, I’ve just been searching for info about this topic for a while and yours is the greatest I’ve discovered so far. But, are you sure about the source? <a href="https://sites.google.com/account-email.com/hotmail/login">hotmail.com</a>
Oct 10, 2022 03:23:25 AM
Very nice post. I just stumbled upon your blog and wished to say that I’ve really enjoyed surfing around your blog posts. After all I’ll be subscribing to your rss feed and I hope you write again very soon! pk88vn
Oct 10, 2022 07:23:46 PM
I learn some new stuff from it too, thanks for sharing your information. Schmuck
Oct 10, 2022 10:05:05 PM
Amazing! This blog looks exactly like my old one! It’s on a totally different topic but it has pretty much the same page layout and design. Great choice of colors! <a href="https://replica100.com/">https://replica100.com/</a>
Oct 11, 2022 03:42:00 AM
I’m a new pertaining to almost all of the articles or blog posts, My spouse and i definitely savored, I'd personally genuinely like additional files with regards to this specific, since it can be okay., Congratulations for the purpose of putting up. <a href="https://cjulion.com">kaufen</a>
Oct 11, 2022 04:00:56 PM
Wonderful blog! Do you have any tips and hints for aspiring writers? Because I’m going to start my website soon, but I’m a little lost on everything. Many thanks! seo
Oct 11, 2022 04:36:19 PM
Hey, you used to write fantastic, but the last several posts have been kinda boring… I miss your tremendous writings. Past few posts are just a little out of track! come on! male enhancement
Oct 11, 2022 05:38:15 PM
Wow, amazing blog format! How lengthy have you ever been running a blog for? you made blogging glance easy. The total glance of your web site is excellent, as smartly the content! Hetzer Accounts For Sale
Oct 11, 2022 09:16:05 PM
Thanks for taking the time to talk about this, I feel fervently about this and I take pleasure in learning about this topic. Please, as you gain information, please update this blog with more information. I have found it very useful. There have to be charging stations everywhere. <a href="https://mushroomchocolatess.com/">https://mushroomchocolatess.com/</a>
Oct 12, 2022 08:45:48 PM
I believe, life’s more for example a battlefield, both equally armies skin oneself, the light gives you Pifu all the bravery is just not just enough, there has to be tip, there are actually certain schemes together with projects prior to they’re able to do anything whatsoever, we will need to think carefully about, not necessarily blind to this problem, systems work efficiently possibly not set off unneeded waste together with letdown. situs judi bola terpercaya
Oct 12, 2022 10:02:40 PM
I became honored to receive a call from a friend as he observed the important tips shared in your site. Looking at your blog post is a real fantastic experience. Many thanks for taking into account readers much like me, and I wish you the best of achievements as a professional in this field. cuba resorts asia77
Oct 13, 2022 08:54:05 PM
Simply wanna input that you have a very nice website , I enjoy the pattern it really stands out. زيادة متابعين انستقرام
Oct 13, 2022 11:27:55 PM
I was just looking for this information for a while. After six hours of continuous Googleing, finally I got it in your web site. I wonder what is the lack of Google strategy that do not rank this kind of informative websites in top of the list. Normally the top websites are full of garbage. how to become a credit card merchant processor
Oct 14, 2022 09:02:51 PM
Howdy. Very nice web site!! Guy .. Excellent .. Wonderful .. I’ll bookmark your web site and take the feeds additionally…I am satisfied to locate numerous helpful information here within the article. Thank you for sharing. login pos4d
Oct 15, 2022 04:55:20 PM
That is a beneficial viewpoint, however isn’t make every sence whatsoever dealing with which mather. Any method thanks in addition to i had make an effort to share your current post straight into delicius but it surely is apparently an issue using your websites is it possible to you should recheck this. many thanks again. strippers for rent
Oct 16, 2022 12:25:18 AM
One important thing is that when you’re searching for a student loan you may find that you’ll want a cosigner. There are many scenarios where this is correct because you could find that you do not have a past credit score so the loan provider will require that you’ve got someone cosign the credit for you. Good post. best time to go to bahamas
Oct 16, 2022 06:36:08 PM
Wow, incredible weblog format! How long have you been running a blog for? you make running a blog look easy. The whole look of your web site is magnificent, well the content material! Best Margarita Machine
Oct 16, 2022 09:40:21 PM
You made some decent points there. I seemed on the internet for the problem and found most people will associate with with your website. broshop.pw
Oct 17, 2022 10:19:18 AM
if you're looking for a different kind of game, I introduce to our site. This is a little bit different
<A HREF="https://711casino.net " TARGET='_blank'>카지노사이트</A>
Oct 17, 2022 10:20:11 AM
That isn’t going to create much of a sense of community or generate tons of commentary.
https://main7.net/obama/
Oct 17, 2022 06:23:14 PM
Hello there, just became alert to your blog through Google, and found that it is really informative. I’m going to watch out for brussels. I’ll be grateful if you continue this in future. A lot of people will be benefited from your writing. Cheers! 4D Hari Ini
Oct 17, 2022 10:39:42 PM
This could be the appropriate blog for hopes to check out this topic. You already know a great deal its almost tricky to argue with you (not that When i would want…HaHa). You definitely put a fresh spin using a topic thats been discussing for many years. Wonderful stuff, just fantastic! slot gacor online
Oct 17, 2022 10:40:02 PM
Oct 18, 2022 03:54:10 AM
I’ve been surfing on-line greater than three hours as of late, but I by no means found any interesting article like yours. It¡¦s pretty worth enough for me. In my opinion, if all website owners and bloggers made good content as you probably did, the internet can be much more useful than ever before. <a href="https://digitalglobaltimes.com/ryan-humiston-wife/">Digital Global Times</a>
Oct 18, 2022 08:53:32 PM
Spot on with this article, I really think this web site needs much more consideration. I’ll probably be again to read more, thanks for that information. login pos4d
Oct 19, 2022 11:24:46 PM
PEAKERR provides Best SMM Panels Services & Cheap SMM Panel Services In The World. For Youtube Views Panel, TikTok Services Panel, Facebook Services Panel, Instagram Services Panel, And Many More, We Are Providing All Services At Cheap Rates For Reseller SMM Panels. Resell Our SMM Services And Make Money Online. We Have Many Free SMM Panel Services & Give You Some Test Funds For Check Our Services Quality. We Always Try to Provide High-Quality Services At a Cheap Rate. Check: <a href="https://peakerr.com/">best smm panel</a>
Oct 20, 2022 04:52:04 PM
Anyone who has ever gone through the process of designing and building a home knows that it can be both incredibly rewarding and frustrating. There are so many little details to consider, and it can be difficult to know where to start. This is where home design courses can come in handy. By taking a course or two, you can learn about the basics of home design, from choosing the right floor plan to picking the perfect paint color. You'll also get an opportunity to see how professionals approach the design process, which can give you some valuable insights. And if you're still not sure what you want, attending a home design course can help you narrow down your options and find the perfect style for your new home. <a href="https://homedesigninstitute.com/">Interior design institute</a>
Oct 20, 2022 08:50:32 PM
I am happy to find this post very useful for me, as it contains lot of information. I always prefer to read the quality content and this thing I found in you post. Thanks for sharing. strippers for rent
Oct 21, 2022 03:54:08 PM
In today's job market, it's more important than ever to have the right skills and credentials. Companies are looking for employees who are not only qualified, but also up-to-date on the latest industry trends. That's where online professional training comes in. Online courses offer a flexible and convenient way to learn new skills or brush up on existing ones. What's more, they can be tailored to your specific needs, whether you're looking to change careers or advance in your current field. With so many advantages, it's no wonder that online professional training is becoming increasingly popular. Whether you're just starting out or well into your career, online courses can help you stay ahead of the curve and find success. <a href="https://startupo.fr/">Startupo.fr</a>
Oct 22, 2022 05:52:18 PM
Outstanding read, I just passed this onto a colleague who was doing a little investigation on that. And he actually bought me lunch because I discovered it for him smile So let me rephrase that: Thanks for lunch! Ellevet Calm and Comfort Chews
Oct 22, 2022 11:19:26 PM
Oh my! an incredible article man. Thanks a lot Unfortunately I am experiencing issues with ur rss . Don’t know why I am struggling to subscribe it. Perhaps there is somebody getting identical rss issues? Anyone who can help kindly respond. Appreciate it poker99
Oct 24, 2022 11:21:52 PM
I have really learned some new things through your blog post. Also a thing to I have noticed is that normally, FSBO sellers can reject an individual. Remember, they’d prefer to never use your expert services. But if you maintain a steady, professional romance, offering help and remaining in contact for about four to five weeks, you will usually have the capacity to win a meeting. From there, a listing follows. Thanks Buy Digitalocean Accounts
Oct 25, 2022 10:42:47 PM
E-students are those who engage in online learning, also known as distance learning. This type of learning takes place via the internet, using a computer or mobile device. E-students can be enrolled in an online course, program or school, or they can choose to take individual online courses for credit or for personal enrichment. Many e-students are drawn to this type of learning because it offers Flexibility and Convenience. They can study at their own pace and on their own schedule, and they can often choose from a wide range of courses and programs. In addition, e-students have access to a wealth of online resources, including tutors, mentors and fellow students. While e-learning can be an effective way to learn, it is important to be aware of the potential challenges. These include distractions, procrastination and difficulty staying motivated. For e-students who are willing to put in the effort, however, online learning can be a rewarding experience. <a href="https://softwareacademy.bg/index.php?q=estudent">e student</a>
Oct 26, 2022 01:15:09 AM
Today, taking into consideration the fast life style that everyone is having, credit cards get this amazing demand throughout the economy. Persons coming from every area are using the credit card and people who are not using the credit card have made up their minds to apply for even one. Thanks for sharing your ideas on credit cards. графичен дизайн
Oct 27, 2022 08:40:16 PM
I would like to thank you for the efforts you have put in writing this site. I am hoping the same high-grade web site post from you in the upcoming also. In fact your creative writing skills has inspired me to get my own website now. Actually the blogging is spreading its wings rapidly. Your write up is a good example of it. Digital Global Times
Oct 28, 2022 12:38:35 AM
Une bonne gestion est essentielle au succès de toute entreprise. Pourtant, il est surprenant de constater que de nombreuses entreprises n'offrent pas une formation adéquate à leurs gestionnaires. En conséquence <a href="https://startupo.fr/course/201/">formation gestion d'entreprise</a>
Oct 29, 2022 03:06:48 PM
I just tracked down this blog and have high expectations for it to proceed. Keep up the extraordinary work, finding great ones hard. I have added to my top picks. Much thanks to You. influencer marketing in singapore
Oct 29, 2022 08:58:25 PM
Most beneficial gentleman speeches and toasts are made to enliven supply accolade up to the wedding couple. Newbie audio system the attention of loud crowds should always think about typically the great norm off presentation, which is their private. best man speaches strippers for hire
Oct 29, 2022 11:11:06 PM
I truly wanted to develop a quick note to thank you for these stunning advice you are placing at this site. My extensive internet look up has at the end of the day been paid with extremely good strategies to go over with my classmates and friends. I ‘d mention that many of us website visitors are unquestionably lucky to dwell in a superb place with very many special professionals with very beneficial hints. I feel extremely fortunate to have come across the website page and look forward to tons of more excellent times reading here. Thanks again for everything. een paspoort kopen
Oct 30, 2022 01:05:13 AM
Quickly this page probably will without doubt maybe always be recognized regarding a lot of websites folks, due to the thoughtful articles or blog posts or perhaps ideas. <a href="https://cjulion.com/">Bestseller</a>
Oct 31, 2022 12:55:20 AM
You completed some nice points there. I did a search on the topic and found mainly people will have the same opinion with your blog. <a href="https://noxtools.com">group buy seo tools</a>
Nov 06, 2022 08:27:47 PM
This blog is truly perfect. The data here will definitely be of an assistance to me. Much appreciated!. instagram panel
Nov 08, 2022 06:57:56 PM
I'm regarded to get a call from a companion as he recognized the significant hints shared on your site. Perusing your blog entry is a truly phenomenal encounter. Much obliged for thinking about perusers at all like me, and I hope everything turns out great for you of accomplishments similar to an expert space. seo optimization company
Nov 08, 2022 11:25:28 PM
I would also love to add that when you do not currently have an insurance policy or maybe you do not take part in any group insurance, you might well make use of seeking the aid of a health insurance broker. Self-employed or people who have medical conditions generally seek the help of any health insurance broker. Thanks for your blog post. slot deposit pulsa
Nov 09, 2022 03:36:35 PM
I’ve been exploring for a bit for any high-quality articles or weblog posts in this kind of house . Exploring in Yahoo I eventually stumbled upon this web site. Studying this information So i’m satisfied to show that I have an incredibly just right uncanny feeling I found out exactly what I needed. I most for sure will make certain to do not disregard this website and provides it a look a relentless basis. pitbull puppies for sale
Nov 09, 2022 03:36:59 PM
This is extremely instructive substance and composed well for a change. It's ideal to see that certain individuals actually comprehend how to compose a quality post.! jidion merch
Nov 09, 2022 06:25:33 PM
A lot of dissertation webpages on line as you may get hold of secured in a dark listed during the webpage. seo help
Nov 12, 2022 02:41:50 PM
I'm unequipped for perusing articles online frequently, however I'm cheerful I did today. It is very elegantly composed, and your focuses are all around communicated. I demand you heartily, kindly, absolutely never quit composition. Freelance Writing Medium Blog
Nov 12, 2022 05:53:15 PM
thank for sharing this with all of us. Of course, what a great site and informative posts, I will bookmark this site. keep doing your great job and always gain my support. cheers for sharing this beautiful story situs judi bola
Nov 13, 2022 01:54:06 PM
<b><a href="https://hotlivetv.net/" rel="Nofollow">hotlive</a></b> is a fun and interactive way to communicate with other people from around the world. Hotlive is being used more and more in Vietnam. On HotLive, you can discover and discuss a wide range of interests. Other apps haven't been as successful as HotLive because it offers more entertaining features, including live broadcasts of beautiful girls and games that thousands of other users enjoy. You may also watch movies while you play. For more information, please visit our website.
Nov 13, 2022 01:54:56 PM
Hotlivetv is a social networking site that allows people from all over the world to connect. It also offers live-streaming capabilities. Additionally, users can play games and watch videos through the app. Unlike other applications, HotLiveTV's features are attractive because you can watch live streams of beautiful girls or play games with thousands of other people. You can watch movies and play betting games at the same time by visiting our website.
Nov 14, 2022 09:13:18 PM
One can undertake all sorts of advised excursions with assorted limousine functions. Various offer great courses and many can take clients for just about any ride your bike over the investment banking area, or even for a vacation to new york. ??????? <a href="https://write-me-an-essay.com/">write me an essay</a>
Nov 15, 2022 03:26:06 PM
MMlive is a website that allows users to stream live videos, chat with others online, make video calls, or watch videos. Users can participate in discussions about contemporary lifestyle trends, form connections with other users who share similar interests, or play betting games to earn money. Download our app for free from our website.
Nov 15, 2022 06:01:34 PM
There has been a lot of interest in ChichLive from people .We want to bring people from around the world together and let them share information, enjoy performances by models who are live streaming, and learn about their talents. ChichLive allows you to watch live-streaming shows, chat with other members watching the show, and view streaming videos. You can broadcast your own show and learn more about the program here.
Nov 16, 2022 09:04:06 PM
It’s my belief mesothelioma can be the most lethal cancer. It contains unusual characteristics. The more I look at it the greater I am certain it does not respond like a true solid tissues cancer. In the event mesothelioma is often a rogue virus-like infection, therefore there is the chance for developing a vaccine along with offering vaccination for asbestos open people who are really at high risk associated with developing future asbestos associated malignancies. Thanks for sharing your ideas about this important health issue. resep masakan
Nov 16, 2022 09:41:19 PM
everyone would love to be debt free and have some financial freedom then become rich; <a href="https://www.morecashforscrap.com/locations/vancouver/">scrap car removal vancouver</a>
Nov 16, 2022 10:26:42 PM
hey there and thank you for your info – I’ve certainly picked up something new from right here. I did however expertise several technical points using this web site, since I experienced to reload the site many times previous to I could get it to load correctly. I had been wondering if your web hosting is OK? Not that I’m complaining, but sluggish loading instances times will sometimes affect your placement in google and can damage your high-quality score if advertising and marketing with Adwords. Anyway I am adding this RSS to my email and could look out for a lot more of your respective fascinating content. Make sure you update this again very soon.. sonovive review
Nov 16, 2022 11:19:17 PM
An impressive share, I simply with all this onto a colleague who had previously been performing a small analysis within this. And hubby actually bought me breakfast since I found it for him.. smile. So let me reword that: Thnx for the treat! But yeah Thnkx for spending the time to debate this, I’m strongly about it and adore reading more on this topic. If it is possible, as you become expertise, does one mind updating your blog site with increased details? It is actually highly helpful for me. Huge thumb up because of this short article! ฉีดปลวกลำพูนบ้านเดี่ยวราคา
Nov 17, 2022 12:04:55 AM
Hmm is anyone else encountering problems with the pictures on this blog loading? I’m trying to figure out if its a problem on my end or if it’s the blog. Any suggestions would be greatly appreciated. Business News
Nov 17, 2022 01:10:23 AM
I know this isn’t exactly on subject, however i have a website utilizing the identical program as nicely and i get troubles with my comments displaying. is there a setting i am missing? it’s doable you might help me out? thanx.
Nov 17, 2022 01:11:43 AM
Your blog is one of a kind, i love the way you organize the topics.:,”-* tarot gratis los arcanos
Nov 17, 2022 12:04:29 PM
Of course, your article is good enough, but I thought it would be much better to see professional photos and videos together. There are articles and photos on these topics on my homepage, so please visit and share your opinions.
Nov 17, 2022 02:40:04 PM
Wagering has long been a popular form of entertainment, and online betting has only increased its popularity. Betting has become a popular mode of entertainment since it began online. Online casinos have become more popular than land-based ones because online wagering has become popular. People can gamble without leaving their home or office thanks to online casinos. Yolo68 is one such site. You may play betting games on our website.
Nov 17, 2022 08:35:17 PM
It’s nice to definitely arrive a web site in which the blogger is intelligent. Thanks for creating your web site. Scrap Car Removal Surrey
Nov 17, 2022 08:50:58 PM
Wow! This could be one particular of the most helpful blogs We have ever arrive across on this subject. Basically Magnificent. I am also a specialist in this topic therefore I can understand your effort. pinterest
Nov 17, 2022 10:52:10 PM
Today, taking into consideration the fast life style that everyone is having, credit cards get this amazing demand throughout the economy. Persons coming from every area are using the credit card and people who are not using the credit card have made up their minds to apply for even one. Thanks for sharing your ideas on credit cards. group buy seo tools
Nov 18, 2022 07:52:07 PM
Youre so cool! I dont suppose Ive read anything in this way just before. So nice to get somebody with a few original thoughts on this subject. realy appreciation for beginning this up. this web site is something that is needed on the net, a person with some originality. helpful problem for bringing a new challenge towards web! <a href="https://www.gotscrapcar.com/">Scrap Car Removal Vancouver</a>
Nov 19, 2022 05:49:22 PM
Some really choice blog posts on this internet site , saved to favorites . Moving Company Burnaby
Nov 19, 2022 07:55:18 PM
you have got a great weblog here! do you need to make some invite posts in my weblog? ombre hair color
Nov 20, 2022 04:31:26 AM
I think, that you are not right. I can prove it. Write to me in PM, we will discuss. percent error calculator
Nov 20, 2022 05:10:54 PM
It’s my belief mesothelioma can be the most lethal cancer. It contains unusual characteristics. The more I look at it the greater I am certain it does not respond like a true solid tissues cancer. In the event mesothelioma is often a rogue virus-like infection, therefore there is the chance for developing a vaccine along with offering vaccination for asbestos open people who are really at high risk associated with developing future asbestos associated malignancies. Thanks for sharing your ideas about this important health issue. alpilean side effects
Nov 20, 2022 06:53:32 PM
I love what you guys are up too. This sort of clever work and reporting! Keep up the amazing works guys I’ve added you guys to our blogroll. neglesalong i oslo
Nov 20, 2022 08:24:47 PM
Hello, Neat post. There’s a problem with your website in internet explorer, might check this… IE still is the marketplace chief and a large part of folks will miss your wonderful writing due to this problem. andaman and nicobar package
Nov 21, 2022 12:16:33 PM
Thanks for a marvelous posting! I truly enjoyed reading it, you may be a great author. I will be sure to bookmark your blog and will eventually come back down the road. I want to encourage you to continue your great writing, have a nice weekend
<a href="https://www.india4fun.com/delhi-hotel/">Delhi Escort Service</a>
<a href="https://www.india4fun.com/delhi-hotel/">Delhi Model Girls</a>
Nov 21, 2022 12:18:35 PM
Thanks for a marvelous posting! I truly enjoyed reading it, you may be a great author. I will be sure to bookmark your blog and will eventually come back down the road. I want to encourage you to continue your great writing, have a nice weekend
Nov 21, 2022 12:21:24 PM
nice post
Nov 21, 2022 04:55:08 PM
If more people that write articles really concerned themselves with writing great content like you, more readers would be interested in their writings. Thank you for caring about your content. more information
Nov 21, 2022 05:59:05 PM
People from all corners of the world have shown a lot of interest in qqlive, a social networking platform. qqlive's live-streaming function allows people from all corners of the world to communicate and enjoy live performances by female models. You may watch live shows, chat with other users, or watch girls live-stream with qqlive. If you'd like, you may even broadcast your own show! Please visit our official website for more information about this site.
Nov 21, 2022 06:59:54 PM
Thanks for a marvelous posting! I truly enjoyed reading it, you may be a great author. I will be sure to bookmark your blog and will eventually come back down the road. I want to encourage you to continue your great writing, have a nice weekend
Nov 21, 2022 08:32:49 PM
Howdy, i scan your blog sometimes and that i own the same one and i was just wondering if you get a lot of spam comments? If so how do you forestall it, any plugin or anything you’ll be able to advise? i buy abundant lately its driving me mad so any assistance is very much appreciated. Scrap Car Removal Surrey
Nov 22, 2022 09:00:30 PM
I adore this theme. How hard is it to mess around with? Would you be able to write me an email? I would love to get this theme and use it on some of my sites. Thank you in advance! UK Fake Driving License
Nov 22, 2022 09:33:15 PM
Well done! I appreciate your contribution to this matter. It has been insightful.click here centimeters to mm converter
Nov 23, 2022 06:25:20 PM
Thanks for this web site post and discussing your own results together with us. Very well performed! I think a lot of people find it difficult to understand paying attention to several controversial things associated with this topic, but your own results talk for themselves. I think a number of additional takeaways are the importance of following each of the suggestions you presented in this article and being prepared to be ultra distinct about which one could really work for you greatest. Nice job. pet capuchin monkey
Nov 24, 2022 01:39:30 AM
This problem will only come to be more exacerbated as more people start out ‘cocooning’ within their houses. If you prefer to know more about social multi-level marketing, you’ll want to make investments some time and hard earned cash in excellent knowledge that may make your website potential customers explode. dell business laptops india
Nov 24, 2022 04:15:39 AM
Spot on with this write-up, I truly suppose this web site wants way more consideration. I’ll most likely be once more to learn way more, thanks for that info. Group buy tools
Nov 24, 2022 09:01:54 PM
Hello! I would like to provide a enormous thumbs up for your fantastic information you’ve got here about this post. I will be coming back to your website to get more detailed soon. twill stoff
Nov 24, 2022 10:24:16 PM
Today, taking into consideration the fast life style that everyone is having, credit cards get this amazing demand throughout the economy. Persons coming from every area are using the credit card and people who are not using the credit card have made up their minds to apply for even one. Thanks for sharing your ideas on credit cards. hotmail
Nov 25, 2022 12:08:30 AM
Greetings! This is my first visit to your blog! We are a team of volunteers and starting a new project in a community in the same niche. Your blog provided us beneficial information to work on. You have done a marvellous job! skandagiri trek booking
Nov 25, 2022 05:55:12 PM
Thanks for every other excellent post. The place else may just anyone get that kind of info in such an ideal manner of writing? I’ve a presentation subsequent week, and I am at the look for such information. godteri
Nov 25, 2022 08:05:23 PM
I’d always want to be update on new blog posts on this web site , bookmarked ! . Delhi local sightseeing package
Nov 25, 2022 09:25:47 PM
Thank you, I’ve just been searching for info about this subject for a long time and yours is the best I have discovered till now. But, what in regards to the conclusion? Are you positive about the source? Residential interior designers in Hyderabad
Nov 25, 2022 11:43:18 PM
After study some of the blog posts in your site now, and i genuinely such as your technique for blogging. I bookmarked it to my bookmark site list and are checking back soon. Pls look into my web site likewise and make me aware what you consider. 200Watt LED High Bay Light Manufacturer in India
Nov 26, 2022 04:33:43 PM
This is a very good standpoint, but is not produce virtually any sence in any way discussing of which mather. Every method gives thanks and also i had try to reveal your own article straight into delicius but it surely seems to be problems using your information sites is it possible to please recheck this. with thanks yet again. Indian recipes
Nov 26, 2022 06:08:56 PM
Definitely, Apple’s instance retail store is by way of distance. It’s a really variety of all kinds with programs versus a fairly sorrowful choice a handful for the purpose of Zune. Microsof company is applications, specially in the realm of exercises, still I am not sure It’s safe to require to wagered with the success detail aspect is important for your needs. Ipod could be a even better determination if so. ielts chandigarh
Nov 26, 2022 09:23:02 PM
I loved as much as you’ll receive carried out right here. The sketch is attractive, your authored material stylish. nonetheless, you command get bought an impatience over that you wish be delivering the following. unwell unquestionably come more formerly again since exactly the same nearly a lot often inside case you shield this increase. five star resorts in manali
Nov 26, 2022 10:19:24 PM
getting backlinks should be the first priority of any webmaster if he wants to rank well on search engines,. California Lemon Law
Nov 27, 2022 12:24:14 AM
hmmm, mobile marketing is quite interesting, maybe there would be some more money making oppurtunities in it“ Business Litigation Lawyer Los Angeles
Nov 27, 2022 05:18:04 PM
This will be the correct weblog for anyone who hopes to be familiar with this topic. You already know so much its practically hard to argue on hand (not too I personally would want…HaHa). You definitely put a brand new spin for a topic thats been revealed for some time. Fantastic stuff, just great! Deutschen Führerschein Kaufen
Nov 28, 2022 04:02:03 PM
Individuals are often shedding desire or even squandering the occasion by means of getting a best condo they will have because they lack knowledge or ideas on where to locate these types of qualities immediately. get more info
Nov 28, 2022 09:50:34 PM
You can certainly see your enthusiasm within the work you write. The arena hopes for more passionate writers such as you who are not afraid to mention how they believe. Always go after your heart. corner tv stand
Nov 29, 2022 06:47:26 PM
You actually make it seem so easy with your presentation but I find this topic to be really something that I think I would never understand. It seems too complicated and extremely broad for me. I am looking forward for your next post, I will try to get the hang of it! fiverr seo
Nov 29, 2022 06:55:03 PM
Hi, your blog is full of comments and it is very active” affordable seo services for small business
Nov 29, 2022 08:08:27 PM
I’m not sure exactly why but this web site is loading extremely slow for me. Is anyone else having this problem or is it a issue on my end? I’ll check back later on and see if the problem still exists. affordable seo for small business
Nov 29, 2022 08:26:12 PM
Hi, Could I grab that snapshot and usage it on my own web log? 1st in seo
Nov 30, 2022 01:23:05 AM
Some times its a pain in the ass to read what blog owners wrote but this site is rattling user friendly ! . Toko Kemasan Plastik Denpasar Online
Nov 30, 2022 06:29:10 PM
You there, this is great post here. Gratitude for setting aside some margin to post such important data. Quality substance generally gets the guests coming. PGSLOT
Nov 30, 2022 06:49:45 PM
This blog is so good to me. I will continue to come here over and over. Visit my connection also.. PG
Dec 01, 2022 06:37:11 PM
As such, it seems to me I need to collect all the software and document the process while I still can, and put it all in one place, both for myself, and for anyone else who wants to keep using this old. film izle
Dec 03, 2022 04:22:20 AM
Actually I read it yesterday but I had some thoughts about it and today I wanted to read it again because it is very well written.
Dec 03, 2022 03:46:19 PM
You could definitely see your enthusiasm within the work you write. The sector hopes for more passionate writers such as you who aren’t afraid to mention how they believe. All the time go after your heart. film izle
Dec 03, 2022 04:56:03 PM
Get best deals on Kashmir tour packages. Browse through the best Kashmir holiday packages and customize your itinerary to plan your trip to Kashmir with us. Visit Us: Kashmir Packages
Dec 05, 2022 06:22:55 AM
Its a great pleasure reading your post.Its full of information I am looking for and I love to post a comment that<a href="https://www.buyrealpassportonline.net/buy-fake-birth-certificate-real-birth-certificate-for-sale/">Buy Fake Birth Certificate Real Birth Certificate for sale</a>
<a href="https://www.auto-licenciadeconducir.com/obtenga-una-licencia-de-conducir-espanola-registrada-en-linea/">Obtenga una licencia de conducir española registrada en línea</a>
<a href="https://www.buyrealpassportonline.net/buy-singapore-passport-online-where-to-buy-singapore-passport/">Buy Singapore passport online where to buy singapore passport</a>
Dec 06, 2022 03:46:50 PM
Your article has value for both myself and other people. Thank you for sharing your knowledge! Black Satta faridabad ghaziabad contact us now to get fix satta number because black satta king company has brought this offer only for limited lucky customers 100% leak and confirm single jodi me hoga dhamaka toh jadi karen aur lakhs kamaye daily Doing business with us and that too with live proof.
Dec 07, 2022 04:45:16 PM
Wow, great stuff. I have been considering this for a few years. I’m glad to seemingly find someone that comes to the same conclusions as me. At least it seems that’s the case. I’ll keep visiting your site to stay informed. anal cumshot
Dec 08, 2022 10:22:07 PM
Thanks for sharing, it is a great inspirational thread to will motivate many people to work on new things. rtp slot online kotalotto
Dec 09, 2022 07:15:47 PM
I think this is one of the most vital information for me. And i am glad reading your article. But wanna remark on few general things, The website style is perfect, the articles is really great : D. Good job, cheers GODPLAY88 SITUS SLOT ONLINE TERBAIK SLOT88 DEPOSIT PULSA TERPERCAYA
Dec 12, 2022 04:35:51 AM
Really interesting and special post. I like things such as making more homework, developing writing skills, and also related things. These kinds of secrets help in being a qualified person on this topic. This page is very helpful to myself because people like you committed time to learning. Regularity is the key. But it is not too easy, as has been designed to be. I am not an expert like you and plenty of times I feel really giving it up. 스포츠토토
Dec 13, 2022 02:00:33 AM
Este tipo de mensaje siempre es inspirador y prefiero leer contenido de calidad, así que feliz de encontrar un buen lugar para muchos aquí en la publicación, la redacción es simplemente excelente, gracias por la publicación.<a href="https://www.auto-licenciadeconducir.com/comprar-licencia-de-conducir-en-spanish-riviera/">Comprar licencia de conducir categoría B en spanish riviera</a>
<a href="https://www.auto-licenciadeconducir.com/comprar-licencia-de-conducir-en-majadahonda/">Comprar licencia de conducir categoría A1 en Majadahonda</a>
<a href="https://www.auto-licenciadeconducir.com/comprar-licencia-de-conducir-en-pozuelo-de-alarcon/">Comprar licencia de conducir categoría A1 en Pozuelo de Alarcón</a>
Dec 16, 2022 03:40:01 PM
cek link <a href="https://careerdirect-ge.org/">situs slot pulsa</a> mudah menang
Dec 16, 2022 03:53:10 PM
cek <a href="https://annuaire-commercial.com/">link slot gacor hari ini</a> situs slot online dengan info rtp tertinggi yang mudah memberi peluang kemenangan besar. tunggu apalagi Daftar segeraaa!
Dec 17, 2022 06:38:37 PM
I have been browsing on-line more than three hours these days, yet I by no means found any interesting article like yours. It¡¦s beautiful worth sufficient for me. In my opinion, if all website owners and bloggers made excellent content as you probably did, the net will likely be much more helpful than ever before. 슬롯사이트
Dec 22, 2022 04:07:29 PM
Hey what a brilliant post I have come across and believe me I have been searching out for this similar kind of post for past a week and hardly came across this. Thank you very much and will look for more postings from you. Reverse Image Search
Dec 28, 2022 11:55:54 AM
I really love the way information is presented in your post. I have added you in my social bookmark.<a href="https://www.auto-licenciadeconducir.com/comprar-licencia-de-conducir-en-argentina/">Comprar licencia de conducir categoría A2 En Argentina</a>
<a href="https://www.auto-licenciadeconducir.com/comprar-licencia-de-conducir-en-mexico/">Comprar licencia de conducir categoría C En México</a>
<a href="https://www.auto-licenciadeconducir.com/comprar-licencia-de-conduccion-en-cuba/">Comprar licencia de conducción categoría D en Cuba</a>
Dec 28, 2022 02:38:11 PM
I wanted to thank you for this great read!! I definitely enjoying every little bit of it I have you bookmarked to check out new stuff you post.카지노사이트 바카라사이트
Dec 30, 2022 05:06:27 PM
<a href="https://indobetslo<a href="https://indobetslots.xn--6frz82g/">indobet</a>ts.xn--6frz82g/">indobet</a>
Dec 30, 2022 05:46:27 PM
<a href="https://omega-schools.com/">sabung ayam</a>
Dec 30, 2022 06:48:57 PM
PayPal is one of the current largest online payment transfer platforms in the world. It has been serving more than 200 countries in 25 currencies now. It allows you to make purchases online via Amazon, eBay, and many other retailers. You can also make simple money transfers between other PayPal accounts or supported bank accounts around the world. Their escrow system, it’s one of the safest and most reliable ways to transfer money or make payments online.
Jan 04, 2023 03:45:21 PM
I recently found many useful information in your website especially this blog page. Among the lots of comments on your articles. Thanks for sharing. safe deposit box manufacturers .
Jan 04, 2023 07:51:48 PM
thank you for this useful informations amd i found something is interesting here.
Jan 06, 2023 01:27:11 PM
If you want to buy a Facebook Ads account, we can help. We have a wide variety of accounts available, and our team can set you up with the perfect one for your needs. Contact us today to learn more or to get started on your purchase.
Jan 11, 2023 01:48:38 AM
Nice post. I learn something on different blogs everyday. It can all the time be stimulating to read content from other writers and observe somewhat something from their blog
Jan 11, 2023 05:08:18 AM
I do love the way you have presented this specific situation plus it does supply us some fodder for consideration.<a href="https://www.auto-licenciadeconducir.com/comprar-licencia-de-conducir-en-villarreal/">Comprar licencia de conducir categoria A2 en Villarreal</a>
Jan 11, 2023 08:32:58 PM
Thanks for sharing such a worthy information
<a href="https://www.3ding.in/">3D Printing Services in chennai</a>
<a href="https://www.3ding.in/">3D printers in Chennai</a>
Jan 11, 2023 08:34:37 PM
Thanks for sharing such a worthy information
3D Printing in Chennai | 3D Printer in Chennai
Jan 12, 2023 01:26:34 AM
These blog update will be helpful for all. Keep going like this....
Jan 12, 2023 11:01:39 PM
extreme solutions Limited est un revendeur à valeur ajoutée et un fournisseur de services informatiques, et une gamme complète de solutions logistiques informatiques et de chaîne d'approvisionnement.
Jan 13, 2023 01:09:20 AM
Ready to take your business payments transactions up a notch? Look no further than buy verified stripe account from this site - 100% secure and hassle-free! Get that peace of mind you deserve so you can focus on growing your venture.
Jan 14, 2023 03:36:58 PM
Im glad to have found this post as its such an interesting one! I am always on the lookout for quality posts and articles so i suppose im lucky to have found this! I hope you will be adding more in the future...<a href="https://www.auto-licenciadeconducir.com/comprar-licencia-de-conducir-en-la-linea-de-la-concepcion/">Comprar licencia de conducir categoría A en La Linea de la Concepción</a>
<a href="https://www.auto-licenciadeconducir.com/comprar-licencia-de-conducir-en-palma-de-mallorca/">Comprar licencia de conducir categoría B96 en Palma de Mallorca</a>
Jan 16, 2023 05:35:12 PM
Fabulous post, you have denoted out some fantastic points, I likewise think this s a very wonderful website. I will visit again for more quality contents and also, recommend this site to all. Thanks. แจกเครดิตฟรี
Jan 17, 2023 07:06:16 AM
Each time when i evolved into with your web page while using unique focus simply a little little bit submits. Eye-catching technique for years to come, We will be book-marking presently include products obtain arises suitable in place. Pathaan
Jan 17, 2023 05:09:08 PM
I am incapable of reading articles online very often, but I’m happy I did today. It is very well written, and your points are well-expressed. I request you warmly, please, don’t ever stop writing. <a href="https://game168club.com/">เกมสล็อตเว็บตรง</a>
Jan 17, 2023 05:13:10 PM
Excellent post. I was always checking this blog, and I’m impressed! Extremely useful info specially the last part, I care for such information a lot. I was exploring this particular info for a long time. Thanks to this blog my exploration has ended. เกมสล็อตเว็บตรง
Jan 18, 2023 03:40:00 PM
I just added this blog to my rss reader, excellent stuff.<a href="https://www.auto-licenciadeconducir.com/comprar-licencia-de-conducir-en-ourense/">Comprar licencia de conducir categoria A en Ourense</a>
<a href="https://www.auto-licenciadeconducir.com/comprar-licencia-de-conducir-en-badajoz/">Comprar licencia de conducir categoria C1 en Badajoz</a>
Jan 18, 2023 06:37:05 PM
Im no expert, but I believe you just made an excellent point. You certainly fully understand what youre speaking about, and I can truly get behind that. Things to do in Bradford
Jan 18, 2023 09:33:10 PM
There are many important things in life, and it's easy to get caught up in all of them. One of the key principles of design is hierarchy, and keeping it simple will help you communicate your thoughts more clearly. For example, <a herf="https://pvalo.com/buy-facebook-pva-accounts/">buy facebook accounts with paypal</a> instead of focusing on the last thing on your list, focus on the top item. That way, you'll have a clear idea of what to focus on. This principle is also essential to managing your time and ensuring that you don't spend too much time on unnecessary tasks.
Jan 25, 2023 05:15:02 PM
Reliable Doors A Wide Range Of Unique And Customized Plywood And Decorative Doors seller, Such As 3-D Membrane Doors, 2-D Membrane Doors, Lamination Doors and Jali doors etc. Readymade doors in Lucknow In Addition To Readily Available Commodity Products. Our Customer Oriented & Demand Centric Approach Has Helped Us Become One Of The Largest Seller Of Plywood and readymade doors. visit here- https://reliabledoors.in
Jan 29, 2023 02:48:13 AM
An impressive share, I just now given this onto a colleague who was simply carrying out a small analysis during this. And that he the fact is bought me breakfast since I discovered it for him.. smile. So ok, i’ll reword that: Thnx for any treat! But yeah Thnkx for spending enough time go over this, Personally i think strongly about it and enjoy reading on this topic. If it is possible, as you become expertise, would you mind updating your website with a lot more details? It really is extremely of great help for me. Huge thumb up just for this text! Digital Global Times
Feb 08, 2023 05:38:36 PM
Students who struggle to pay attention in class or who are reluctant to ask their teachers pertinent questions could benefit from expert assignment help UAE to ensure they receive high grades on their assignments. A pupil won't be able to accomplish their job successfully if they don't have access to transparency on their subject matter. A student can submit their project on time by using Assignment Help in UAE, and by afterwards reading the simple language-written materials, they will have all the clarification they require to comprehend the challenging subject matter.
Feb 10, 2023 07:11:35 PM
But wanna admit that this is very helpful , Thanks for taking your time to write this. g2g เว็บตรง
Feb 11, 2023 03:41:12 AM
I have been meaning to read this and just never obtained a chance. It’s an issue that I’m really interested in, I just started reading and I’m glad I did. You’re a fantastic blogger, one of the best that I’ve seen. This weblog undoubtedly has some facts on topic that I just wasn’t aware of. Thanks for bringing this stuff to light. UFABET เว็บตรงดีที่สุด
Feb 12, 2023 09:33:55 PM
To <a href="https://vccshoppers.com/product/buy-hetzner-accounts/" rel="Nofollow">buy hetzner account</a>, you get access to a variety of flexible pricing plans to fit your budget and needs. Enjoy multiple packages designed to save you money and still get the best features.
Feb 25, 2023 02:59:59 AM
I hope to link to your website if my content needs more support.<a href="https://www.buyrealpassportonline.net/buy-real-passport-buy-passport-online-fake-passport-for-sale/">Buy real passport Buy passport Online fake passport for sale</a>
<a href="https://www.buyrealpassportonline.net/buy-real-passport-for-sale-buy-passport-online/">buy real passport for sale buy passport online</a>
<a href="https://www.buyrealpassportonline.net/buy-australian-passport-for-sale-buy-australia-passport-online/">Buy Australian passport for sale buy Australia passport online</a>
Feb 27, 2023 12:21:04 AM
I have a similar interest this is my page read everything carefully and let me know what you think custom,url,shortener .
Mar 01, 2023 12:25:54 AM
Woh Everyone loves you , bookmarked ! My partner and i take issue in your last point. กงล้อ888
Mar 08, 2023 09:30:21 PM
I went over this site and I believe you have a lot of superb information, saved to bookmarks (:. slot666
Mar 14, 2023 03:03:28 PM
You’ll notice several contrasting points from New york Weight reduction eating plan and every one one may be useful. The first point will probably be authentic relinquishing on this excessive. lose weight dark web
Mar 15, 2023 11:20:04 PM
The article looks magnificent, but it would be beneficial if you can share more about the suchlike subjects in the future. Keep posting. crowdfunding for real estate
Mar 18, 2023 03:56:12 PM
Thanks a lot for sharing us about this update. Hope you will not get tired on making posts as informative as this.
Mar 21, 2023 09:11:57 PM
Thank you for helping people get the information they need. Great stuff as usual. Keep up the great work!!! internet providers toronto
Mar 23, 2023 12:34:06 AM
This is very educational content and written well for a change. It's nice to see that some people still understand how to write a quality post! Roof Insulation Grants
Mar 26, 2023 12:40:10 AM
When a blind man bears the standard pity those who follow…. Where ignorance is bliss ‘tis folly to be wise…. passzív jövedelem
Apr 01, 2023 11:52:50 PM
Great blog. Thanks for sharing such a worthy information
<a href="https://ouncetocup.com/oz-to-liter/">Ounce to Liter</a>
<a href="https://ouncetocup.com/oz-to-liter/">oz to l conversion</a>
Apr 02, 2023 02:06:59 AM
Previously you have to have efficacious online income methods to get you started across experiencing details good for an individual’s web-based business organisation. e-wallet CNN Live Stream - Watch CNN Free
Apr 02, 2023 06:48:18 AM
For that reason times repeatedly pretty much everything, this life definitely is ended up saving a little bit more. The program in fact saves currently the And also carbon actually motivated in to planet during these development activities. dc free mommy blog giveaways family trip home gardening house power wash baby laundry detergent 먹튀검증업체
Apr 05, 2023 08:17:59 PM
You have noted very interesting points ! ps nice website . İzmir Escort
Apr 06, 2023 04:11:35 AM
Only a quickly hello and also to appreciate talking about your ideas with this page. best blood pressure machine
Apr 08, 2023 05:30:42 PM
I have been checking out a few of your stories and i must say nice stuff. I will surely bookmark your website frozen pork ribs
Apr 08, 2023 05:53:02 PM
Reliable Doors A Wide Range Of Unique And Customized Plywood And Decorative Doors seller, Such As 3-D Membrane Doors, 2-D Membrane Doors, Lamination Doors and Jali doors etc. <a href="https://reliabledoors.in">best quality doors for your home</a> In Addition To Readily Available Commodity Products. Our Customer Oriented & Demand Centric Approach Has Helped Us Become One Of The Largest Seller Of Plywood and readymade doors. visit here- https://reliabledoors.in
Apr 10, 2023 12:13:45 AM
You actually dealt with several engaging things in this article. I came across it by using Bing and I’ve got to admit that I am now subscribed to your website, it is very decent (: Digital Global Times
Apr 10, 2023 03:30:21 AM
Very efficiently written information. It will be beneficial to anybody who utilizes it, including me. Keep up the good work. For sure i will check out more posts. This site seems to get a good amount of visitors.
Apr 13, 2023 10:43:12 PM
I really love the way you discuss this kind of topic..”\"*. Wireless outdoor speakers
Apr 14, 2023 01:20:03 AM
Buy AWS Accounts
AWS is a cloud computing platform that enables individuals and businesses to run their applications and store their data in the cloud.
With an AWS account, users can access a wide range of services, including computing power, storage, database management, content delivery, and more. AWS offers a pay-as-you-go model, which means users only pay for the resources they use, without any upfront costs or long-term commitments.
Check Our More Products: Buy Google Cloud Accounts, Buy Digital Ocean Accounts, Buy Azure Accounts
An AWS account also provides users with tools and services to help manage their applications and infrastructure in the cloud, such as AWS Elastic Beanstalk, AWS Lambda, and AWS CloudFormation. AWS has a global infrastructure with data centers located in multiple regions around the world, enabling users to deploy their applications closer to their users and optimize their performance. So <a href="https://digitalacc.net/buy-amazon-aws-account">Buy AWS Accounts</a> right now.
Apr 16, 2023 01:04:12 AM
It’s difficult to acquire knowledgeable men and women within this topic, and you could be seen as you know what you are dealing with! Thanks AMICLEAR
Apr 19, 2023 03:10:56 AM
GOOD This is some great information. I expect additional facts like this was distributed across the web today.
Apr 27, 2023 11:10:19 PM
Your blog has chock-a-block of useful information. I liked your blog's content as well as its look. In my opinion, this is a perfect blog in all aspects.
Apr 29, 2023 02:37:37 PM
These kinds of Search marketing boxes normally realistic, healthy and balanced as a result receive just about every customer service necessary for some product. Link Building Services alpilean
May 04, 2023 10:09:50 PM
It is very interesting topic you’ve written here..The truth I’m not related to this, but I think is a good opportunity to learn more about, And as well talk about a different topic to which I used to talk with others
May 09, 2023 03:54:49 PM
You made some respectable points there. I looked on the internet for the issue and found most people will go along with with your website. AMYL GUARD
May 10, 2023 08:54:29 PM
Thanks, that was a really cool read!
May 10, 2023 09:45:31 PM
You made some respectable points there. I looked on the internet for the issue and found most people will go along with with your website.
May 10, 2023 09:49:37 PM
Nice Informative Blog having nice sharing..
May 10, 2023 10:00:18 PM
Yes i am totally agreed with this article and i just want say that this article is very nice and very informative article.I will make sure to be reading your blog more. You made a good point but I can't help but wonder, what about the other side? !!!!!!THANKS!!!!!!
May 10, 2023 10:11:53 PM
I really appreciate the kind of topics you post here. Thanks for sharing us a great information that is actually helpful. Good day!
May 11, 2023 08:53:20 PM
Aw, it was quite a good post. In notion I have to place in writing similar to this additionally - taking time and actual effort to generate a really good article… but what can I say… I procrastinate alot and also by no indicates appear to go completed. IKARIA JUICE
May 11, 2023 09:37:52 PM
I am continually amazed by the amount of information available on this subject. What you presented was well researched and well worded in order to get your stand on this across to all your readers.
May 12, 2023 09:33:21 PM
In conclusion, the duration of the Manali package tour varies depending on the package and the traveler's preferences. budget Manali tour packages usually have a duration of 3-4 days, while Manali package tour from delhi usually has a duration of 5-6 days. Shimla tour package from delhi for couples usually has a duration of 3-4 days, while Shimla package for couples usually has a duration of 2-3 days. The duration of the package can be customized depending on the traveler's preferences.
May 14, 2023 02:55:39 PM
Modest Gucci Purses Is typically blogengine obviously superior to wp oddly enough? Ought to be which is ending up being popluar today. RTP grabwin88
May 15, 2023 06:18:46 AM
Wow, What a Excellent post. I really found this to much informatics. It is what i was searching for.I would like to suggest you that please keep sharing such type of info.Thanks Fashion blogging tips
May 15, 2023 05:19:42 PM
Excellent article. Very interesting to read. I really love to read such a nice article. Thanks! keep rocking. Release
May 18, 2023 10:06:44 PM
Superbly written article, if only all bloggers offered the same content as you, the internet would be a far better place..
May 19, 2023 06:40:13 PM
This is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value of providing a quality resource for free.
May 19, 2023 07:57:58 PM
I just found this blog and have high hopes for it to continue. Keep up the great work, its hard to find good ones. I have added to my favorites. Thank You.
May 19, 2023 08:23:34 PM
Great post, you have pointed out some fantastic points , I likewise think this s a very wonderful website.
May 19, 2023 08:28:13 PM
I am always looking for some free stuffs over the internet. there are also some companies which gives free samples.
May 23, 2023 03:56:29 PM
<a href="https://situsjudiblog2.wordpress.com/">https://situsjudiblog2.wordpress.com/</a>
<a href="https://situs-judi-terpercaya.aioblogs.com/72666537/link-alternatif-situs-judi-terpercaya">https://situs-judi-terpercaya.aioblogs.com/72666537/link-alternatif-situs-judi-terpercaya</a>
<a href="https://situs-judi-terpercaya.xzblogs.com/60555579/slot-online-di-situs-judi-terpercaya">https://situs-judi-terpercaya.xzblogs.com/60555579/slot-online-di-situs-judi-terpercaya</a>
<a href="https://situsjuditerpercaya.ka-blogs.com/72307708/daftar-situs-judi-terpercaya-untuk-pengalaman-terbaik">https://situsjuditerpercaya.ka-blogs.com/72307708/daftar-situs-judi-terpercaya-untuk-pengalaman-terbaik</a>
May 24, 2023 12:38:49 AM
An fascinating discussion is value comment. I think that it is best to write extra on this matter, it won’t be a taboo topic however generally people are not enough to talk on such topics. To the next. Cheers
May 24, 2023 02:24:19 PM
I have seen a lot of useful points on your web-site about pc’s. However, I’ve got the view that lap tops are still more or less not powerful more than enough to be a option if you typically do tasks that require a lot of power, including video enhancing. But for website surfing, microsoft word processing, and majority of other prevalent computer functions they are perfectly, provided you do not mind the small screen size. Appreciate sharing your ideas. LIFT DETOX BLACK
May 24, 2023 11:26:21 PM
Hi there! Nice post! Please tell us when I will see a follow up!
May 25, 2023 03:28:39 AM
nice post, keep up with this interesting work. It really is good to know that this topic is being covered also on this web site so cheers for taking time to discuss this!
May 25, 2023 06:17:14 PM
You know your projects stand out of the herd. There is something special about them. It seems to me all of them are really brilliant!
May 26, 2023 12:21:10 AM
Thanks for a wonderful share. Your article has proved your hard work and experience you have got in this field. Brilliant .i love it reading.
May 26, 2023 12:38:37 AM
Love to read it,Waiting For More new Update and I Already Read your Recent Post its Great Thanks.
May 26, 2023 12:47:23 AM
I found your this post while searching for some related information on blog search...Its a good post..keep posting and update the information.
May 26, 2023 12:56:31 AM
That is really nice to hear. thank you for the update and good luck.
May 26, 2023 01:04:25 AM
Wow i can say that this is another great article as expected of this blog.Bookmarked this site..
May 26, 2023 02:04:02 AM
I wanted to thank you for this great read!! I definitely enjoying every little bit of it I have you bookmarked to check out new stuff you post.
May 26, 2023 02:17:58 AM
Great survey, I'm sure you're getting a great response.
May 26, 2023 10:35:19 PM
wow this is great site for the article i love the reading this site article. lovely
May 26, 2023 11:22:27 PM
Regards for this post, I am a big big fan of this site would like to go on updated. THC Vape Carts For Sale in PA
May 27, 2023 07:39:04 PM
I appreciate your work , thanks for all the informative blog posts. hawaiian star wars shirt
May 28, 2023 11:49:56 PM
Thanks for sharing the post.. parents are worlds best person in each lives of individual..they need or must succeed to sustain needs of the family.
May 30, 2023 11:32:45 PM
*I am often to blogging and i really appreciate your content. The article has really peaks my interest. I am going to bookmark your site and keep checking for new information. ALL DAY SLIMMING TEA REVIEWS
May 31, 2023 01:55:56 AM
I am definitely enjoying your website. You definitely have some great insight and great stories.
May 31, 2023 04:08:03 PM
As I website possessor I think the articles here is very wonderful, regards for your efforts. TUPI TEA
May 31, 2023 11:20:04 PM
as soon as I found this internet site I went on reddit to share some of the love with them. PROSTADINE REVIEWS
Jun 01, 2023 01:20:56 PM
Good I’ve applied the valuable points from this page and I can definitely tell that it gives a lot of assistance with my present jobs. I would be very pleased to keep getting back in this web page. Thank you.
Jun 01, 2023 07:41:47 PM
Thanks for sharing this information. I really like your blog post very much. You have really shared a informative and interesting blog post with people..
Jun 01, 2023 08:46:45 PM
Well done. I i never thought I would personally accept as true with this opinion, but I???m commencing to view things at a different view. I must research more about this simply because it seems fascinating. Another thing I don???t understand though is the way things are all related together. CORTEXI
Jun 01, 2023 10:26:38 PM
It’s rare knowledgeable folks with this topic, but the truth is sound like what happens you are talking about! Thanks LIVPURE
Jun 02, 2023 07:55:40 PM
Free games online… [...]When I initially commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get four emails with the same comment. Is there any way you can remove me from that service? Thanks![...]… PRODENTIM
Jun 03, 2023 03:46:19 PM
Aw, it was a very good post. In idea I would like to devote writing such as this furthermore,?¡ìC spending time and specific work to produce a great article?- nonetheless so what can I say?- I waste time alot and never at all seem to obtain one thing completed. AMYL GUARD
Jun 05, 2023 11:48:02 PM
I adore your wordpress web template, wherever would you download it from? VIAKETO GUMMIES
Jun 06, 2023 03:57:09 PM
Totally confined topic, feel a debt of gratitude for particular data . แทงหวย
Jun 06, 2023 08:50:45 PM
Nice post. I was checking continuously this blog and I am impressed! Very helpful information specially the last part I care for such information a lot. I was looking for this certain information for a very long time. Thank you and best of luck. LIV PURE
Jun 07, 2023 06:24:42 PM
It’s difficult to get knowledgeable individuals within this topic, however, you be understood as you know what you are referring to! Thanks Ikaria Lean Belly Juice
Jun 07, 2023 08:01:14 PM
Good day very nice site!! Man .. Beautiful .. Superb .. I’ll bookmark your website and take the feeds additionally…I’m satisfied to seek out a lot of useful info here in the post, we’d like develop more strategies on this regard, thank you for sharing. ALPILEAN REVIEWS
Jun 08, 2023 06:08:18 PM
I truly like your interpretation of the issue. I currently have a reasonable thought on what's genuinely going on with this.. open water course in Hurghada
Jun 10, 2023 04:34:14 PM
Good write-up, I¡¦m normal visitor of one¡¦s blog, maintain up the nice operate, and It is going to be a regular visitor for a long time. ikaria lean belly juice reviews
Jun 11, 2023 03:53:55 PM
even mendes is a bit old now but she is still smokin hot and i wanna marry her~ ALL DAY SLIMMING TEA
Jun 11, 2023 11:44:22 PM
You’ll notice several contrasting points from New york Weight reduction eating plan and every one one may be useful. The first point will probably be authentic relinquishing on this excessive. lose weight PRODENTIM
Jun 13, 2023 07:37:09 PM
I have been checking out a few of your stories and i can state pretty good stuff. I will definitely bookmark your blog
Jun 14, 2023 04:03:23 PM
This is great welcome article for me. I ma happy to read your stuff.
Jun 14, 2023 07:54:30 PM
Take a peek at the following tips what follows discover ideal way to follow such a mainly because you structure your small business this afternoon. earn money Contact us Contact us
Jun 15, 2023 02:34:13 AM
livpure https://youtu.be/9S_4HNUVTfI Good Regards for this terrific post, I am glad I discovered this site on yahoo.
Jun 17, 2023 03:13:17 PM
Much thanks to you for the update, exceptionally decent site.. Best Place Buy Diablo 4 Gold
Jun 19, 2023 07:20:43 PM
This is highly informatics, crisp and clear. I think that everything has been described in systematic manner so that reader could get maximum information and learn many things.
Jun 20, 2023 12:47:42 AM
Why didnt I think about this? I hear exactly what youre saying and Im so happy that I came across your blog. You really know what youre talking about, and you made me feel like I should learn more about this. Thanks for this; Im officially a huge fan of your blog IKARIA LEAN BELLY JUICE REVIEW
Jun 21, 2023 12:02:55 AM
Wow this hit it to the spot we will bookmark on Bebo and also Hub pages thanks ГородÑкую комиÑÑию по землепользованию Ñменил МоÑинвеÑтконтроль | ПрофеÑÑиональные новоÑти | ООО “Белго+” – Двери производÑтва БелоруÑи. Продажа, уÑтановка love it And also my prayers to the people at atomic plant we hope you are OK along with safer too !!! Kudos Financial Advisers AMICLEAR REVIEWS
Jun 26, 2023 08:00:59 PM
What others have stated and in some uncommon cases, suicide might occur. CORTEXI
Jul 01, 2023 04:50:58 PM
Buy Amazon AWS accounts for your business or website? Then, you have come to the right place. We can provide you fully verified EC2 enabled Amazon AWS accounts at a very reasonable price. If you are eager to know more, you can take a look at the details.
Details of Our Amazon AWS Accounts
We offer 100% genuine accounts.
Our account is completely verified.
It is active and ready to use.
It is based in the USA.
The account has no transactional records.
It is compatible with AWS coupons.
We have used a verified billing address.
Our account comes with AWS EC2 enabled.
We have used a valid Card to verify the account.
You can create unlimited VPS with our account.
You can use this account in any country.
Our account allows instances limited up to 10.
We have added recovery information to ensure maximum security.
Real and dedicated IP address was used to create the account.
We offer 48 hours replacement guarantee.
Things You Will Receive
The delivery will be sent to you via email.
You will be given full authority over the account.
The login credentials of the Amazon AWS account will be provided to you.
The recovery information will be included in the delivery as well.
Lastly, you will receive our earnest customer support
What we deliver
Accounts Details
Login Information
Full Supports 24/7
Jul 03, 2023 04:33:13 AM
one of the best system I know, thank you very much . ALPILEAN REVIEWS
Jul 04, 2023 12:29:44 PM
You did your best!
https://gamerphilippines.blogspot.com/
Jul 04, 2023 12:35:25 PM
You discovered something new! gamer
Jul 04, 2023 01:56:47 PM
I'm unequipped for perusing articles online regularly, however I'm blissful I did today. It is very elegantly composed, and your focuses are all around communicated. I demand you heartily, kindly, never quit composition. 먹튀조회
Jul 05, 2023 07:04:44 PM
Many thanks for this extraordinary post. 먹튀폴리스
Jul 08, 2023 02:23:31 PM
I never know the utilization of adobe shadow until I saw this post. much thanks to you for this! this is exceptionally useful. 먹튀스팟
Jul 10, 2023 07:37:23 PM
howdy, your websites are really good. I appreciate your work.
Jul 13, 2023 11:36:34 PM
Hey, before you go ahead and buy that Azure Account, let's talk about some key tips you gotta keep in mind. First things first, make sure the website you're buying from is legit and reliable. Then, double-check that the account is the real deal and can work on your device. And hey, don't forget to take a peek at the website's terms of service and the account itself to make sure you can get your money back if needed and access all those awesome featur
Jul 16, 2023 03:25:20 PM
Pleasant post. I was checking continually this blog and I'm dazzled! Very valuable data extraordinarily the last part I care for such data a ton. I was looking for this specific data for quite a while. Much thanks to you and best of luck. <a href="http://deepdreamdivingclub.com/">sea trips in Hurghada</a>
Jul 16, 2023 03:26:24 PM
Pleasant post. I was checking continually this blog and I'm dazzled! Very valuable data extraordinarily the last part I care for such data a ton. I was looking for this specific data for quite a while. Much thanks to you and best of luck.
Jul 18, 2023 05:10:53 PM
May you have a greater and a peaceful night. Good night brother, see you tomorrow.
Jul 24, 2023 12:50:49 AM
<a href="https://robinbecksnest.com/">Slot Joker81</a>
<a href="https://robinbecksnest.com/">Slot Gacor</a>
<a href="https://robinbecksnest.com/">Situs Joker81</a>
<a href="https://robinbecksnest.com/">Provider Slot Terbaik</a>
<a href="https://robinbecksnest.com/">Slot Online</a>
<a href="https://robinbecksnest.com/">Bonus Slot</a>
<a href="https://robinbecksnest.com/">Slot online gacor</a>
<a href="https://robinbecksnest.com/">Online gacor terbaik</a>
Aug 01, 2023 03:27:04 PM
I feel that gratitude for the valuabe data and bits of knowledge you have so given here.
Aug 04, 2023 09:38:11 AM
https://www.yeezyadidas.de/ Yeezy
https://www.yeezys.co/ Yeezys
https://www.jordan-1.org/ Jordan 1
https://www.air-jordan1.com/ Air Jordan 1
https://www.nikejordan1.com/ Nike Jordan 1
https://www.jordan-1s.com/ Jordan 1S
https://www.jordan1.uk.com/ Jordan 1
https://www.jordans-shoes.com/ Jordan Shoes
https://www.jordan-shoes.us.com/ Jordan Shoes
https://www.nikeuk.uk.com/ Nike UK
https://www.yeezy-450.com/ Yeezy 450
https://www.jordanretro4.com/ Jordan Retro 4
https://www.nikeoutletstoreonlineshopping.us/ Nike Outlet Store Online Shopping
https://www.yeezy.uk.com/ YEEZY
https://www.adidasyeezyofficialwebsite.com/ Adidas Yeezy Official Website
https://www.yeezy350.uk.com/ Yeezy 350
https://www.air-jordan4.com/ Air Jordan 4
https://www.yeezyfoam-runner.com/ Yeezy Foam Runner
https://www.yeezyslides.us.com/ Yeezy Slides
https://www.ray-ban-glasses.us.com/ Ray Ban Glasses
https://www.adidasuk.uk.com/ Adidas UK
https://www.nflshopofficialonlinestore.com/ NFL Shop Official Online Store
https://www.yeezys-slides.us.com/ Yeezy Slides
https://www.yeezyadidass.us.com/ Adidas Yeezy
https://www.350yeezy.us.com/ Yeezy 350
https://www.yeezyy.us.com/ Yeezy
https://www.yeezy350s.us.com/ Yeezy 350
https://www.shoesyeezys.us.com/ Yeezy Shoes
https://www.yeezys.uk.com/ Yeezys
https://www.off-white.us.org// Off White
https://raybansales.us/ Ray Ban
https://www.adidasyeezy.uk.com/ Adidas Yeezy
https://www.yzyshoes.us.com/ Yeezy Shoes
https://www.yeezy-shoes.us.com/ Yeezy Shoes
https://www.yeezy-700.us.com/ Yeezy 700
https://www.yeezyadidas.de/ Adidas Yeezy
https://www.yeezys.co/ Yeezy
https://www.jordan-1.org/ Nike Jordan 1
https://www.air-jordan1.com/ Jordan 1
https://www.nikejordan1.com/ Jordan 1
https://www.jordan-1s.com/ Jordan 1
https://www.jordan1.uk.com/ Jordan UK
https://www.jordans-shoes.com/ Jordans Shoes
https://www.jordan-shoes.us.com/ Jordan
https://www.nikeuk.uk.com/ Nike
https://www.yeezy-450.com/ Yeezy
https://www.jordanretro4.com/ Jordan 4
https://www.nikeoutletstoreonlineshopping.us/ Nike Outlet
https://www.yeezy.uk.com/ YEEZY UK
https://www.adidasyeezyofficialwebsite.com/ Adidas Yeezy
https://www.yeezy350.uk.com/ Yeezy uk
https://www.air-jordan4.com/ Jordan 4
https://www.yeezy-supply.com/ Yeezys Supply
https://www.yeezyfoam-runner.com/ Yeezy
https://www.yeezyslides.us.com/ YEEZY
https://www.ray-ban-glasses.us.com/ Ray Bans Sunglasses
https://www.adidasuk.uk.com/ Adidas
https://www.nflshopofficialonlinestore.com/ NFL Shop
https://www.yeezys-slides.us.com/ Yeezys
https://www.yeezyadidass.us.com/ Adidas Yeezys
https://www.350yeezy.us.com/ Yeezy 350 V2
https://www.yeezyy.us.com/ Yeezys
https://www.yeezy350s.us.com/ Yeezy Boost 350
https://www.shoesyeezys.us.com/ Yeezys Shoes
https://www.yeezys.uk.com/ Yeezy
https://raybansales.us/ Ray Bans
https://www.adidasyeezy.uk.com/ Yeezy
https://www.yzyshoes.us.com/ Yeezys
https://www.yeezy-slides.org/ Adidas Yeezy Slides
https://www.yeezy-shoes.us.com/ Yeezy
https://www.yeezy-700.us.com/ Yeezy
https://cheapyeezysonline.com/ Cheap Yeezys
https://yeezysupplystore.com/ Yeezy Supply
https://www.yeezyshoesonline.com/ Yeezy Shoes
https://www.yeezys-supply.us.com/ Yeezy Supply
https://www.yeezys-supply.us.com/ Yeezys
https://www.yeezy-s.com/ Yeezy Shoes
https://www.yeezy-s.us/ Yeezy
https://yeezysale.us/ Yeezy
https://www.pandorajewelries.us.com/ Pandora Jewelry
Tags:yeezy shoes, Yeezy, Adidas Yeezy
Aug 13, 2023 02:44:36 AM
If more people that write articles really concerned themselves with writing great content like you, more readers would be interested in their writings. Thank you for caring about your content.
Aug 19, 2023 02:49:56 PM
A ton of exposition site pages on line as you might get hold of gotten in a dull recorded during the page. <a href="https://mukti-police.net/">토토사이트</a>
Aug 22, 2023 12:06:06 AM
I rattling pleased to find this internet site on bing, just what I was searching for also saved to my bookmarks. share files by link
Aug 24, 2023 12:26:55 AM
Therefore dissertation web-sites as a result of online to set-up safe and sound ostensibly taped in the website. เว็บพนัน เว็บตรง
Aug 25, 2023 02:43:07 AM
Thank you for sharing excellent information. Your web site is so cool. I am impressed by the info that you’ve on this web site. It reveals how nicely you perceive this subject. Bookmarked this web page, will come back for more articles. เว็บคืนยอดเสียทุกวัน
Aug 26, 2023 01:26:28 AM
I’m glad to become a visitor in this pure site, regards for this rare info!เว็บพนัน เครดิตฟรี ไม่ต้องฝาก
Sep 06, 2023 08:00:36 PM
Great – I should certainly say I’m impressed with your site. I had no trouble navigating through all tabs as well as related info. The site ended up being truly simple to access. Great job. พนันออนไลน์ เว็บไหนดี pantip
Sep 07, 2023 02:23:03 PM
You could certainly see your skills within the work you write. The sector hopes for more passionate writers such as you who aren’t afraid to mention how they believe. All the time go after your heart. UFABET มือถือ
Sep 07, 2023 05:04:15 PM
BitStarz is Bitcoin - Multi-award Winning Crypto for a reason, as we give players access to the total experience.
website : <a href='https://bs3.direct/b62f8f992'>BitStarz - VIP Starz Club</a>
Sep 07, 2023 05:04:56 PM
BitStarz is Bitcoin - Multi-award Winning Crypto for a reason, as we give players access to the total experience.
website : https://bs3.direct/b62f8f992
Sep 10, 2023 04:16:56 AM
Menin zhana asmr_blogger beinema kosh keldiniz! 3 tamyz menin tugan kunim bolds! Kundi zhakyndarymmen zane old otkizdik, tamaq iship, otyryp, sylyktar aldym ????
website: <a href='https://www.instagram.com/asmr_blogger/'>asmr_blogger</a>
Sep 10, 2023 04:18:22 AM
Menin zhana asmr_blogger beinema kosh keldiniz! 3 tamyz menin tugan kunim bolds! Kundi zhakyndarymmen zane old otkizdik, tamaq iship, otyryp, sylyktar aldym ????
website: [url=https://www.instagram.com/asmr_blogger/]asmr_blogger[/url]
Sep 13, 2023 01:26:49 AM
<a href="https://sakti55boy.com">slot gacor malam ini</a>
<a href="https://sakti55boy.com">agen judi slot</a>
<a href="https://sakti55boy.com">agen slot</a>
<a href="https://sakti55boy.com">Slot Bonus New Member</a>
<a href="https://sakti55boy.com">Slot Bonus Sakti55</a>
<a href="https://sakti55boy.com">sakti55</a>
<a href="https://sakti55boy.com">slot gacor</a>
<a href="https://sakti55boy.com">slot gacor hari ini</a>
<a href="https://sakti55boy.com">situs slot gacor</a>
<a href="https://sakti55boy.com">situs slot gacor terpercaya</a>
Sep 15, 2023 05:49:52 AM
Wonderful article, thanks for putting this together! This is obviously one great post. Thanks for the valuable information and insights you have so provided here.
Sep 23, 2023 06:34:00 PM
Great post, and great website. Thanks for the information!
Sep 23, 2023 06:41:52 PM
I am definitely enjoying your website. You definitely have some great insight and great stories.
Sep 23, 2023 06:47:19 PM
Excellent and very exciting site. Love to watch. Keep Rocking.
Sep 23, 2023 06:55:00 PM
It is a great website.. The Design looks very good.. Keep working like that!.
Sep 23, 2023 07:10:57 PM
The website is looking bit flashy and it catches the visitors eyes. Design is pretty simple and a good user friendly interface.
Sep 23, 2023 07:15:56 PM
Excellent article. Very interesting to read. I really love to read such a nice article. Thanks! keep rocking.
Sep 23, 2023 07:19:42 PM
Pretty good post. I just stumbled upon your blog and wanted to say that I have really enjoyed reading your blog posts. Any way I'll be subscribing to your feed and I hope you post again soon. Big thanks for the useful info.
Sep 23, 2023 07:23:41 PM
Pretty good post. I just stumbled upon your blog and wanted to say that I have really enjoyed reading your blog posts. Any way I'll be subscribing to your feed and I hope you post again soon. Big thanks for the useful info.
Oct 01, 2023 03:16:21 AM
Good post but I was wondering if you could write a litte more on this subject? I’d be very thankful if you could elaborate a little bit further. Appreciate it! gacor323
Oct 01, 2023 05:51:27 PM
The design confidently amazing. These little information are generally fabricated applying massive amount record expertise. I need all this drastically. gacor323
Oct 01, 2023 07:21:17 PM
Photos available on your site even though producing attention rapidly some quantity submits. Satisfying way of long-term long term, I'm going to be book-marking in the period turn out to be your own area complete occurs inch upward inch. gacor323
Oct 02, 2023 12:09:57 AM
Good write-up, I am normal visitor of one’s blog, maintain up the nice operate, and It is going to be a regular visitor for a long time. .Séjours en Grece gacor323
Oct 02, 2023 11:36:53 PM
You made some decent points there. I seemed on the internet for the problem and found most people will associate with with your website. imr 4831
Oct 03, 2023 04:46:25 PM
Now i am attracted to people write-up. It can be best to locate persons verbalize within the cardiovascular system together with realizing in such a major topic is frequently purely observed. فتح سجل تجاري في دبي
Oct 04, 2023 07:17:57 PM
Excellent article. Very interesting to read. I really love to read such a nice article. Thanks! keep rocking. JOGO DO TIGRE
Oct 05, 2023 12:08:57 AM
This is very informative blog. Keep it up and visit us <a href="https://coolshitwholesale.ca/blog/f/red-deers-wholesale-fire-resistant-clothing-hub-cool-shit-whole">Wholesale Fire Resistant Clothing</a> for more details.
Oct 05, 2023 03:37:29 AM
Interesting and amazing how your post is! It Is Useful and helpful for me That I like it very much, and I am looking forward to Hearing from your next.. spbo
Oct 06, 2023 08:01:19 PM
The idea thinks fully correct. Most of smaller sized features ended up made by way of a lot of file education and learning. I adore the approval a great deal. UFABETดีมั้ย
Oct 07, 2023 10:52:35 PM
Aw, this became an exceptionally nice post. In idea I must put in writing in this way additionally – taking time and actual effort to make a very good article… but what can I say… I procrastinate alot and also by no means appear to go done. UFABETฟรีเครดิต ยังไง
Oct 08, 2023 01:43:20 AM
I truly appreciate this post. I¡¦ve been looking everywhere for this! Thank goodness I found it on Bing. You’ve made my day! Thanks again Pristina Travel UFABETเว็บแทงบอล2023
Oct 08, 2023 04:21:41 AM
Thanks for taking the time to discuss this, I feel strongly about it and love learning more on this topic. asianbandar
Oct 09, 2023 01:07:14 PM
I think this is among the most significant info for me. And i am glad reading your article. But want to remark on few general things, The web site style is great, the articles is really excellent : D. Good job, cheers LiveGood
Oct 10, 2023 07:38:29 PM
Following analyze several of the website content on your own internet site now, and I in fact like your way of running a blog. I book marked that to be able to my save web site listing and can be examining back again shortly. Please attempt my own website as effectively as well as let me know what you believe. voyage blog
Oct 11, 2023 03:23:37 AM
hello!,I like your writing very much! share we communicate more about your post on AOL? I require a specialist on this area to solve my problem. May be that’s you! Looking forward to see you. Tonstudio Telefonansagen
Oct 11, 2023 07:20:42 PM
I really like what you guys are up too. This sort of clever work and coverage! Keep up the very good works guys I’ve included you guys to my own blogroll. trek sapa
Oct 12, 2023 02:45:40 AM
Hey, you used to write magnificent, but the last several posts have been kinda boring… I miss your tremendous writings. Past several posts are just a little out of track! come on! best ai writers
Oct 13, 2023 04:44:50 PM
Joker81 merupakan situs slot bonus new member 100 terpercaya nomor 1 di Indonesia. Sebagai salah satu situs agen slot online terbaik dan terpercaya, kami menyediakan banyak jenis variasi permainan yang bisa Anda nikmati. Semua permainan juga bisa dimainkan cukup dengan memakai 1 user-ID saja. Joker81 sendiri telah dikenal sebagai situs slot tergacor dan terpercaya di Indonesia. Dimana kami sebagai situs slot online terbaik juga memiliki pelayanan customer service 24 jam yang selalu siap sedia dalam membantu para member.
LINK DAFTAR: <a href="https://quinnnftjoker81.com/">quinnnftjoker81.com</a>
Oct 14, 2023 06:20:28 PM
I wanted to thank you for this excellent and very effective backlinks! Thank you so much for this.
Oct 16, 2023 07:48:00 PM
There are a ton exposition web sites by means of the web when you search for of course recorded as a feature of your article.
Oct 18, 2023 03:28:34 AM
Thank you for yet another great informative article, I’m a loyal visitor to this blog and I can’t stress enough how much valuable tips I’ve learned from reading your content. I really appreciate all the hard work you put into this great site. cebu kawasan falls
Oct 18, 2023 07:32:20 PM
Hey there! Someone in my Facebook group shared this website with us so I came to check it out. I’m definitely enjoying the information. I’m book-marking and will be tweeting this to my followers! Superb blog and wonderful design. forexcryptoltd.com
Oct 18, 2023 08:59:29 PM
This is such an incredible asset that you are giving and you offer it free of charge. I love seeing online journal that comprehend the benefit of giving a quality asset to free. <a href="https://cnnupdate.com/how-to-plan-a-trip-on-a-budget/ ">How to Plan a Trip on a Budget</a>
Oct 18, 2023 09:03:23 PM
I might want to pass on my appreciation for your liberality on the side of people that have the requirement for assist with this specific concern. Your exceptional commitment to receiving the message all over had been magnificently useful and have constantly made experts similar as me to accomplish their fantasies. Your own significant instructional exercise implies an incredible arrangement to me and furthermore to my office laborers. Much thanks to you; from everybody of us.
Oct 21, 2023 06:17:25 PM
Hello! I would choose to offer a massive thumbs up for your excellent information you may have here about this post. I will be returning to your website for more soon. บาคาร่าเว็บไหนดี2022
Oct 22, 2023 09:19:41 PM
Locate which will article writing is not actually valued at the time period, you might recognise that discovering them free of charge is really a lot a great deal more an individual’s idea! Precisely why craft content articles together with throw away your time and energy when you are able become terrific content absolutely free! A lot of people discover utilizing just a dash of effort paid out diving the web page and looking at what’s going on they is able to leave and reveal a whole lot of function done with the particular means available. Moringa extract
Oct 23, 2023 05:43:29 PM
Hello. Cool article. There's an issue with your site in chrome, and you might need to really look at this... The program is the market chief and a gigantic part of others will overlook your great composing as a result of this issue.
Oct 26, 2023 02:02:33 PM
Much obliged, that was a truly cool perused!
Oct 30, 2023 05:00:36 PM
Following analyze several of the website content on your own internet site now, and I in fact like your way of running a blog. I book marked that to be able to my save web site listing and can be examining back again shortly. Please attempt my own website as effectively as well as let me know what you believe. chauffeur
Nov 06, 2023 05:39:35 AM
Hmm it appears like your website ate my first comment (it was super long) so I guess I'll just sum it up what I had written and say, I'm thoroughly enjoying your blog. I as well am an aspiring blog blogger but I'm still new to everything. Do you have any points for novice blog writers? I'd certainly appreciate it.
Nov 08, 2023 06:31:15 PM
To see got with your web site on the other hand location treatment method clearly a very little amount of submits. Flexible technique for likely foreseeable future, I am book-marking at a stretch safeguarded options halt springs up in concert. https://scgforex.com/the-benefits-of-blockchain-technology/
Nov 09, 2023 04:52:04 PM
i read a lot of stuff and i found that the way of writing to clearifing that exactly want to say was very good so i am impressed and ilike to come again in future.. plagiarism checker unlimited words
Nov 12, 2023 02:41:01 PM
You have noted very interesting points ! ps nice internet site .
Nov 13, 2023 04:50:36 PM
You have a good point here!I totally agree with what you have said!!Thanks for sharing your views...hope more people will read this article!!!
Nov 16, 2023 09:58:04 PM
I discovered your blog website on google and check a number of your early posts. Always keep the really good operate. I recently additional the Rss to my MSN News Reader. Seeking forward to reading far more of your stuff later on!… BK8
Nov 17, 2023 10:38:01 PM
Hey, you used to write wonderful, but the last few posts have been kinda boring… I miss your tremendous writings. Past few posts are just a little out of track! come on!
Nov 18, 2023 12:42:14 AM
Nearly everything seems to jump off the screen, but at the same time the film doesn’t really have any standout moments where the effect is utilized in a way that really wows its audience. 79 thể thao
Nov 18, 2023 07:00:51 PM
Thankyou for sharing the data which is beneficial for me and others likewise to see. daikin
Nov 21, 2023 04:57:24 PM
Get daily teer result, shillong teer result, khanapara teer result, teer result common number daily success live teer result here. shillong teer result
Nov 21, 2023 10:05:16 PM
Discover the exquisite Feather Juju Hat, a remarkable African headpiece available at Juju Hat World. We offer the finest selection of affordable juju hats, ensuring that all your desires for this unique accessory are met in one convenient place.
Nov 22, 2023 03:54:23 PM
i hope that it assists because it helps me alot.. ..and occasionally even when i have writers block and i am doing some thing else to take my mind off of my composing, i come across a time when i Wish to create more of my story simply because i guess my writer’s block is cured, so occasionally the correct time comes to you, i guess sometimes all u have to do is wait.. ...i know i dont make sence but try obtaining watever u can from my answer and see if it works!! tylebongda.ink
Nov 22, 2023 10:05:04 PM
I am glad you take pride in what you write. This makes you stand way out from many other writers that push poorly written content.
Dec 04, 2023 04:16:14 PM
There is noticeably a lot of money to learn about this. I suppose you’ve made certain nice points in functions also. bong88 casino
Dec 07, 2023 06:16:42 PM
Boosting Performance Improvement Program | FDBK HQ
Let us train you to optimize your performance at its peak & empowering. Our performance improvement program is built to enhance results.
Dec 28, 2023 12:33:28 AM
I must say, as a lot as I enjoyed reading what you had to say, I couldnt help but lose interest after a while. Its as if you had a wonderful grasp on the subject matter, but you forgot to include your readers. Perhaps you should think about this from far more than one angle. Or maybe you shouldnt generalise so considerably. Its better if you think about what others may have to say instead of just going for a gut reaction to the subject. Think about adjusting your own believed process and giving others who may read this the benefit of the doubt.
Jan 03, 2024 10:45:20 AM
Depression in some human beings, looking for treatment opportunities for their melancholy is an attempt to avoid medicine, or it is able to be a part of the individual’s preference for herbal remedies
Jan 09, 2024 10:45:15 PM
Thanks for sharing an awesome detailed blog
keep it up and visit us
<a href="https://aspsrenovationsltd.com/services/painting-services/">Best painting renovation services</a>
Jan 26, 2024 09:05:26 PM
This is a great post. I like this topic.This site has lots of advantage.I found many interesting things from this site. It helps me in many ways.Thanks for posting this again.
May 09, 2024 07:48:29 PM
Live Exams Helper | Your ultimate resource for online live exams. Effortlessly excel in your tests with our comprehensive support and guidance.
<a href="https://liveexamshelper.com/">https://liveexamshelper.com/</a>
<a href="https://liveexamshelper.com/">https://liveexamshelper.com/advance-management-accounting/</a>
<a href="https://liveexamshelper.com/">https://liveexamshelper.com/advanced-financial-accounting-and-corporate-reporting/</a>
<a href="https://liveexamshelper.com/">https://liveexamshelper.com/basic-accounting/</a>
<a href="https://liveexamshelper.com/">https://liveexamshelper.com/corporate-accounting/</a>
<a href="https://liveexamshelper.com/">https://liveexamshelper.com/corporate-reporting/</a>
<a href="https://liveexamshelper.com/">https://liveexamshelper.com/cost-accounting/</a>
<a href="https://liveexamshelper.com/">https://liveexamshelper.com/cost-and-management-accounting/</a>
May 16, 2024 08:15:03 PM
Thank you very much for the sharing! COOL..
Aug 22, 2024 07:40:43 PM
You made some respectable points there. I looked on the internet for the issue and found most people will go along with with your website. 實發體育
Aug 28, 2024 09:13:52 PM
I read a article under the same title some time ago, but this articles quality is much, much better. How you do this..
Sep 02, 2024 01:10:23 AM
Would you care if I quote several your posts as long as I give credit and sources back to your site? My blog is in precisely the same area of interest as yours and my guests would genuinely profit from a portion of the data you give here. If it's not too much trouble, let me know as to whether this alright with you. Much obliged! 相続登記
Sep 10, 2024 04:07:54 PM
Some truly wonderful work on behalf of the owner of this internet site , perfectly great articles .
Oct 26, 2024 04:30:21 AM
I am glad you take pride in what you write. This makes you stand way out from many other writers that push poorly written content.
Oct 12, 2025 08:45:30 PM
이것은 말 그대로 휴대폰 소액결제 서비스를 통해 얻은 상품이나 상품권을 현금으로 바꾸는 것을 의미합니다. 예를 들어 휴대폰 소액결제 한도로 문화상품권, 구글 기프트
Oct 12, 2025 08:46:20 PM
이것은 말 그대로 휴대폰 소액결제 서비스를 통해 얻은 상품이나 상품권을 현금으로 바꾸는 것을 의미합니다. 예를 들어 휴대폰 소액결제 한도로 문화상품권, 구글 기프트
Oct 25, 2025 02:15:48 PM
“Thank you for sharing how your community comes together and serves one another
Nov 06, 2025 05:45:09 PM
Accessing Rajabandot login alternatif on my mobile device is surprisingly smooth. Sometimes the main link struggles on mobile browsers, but the alternative link ensures I can play my favorite games anywhere. For anyone who enjoys gambling on the go, this feature is a huge plus.
Feb 18, 2026 05:08:16 PM
It can be as well a considerable position i incredibly savored surfing around. Isn't really day by day that supply the candidate to watch a specific thing.